文档说明
本文档下面的所有内容,是我自2022年4月从华为离职之后,整整一年多的技术思考和探索的过程,这部分不是完整的文档,大部分都是以笔记的形式记载,所以存在不连贯,甚至有些内容我认为太简单以至于不需要记录的时候,这部分甚至都没有内容。
但我仍然把这些内容放在这里,是因为我觉得它对于想深入学习Reality World背后思想的朋友有学习价值
本文的Markdown统计大概有20万字。
1. Introduction
游戏,作为一种模拟真实世界实时运行的系统和机制,它不光在产品形态上跟一般的应用程序体验不一样,例如一般应用程序一般是功能型的,其功能是明确而具体的,而游戏往往是一种体验,没有直观确定性的功能,每个人获得的体验可能都不一样,它的整个程序组织及其开发工具更是与传统的应用程序不一样,例如传统的应用程序通常是按顺序执行,而游戏为了实现对真实实时世界的模拟,需要以一种不间断的实时轮询的机制。这种轮询不光造就了游戏中各个动态系统的实时性,它对整个应用程序的架构,以及这种应用程序的表达能力,都提供了非常不一样的可能性和结果。
多年来,这种应用程序机制主要被用来制作游戏,而游戏这种程序机制的一些难点,通常需要非常专业的游戏公司才能做出不错的游戏产品。而反观传统的应用程序,由于它们的机制更简单,易于学习和理解,因此被更广泛的使用,不仅对人们的生活带来更大的影响,也大大地促进了社会进步。
近年来,随着虚拟现实和元宇宙概念和趋势的兴起,这种实时模拟系统越来越频繁被用于到游戏之外更泛化的领域,例如:
- 通过手机的AR功能,Snapchat给用户提供了丰富的滤镜体验,不同于传统视频和图片,这些滤镜是交互式的,用户可以基于这种交互能力生成还富有表达能力的视频,借助这种能力,Snapchat迅速称为一款流行的社交应用。
- 同样是基于手机AR的功能,Niantic借助手机后置摄像头的视觉定位能力(VPS),开发了诸如Pokemon Go等应用,这种新的基于真实地理位置的应用跟人们在真实世界中的活动联系起来,并借助3D互动的能力,把人们的生活联系得更紧密,是一款典型用于增强社交关系的应用。
- 以Roblox为首的创作类工具,通过简化程序分发和部署、提供统一的多人在线等服务,降低了游戏开发的门槛,使得更多的中小个人创作互动内容更加简单。并通过云原生的多人在线,使社交游戏的效果被放大,成为未来的重要趋势。
- 由类Minecraft沙盒机制延伸的大逃杀沙盒游戏《堡垒之夜》,借助更好的多人在线服务,例如包括对多人实时游戏更友好的在线语音服务等,使得社交属性在《堡垒之夜》被进一步加强。更好的多人在线服务以及堡垒之夜本身逃生类游戏更好地协同机制,使得堡垒之夜的社交属性称为体验最好的社交属性,其开创和举办的虚拟派对Marshmello更是掀起了虚拟演唱会的热潮。
所有这些变化和发展,对互动内容的开发及生态都带来了巨大的影响和变化,这些影响和变化后面,需要全新的技术范式,而这些新的技术范式又将创造增量的价值和体验。
1.1 变革
1.1.1 形态变化
上述这些变化,从上往下看,可以归结为三个维度的变化:
- 开发者:由专业开发者向普通用户转移
- 开发方式:互动内容的开发方式由完全开发到基于事件驱动开发
- 玩家体验,由完全操控到XR辅助
在开发工具方面,Roblox和Snapchat的Lens Studio都面向普通开发者,它们共同的特点包括简化的脚本,以及一键发布,使得开发者 不需要花费很大的精力去处理平台相关问题。另一方面是这类工具都是深入集成平台的特定功能,例如Lens Studio底层的AR场景理解算法,以及Roblox内置的多人在线服务。深度集成平台与算法,相比于传统通用游戏引擎,将成为未来的一个方向和优势。
在开发方式方面,传统的流程需要开发者定义所有的逻辑,包括触发逻辑的机制,这部分尤其复杂。在Snapchat基于AR的互动内容开发中,这类互动内容的驱动完全来源于手机对场景理解,这些都由AR算法来提供,因此开发者不需要处理任何交互驱动方面的逻辑,而只需要关系对交互的响应逻辑。这种方式不仅大大简化了整个互动内容的开发,也从根本上对互动内容开发的流程带来了很大的变革。简化逻辑开发的触发机制,触发机制数据化,深度与平台集成,是未来互动内容开发走向平民化的重要方式 之一。当然在这个过程中,基于代理的物体位置摆放机制也起到了很大的辅助作用。
同样借助与事件触发机制的数据化,以及基于XR设备对场景的理解,用户对互动内容的部分操作,由原来主动、精细地控制虚拟摄像机和物体,变为基于场景理解算法的自动驱动,这大大简化了交互成本。
这些各个层面的变化,最终都会导致整个互动内容的制作流程会发生较大的变化。
1.1.2 计算架构的变化
从开发的角度,从下往上看,这带来的是计算架构的变革。
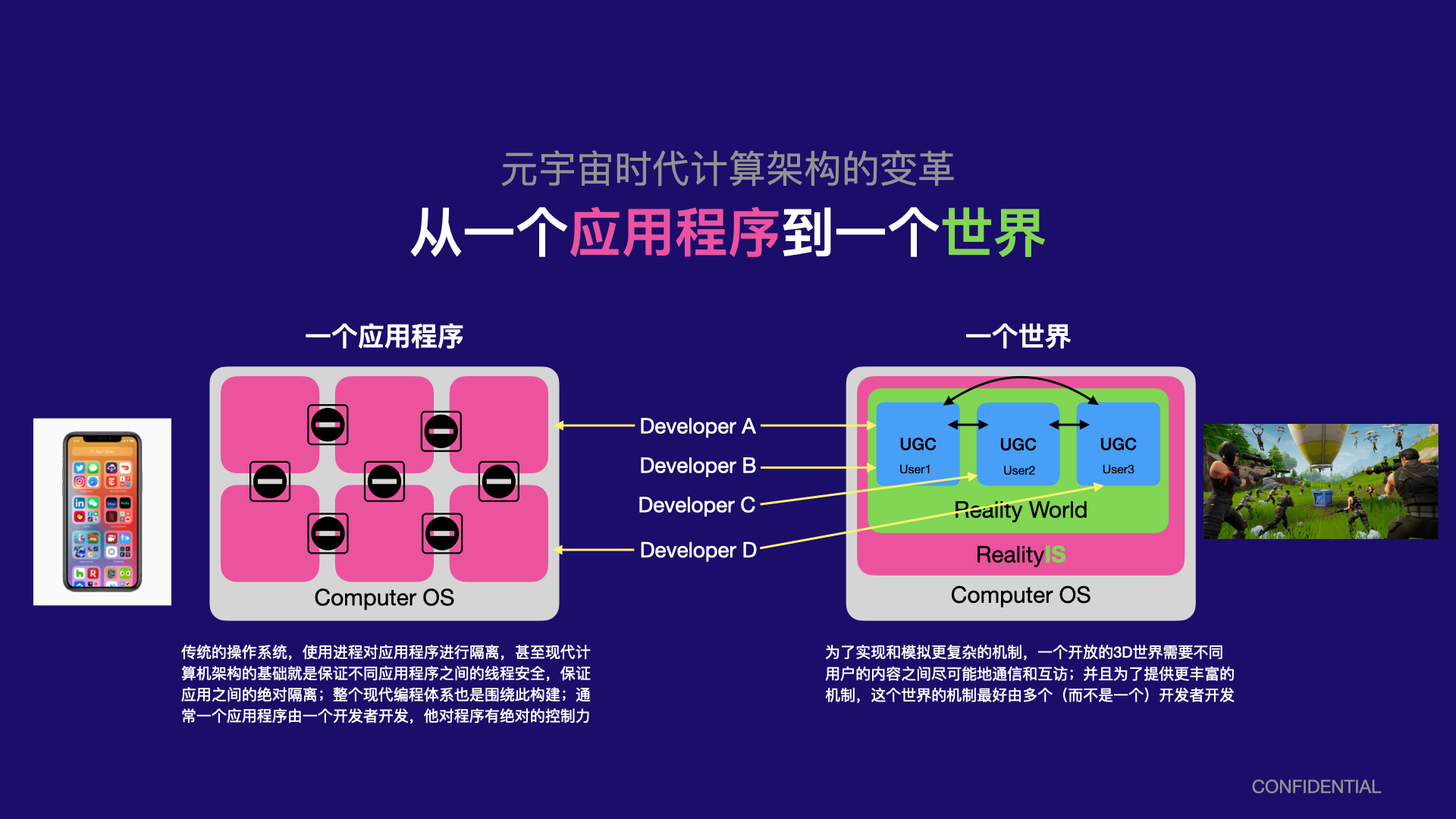
传统的计算架构都是为单个应用程序设计的,从硬件到软件,所有一切流程和功能都是针对这个模型设计的,例如一个应用程序的所有源码都会被编译和链接到一起,一个应用程序内的数据可能相互引用,所有需要链接器来重新定位每个引用变量的地址。这样的计算架构,非常适合于处理具有独立功能的应用程序。但它有比较致命的缺点:
- 例如因为所有源代码编译的目标代码都会链接到一起,所以它们从根本上就不支持大规模应用程序,因为这样的应用程序可能由海量的源代码组成。
- 由于源代码之间相互引用,因此它们很难支持应用程序内的独立子程序通信,子程序之间总是需要引用源代码才可以通信,这使得一个应用程序无法成为一个可以自我进化的开放系统,而总是需要一个开发商来进行维护
随着UGC和元宇宙时代的到来,这种大规模的、具有内生开放子系统的多应用交互架构越来越成为最核心的需求,这需要我们在计算架构上做出较大的变革。
1.1.2.1 业务比喻
比如现在腾讯有非常海量的业务,比如微信,音乐,视频等,目前这些业务之间相互是比较独立的,他们组织为相互独立的应用程序,相互比较独立的数据管理,服务器架构和组织,虽然彼此之间存在一定关联,但是这种关联是高度结构化和规则化的,且关联很少。
开放世界则意味着,现在所有这些业务需要在一个应用内组织,它的复杂度是非常高的,架构也非常复杂,数据管理和分布式计算都非常复杂,并且由于传统游戏的逻辑组织方式,在这种体量下根本无法有效管理组织和进行分布式计算
可行的思路:
- 微服务化
- 函数式编程
微服务化是一种软件架构,需要高度依赖于对逻辑的设计和划分,他不是一种基础编程模型,因此无法支撑开放式的设计,这些微服务通常都只能是开发商设计好的,普通用户没法修改,因此本质上不支持开放世界。
1.1.3 技术挑战
从根本上,上述的一些变革带来的技术挑战包括:
- 需要全新支持多应用相互通信的计算架构
- 能够在所有计算轻松在多个服务器之间进行分布式计算的数据和计算架构
当然由这两个底层根本性的挑战,上层还包括一些其他挑战,比如独立程序之间高效的通信标准或者机制,用户对权限控制与代码的分离,普通用户怎样无代码编程等等,我们将在后面进一步分析。
1.2 现状
不能随时随地高效的内容创建,与随时随地方便的将创建的内容进行社交分享,是当前最大的问题,或者说是3D数字世界发展的一些重要基础;前者的难点在于它需要编程(通常需要面向对象的编程能力),所有逻辑都是通过面向对象的方式创建出来的(大部分人都不具备);而后者的难点在于它需要一套新的支持分布式协同编辑和分发的底层数据格式表述,这与当前大部分引擎私有格式都不一样
1、主要基于场景理解
当前大部分AR应用都是基于场景理解的简单特效/滤镜呈现,以及围绕这些滤镜非常简单的交互,没有围绕场景构建做太多事情,即堡垒之夜的方式,包括更复杂的交互
2、3D内容分发
当前大部分不能分发3D内容本身,而是分享录制的视频;或者只是分享相同的滤镜给朋友,使用体验没有差异性
3、用户创建参与感很弱
绝大部分都是场景理解驱动,仅有纯视觉的体验,没有3D真正复杂的交互和创建体验
4、大部分聚焦虚拟空间
元宇宙即社交方向行业大部分在做虚拟空间:元象、RecRoom、monoAI等
5、3D创建的价值/Minecraft
除了精心的游戏规则设计(这需要很高的开发技巧和能力),3D内容的创建本身也是很有乐趣的,而能够创建自己设计的一定规则的内容就更有趣
大部分没有集中于面向普通用户创建3D内容的能力或体验,Roblox 面向有一定经验的开发者,并且开发模式本质上与传统游戏开发类似,只是分发机制不一样,NV和太极面向用户创作,但是没有面向移动端,而且是纯内容创作
6、底层创新
当前普遍聚焦上层架构,围绕怎样将传统游戏的流程和体验往元宇宙上靠,其结果大多数虚拟空间类产品,聚焦底层协作的主要是Omniverse和太极,其中深入底层性能的只有太极,但在中间层上下协同方面缺乏重点创新,其中太极和元象都在主打云渲染,太极还强调在线协同编辑,Omniverse则支持一般的协同编辑
7、虚拟空间也主要是纯视觉体验
大部分只是在里面行走,不能做太多事情,更不能创作,或者有的也是固定规则的交互,例如Roblox 里面的一些模拟经验的游戏
8、游戏更新的时间
一般需要重新发布的流程,Ubisoft Scalar试图通过云端微服务架构实现及时更新,另外云原生基本上天生就是及时更新的,因为它的资源都在云端
1.3 技术优势
1.3.1 无代码交互内容创作
现在大部分应用都是在设计一个特定场景,提供官方特定的应用、规则或玩法,跟游戏的思路类似,更强调用户的体验
除了游戏引擎,能让用户创作的只有Roblox 只类型的
能够面向普通用户,且针对交互内容进行创作的,只有一家,它是未来最基础的模式和能力,当前没有一家在这个层面,独此一家
用户可以基于RealityWorld 创作游戏,或者简单的作品,跟Roblox 一样,但是它通过两个门槛以及丰富创作的类别,让更多普通用户可以参与,从而大大增加用户群,使得开发者在这个平台上开发游戏有可能具有更大的用户群
1.3.2 代码复用机制
CreationXR runtime,可以被任意第三方app集成
他颠覆了传统开发者生态的方式,传统的小程序或者Roblox 或者Snapchat 只能集中式,只有平台一个入口,而像Niantic 这种仅开放底层能力:
- 开发者接入实际很困难,因为要调用众多的API
- 每个app接入的方式存在冗余,重复,这部分可以共享
- 每个app接入的方式不一样,因此每个app开发的功能本质上类似,但是3D部份却要重复开发,例如要接入预览流等等
- 无法在自己的app里面共享一套开发标准,Unity不算标准,因为他更偏低层,没有定义太多规范,导致每个人开发不一样,而RealityCreate 是高度规范化的
这使得第三方开发者可以共享RealityCreate 高度规范化的流程,又可以最简单的成本和方式接入自己app,从而是开发者聚焦创作本身,同时能享受云原生,用户协作等等所有Creation XR得好处
这样也可以避免in-house 引擎的问题,in-house 引擎主要的问题是不能被其他app简单使用,有固定的流程,这样:
- 既可以按照in-house 的做法快速提升自己的差异性,而避免陷入Unreal和Unity 那样的通用引擎
- 又能像Unity一样被用于开发独立应用
- 还抓住了生态
这种模式还有一个好处,除了应用部署本身,他还提供如应用的统计分析等功能,应用的存储,这些原本都是要开发者自己去对接的,传统的应用开发看有多么复杂:
- 开发者自己自己Unity开发app程序,其中包括大量的美术资源和逻辑开发是每个游戏开发者比较重复的
- 自己打包部署,这要求一些平台层的技巧和经验,这些其实超出了开发者对内容的聚焦,除了内容和玩法,一个游戏创业公司还需要花很多资源
- 然后还需要对接各种SDK,包括端侧的和云侧的,而各种SDK都要公司自己学习,并且不同公司之间这些工作也是重复的,但是每个公司都的招人去挖坑,有时候这些反而成为一些小团队比较阻碍发布的一些障碍
- 后期的运维也需要一些精力和人力也自己开发经验的投入
总之,游戏开发团队花了较多的精力在一些繁琐的事情上,而且公司之间的这些能力本可以共享的,开发者本应该聚焦内容开发
原因是因为开发者要自己发布app,所以没有办法去统一集成一些东西,这些东西本身没有标准,很难统一
当然大的应用本身需要更灵活的能力,有太多限制反而不利于开发,但是对于一些小内容,尤其是个人内容,这是可行的,而且个人开发者需要这样的生态
Roblox 就是做了这些事情,应用开发者不需要担心其他事情,但:
- 它不支持Roblox之外的分发
- 它不支持链接的方式分享
- 编程模型不一样
- 主要面向PC和手机,没有针对XR的算法层接口封装
- 编程模型不一样所以不可能支持XR设备创作
- 还是典型的专业开发+普通用户玩的模式,没有普通用户的创建模式和创造体验
以此为基础,构建微服务架构
美术资源的重复问题
- 传统互动内容最重要的是玩法、故事,美术相对不是最核心的
- 美术资源能够提供独特的视觉语言,但是这些视觉语言更多是风格化的类型,例如在同一种写实风格类型下,玩家对不同的场景感知的差异就会小很多
- 美术场景通过程序化生成方法是能提供较好的差异性和独特性的
- 如果这种程序化方法更加支持风格化,那么就能满足上述的需求
- 风格化主要表现为纹理或者基础材质,有时网格也有一定的差异,但是这都可以进行研究
1.3.3 高性能、低功耗
现代游戏程序通常基于OOP进行开发,其中的引用关系错综复杂,对现代内存硬件架构极度不友好,需要重新对游戏的运行时内存数据进行更好的管理,并且这些管理又不能给开发者带来成本。
参见2.3.1节。
1.3.4 大规模并发、分布式
基于上述相似的原因,现代游戏程序无法使用大规模并发的需求,例如单台服务器最多只能支持上百人同时在线。这主要是游戏程序内的程序和数据耦合度非常高,导致单台服务器必须加载所有的数据,这样的方式不管单台服务器的内存不够,也会带来多台服务器重复加载,以及重复加载导致的数据同步导致的复杂问题。
参见2.2.13节。
1.3.4 自我进化的标准架构
在一个传统的游戏程序中,所有的逻辑都是包含在程序中不可修改,所有的关卡、剧情等等都是固定的,跟电影比较类似,唯一不同的可能是游戏具有交互性。
当需要更新程序时,通常通过DLC或Mod等机制对游戏进行扩展或增强,但是这两种机制通常都比较受限,因此本质上,至少一个已经发布的游戏其核心体验是很难改变的。
但一个开放的Metaverse不仅需要可以任意添加独立程序的能力,还需要能够像真实世界一样自动筛选优秀内容的能力,否则用户可能很快就沉入很多垃圾或者质量较低的信息当中。
传统的数字经济,这种内容都是需要平台使用一定的算法进行推荐,这种推荐算法一般由用户对自己的内容设置一些标签,然后平台建立一些相关度的机制。
但真实世界却是相反的,它们由每个根据自己的判断和选择,来促进整个世界的进化。参见4.12节内容。
1.4 商业模式
1.4.1 加强朋友间在线互动的最好形式
传统的在线互动有三种形式:
- 视频电话
- 多人在线游戏,如《刺激战场》
- 《Roblox》类的虚拟房间
其中游戏类的多人在线,还是以游戏为主,这些交互通常只是聊天或者语音,有点像在现场一起玩游戏大家可以相互讨论;整体的活动还是以玩游戏为主,互动是辅助的形式。
房间类的交互,相对私密一点,但是这些应用的游戏性往往很弱,比较局限于形式上的在线互动,目的性和娱乐性都不够强。
Reality World相对上述的模式,存在一下的一些独特区别:
- 互动的规则和内容往往是可以由其中一个用户创作的,具有独特性,针对性,比如针对一个生日专门设置的与朋友相关的场景和互动内容;这种独特性使得Reality World的内容更容易在好友之间发起互动
- 可以在互动的过程中进行共同创作,比如你向蛋糕上切一刀下去,所有人都可以看到蛋糕被切成两份,这是因为Reality World的场景多人协作特性,而其他互动的内容是固定的,每个玩家只能体验这些设计好的内容
- Reality World的内容可以即使创作和分享,不需要提交到商店,然后用户下载,只需要马上创作之后发送给好友一个链接就可以及时打开
1.4.2 理想的广告-新型虚拟经济体验
在现代数字经济中,除了视频、图片和音乐这种能直接体验的数字内容,其他的大部分内容,其实体和对应的数字表述都是分割的,例如淘宝都买的商品只是数字化后的一个记录,你必须收到东西之后才能体验。
另一种与之相关的数字经济是广告,广告作为一个展示产品的方式,在真实世界中,它们往往以视频或者图片的形式呈现。然而在这种方式中,广告语产品通常是割裂的,受限于实物需要场地及运输等问题,我们并不能总是在任意一个广告旁边放上实物,使得任何看到广告的人就可以购买。
然而,对于后者才是理想的广告形态:就是广告本身就是产品,或者说广告可以一键直达产品体验和购买。
1.4.2.1 广告本身就是产品
如果广告的产品就是数字内容,而非实体内容,理论上是可以做到这种一键体验的效果的。比如如果产品是一个游戏或者一个应用程序,就可以直接点击下载,这种形式现在很普遍。然而这种方式并不是最好的模式,因为:
- 所有的产品都得开发一个app
- 用户可能并不想要安装那么多app
- 因为每个app安装除了体验产品还有很多额外的负担:注册,登录,进去了解软件的导航功能等等
所以元宇宙是一个更好的广告平台,每个产品只需要设计一个交互,玩家直接体验一下就是。但是现在的技术并不能做到这种体验,这里面的原因:
- 一是平台无法支撑任何开发者自由开发交互内容,往往只能通过平台发布,这样广告能力很受限
- 即使增加了新功能,也需要所有玩家都更新,有时候一个广告只有少数人有体验需求
总之,Reality World可以做到厂商可以任意发布带有交互的广告,然后任何玩家只要看到它,就可以及时体验和购买,真正做到:产品及广告,广告及产品,这种模式有望重塑一个全新的虚拟经济形式。
如果广告的内容是实体内容,仍然可以虚拟化体验,或者通过交互,相比视频和图片更好的了解产品。
见4.6.3节内容。
1.4.3 真正的“市场经济”
即市场会决定哪些东西更有价值,这是与传统数字经济系统根本性的不同,传统的数字经济都需要由平台实现某种推荐或者排序算法,例如微博的信息,知乎的文章,淘宝的商品,抖音的视频,这就要求基于一定的标签,分类等机制,信息发布者需要去维护这种标签分类。
然而真实世界的经济却不是这样的,我们所有的一切不是由类似国家或中央的官方机构决定的,而是靠人们自己的选择,促进整个世界的运转。
类似真实世界公司之间的销售,产品越好卖的越多,售价也可以随市场调整。
而且这种机制促进作品的不断改进,就是iPhone手机一样,而传统的内容都是一次性发布,缺乏对原产品的改进机会。游戏也一般由于太复杂,发布后不会有大的改进。目前这些数字经济跟真实世界的经济都不一样。
可以认为它们都是“结构化”的经济,而不是市场经济。
真正的市场经济会促使和催生更多的好内容,更多的人参与。而传统的数字经济,都是少数人在参与或获利。
在真实生活中,每个人都在参与经济贡献;而在目前的自媒体时代,只有少数人在参与经济贡献,大部分都是消费者。
这有机会使得整个经济系统的活力更大:传统的数字化经济都是靠阅读量类似不准确的机制,在这种机制下创作者倾向于作弊买量,而不是创作更好的内容。此外,阅读量本身是个不准确的度量,例如用户可能只是打开了页面就关闭了,根本就没有深入了解对应的内容。而这种通过“实际使用”而不是“查看页面”转化而来对产品的经济定义,更容易促进用户进行更好的创作,就像真实世界一样。见4.3节更多描述。
1.4.4 以标准和组件为核心的抽成机制
传统的NFT类的数字交易市场,交易的是一个数字内容,是一个拷贝,这个拷贝除非通过一定的手段跟踪转售记录,或者甚至限制转售,很难保证创作者的权益。
而Reality World交易的主要是组件和标准,这些组件和标准并不会拷贝一份,而只是一个引用,然后运行时动态从源头拉取最新代码。所以他天生就可以保证了解使用者的情况,比如一个标准能够追踪到所有使用其标准的组件,也能够追踪到所有使用这些标准的用户。
这样标准开发者不能能够收取所有使用者的费用,并且还有很好的更新机制,通知用户购买相关和最新产品,就像真实世界一样。
1.4.5 持续消费
传统的数字化进程中,数字化产品往往是一次性消费,这导致:
- 软件开发者升级动力不大,对创新及创新的速度是极为不利的,因为新用户会越来越少
- 大量陈旧代码,一方面是平台兼容成本高,一方面是用户使用比较陈旧的技术或体验
需要改变这种局面,才能更大地激活数字消费。
参见4.12.4.3节内容。
1.5 用户
Reality World平台有四种类型的用户,当然这里只从创作层面区分,不涉及商业方面的分类或者逻辑:
- 普通用户:类似于抖音平台只观看视频,从来没有或者很少发布内容的用户
- 创作用户:指只在XR设备上,不借助PC编辑器的情况下进行内容创作
- 开发者:使用PC编辑器Reality Create基于标准进行组件开发
- 标准作者:基于对现实世界的理解提出某种抽象,并将其转换为标准,以及持续维护标准的更新
1.5.1 普通用户
尽管普通用户不进行任何形式的创作,但TA仍然是整个经济系统中很重要的一部分,例如:
- TA都其他创作内容的使用和体验产生消费
- TA通过私人社交网络,产生的对好的内容的主动推荐行为,促进了整个市场经济
当然所有人都是普通用户,并且普通用户也有可能转换为其他创作用户。
1.5.2 创作用户
平台很大一部分技术的架构都是为了创作用户,这是区别其他类似平台的关键。
传统面向普通用户的创作有两类主流方式:
- 《堡垒之夜》之类的沙盒游戏,在这类游戏中,整个世界的规则类型比较一致,比如《堡垒之夜》的堡垒建造与逃生,《我的世界》中的怪物机制等,这些机制内置于系统中,平台提供大量具有固定行为的物件,玩家创作的自由度相对较小:基本上不涉及逻辑本身的构造,只有跟物理位置,物体组合等相关与游戏行为无关的策略
- AR事件驱动的增强现实体验,这些应用以《Snapchat》为代表,它提供一些固定的具有互动体验的道具或者滤镜,用户借助摄像机进行体验;这种体验本身不涉及3D的创作,例如制作一个新的滤镜或者一种新的体验,但是它们产生了一个独一无二的视频内容,并且这个内容是跟自己高度相关的。
《Snapchat》的模板只能在PC端制作,《Reality World》则可以及时创作《Snapchat》类似的模板,并且可以选择更丰富的功能组合。
为此,《Reality World》需要支持任意的组件使用,组件之间可以任意协作,这样才能不限制创作,不然就会很容易局限于一个特定的组件包,或者一些特定的互动类型,任意组件之间可以通信和组合是Reality World独特的功能,它能够释放创作者无限的创意。
XR设备上的创作用户必须购买资源,因为他们只能基于已有的资源进行创作,当然有一些资源包或者组件是帮助程序化生成内容的,这类组件可以生成一些随机不固定的内容。资源的类型包括:
- 静态资源:模型(如树木、汽车、弓箭等)、纹理、粒子特效、动画等,Reality World官方应该提供较多的基础资源
- 功能组件,组件是最基本的行为,它们是用户看不见的逻辑代码,它们用来控制物体在游戏世界中的行为;不同组件包之间的组件可以任何组合,创作者需要区分它们的功能,才能生成更好的合理的交互逻辑。这是创作体验的一部分。
- 部件或者物体,由一定的组件组合形成,具有某些特定逻辑功能的游戏对象或者实体,这些实体是直接存在于游戏场景结构中的元素,这些物体可能包含模型、动画、以及能够良好控制这些模型及其行为的组件组合,它们通常是用户直接放置在场景中就可以使用的,类似《堡垒之夜》当中的物体;它们有些也是用于帮助创作一个场景的结构性的组件,例如一个包含TAG的Entity,一个NPC怪物等;也包含一些特殊内置功能的部件,例如Layer表等。
1.5.2.1 一个Creation的创作流程
- 创作者首先浏览Creation商店,下载或者购买一些基本的资源,如上面介绍的静态资源、功能组件和物体等。
- 开发者选择一个物体,将其拖入初始的空场景中
- 然后选择物体对其属性进行编辑,其中可以对其添加组件,组件按类型进行组织,每个组件有结构化的描述及说明,说明应该怎样使用该组件
- 修改组件的属性参数等,组件通过参数来改变物体的行为或者视觉,例如如果是程序化生成组件,则可以生成不同的场景,如果是粒子特效组件,则形成不同的视觉效果
- 播放预览
- 将链接发送给好友
- 好友点击链接加入一起体验
- 如果好友具有权限,可以进行共同编辑,这些编辑也可以是同时在线协同的
1.5.3 开发者
开发者只能基于标准开发组件,一个组件必须支持某个标准,当然一个组件可以支持多个标准,来实现不同标准之间的通信。
标准和组件是隔离的。除来自标准之外的符号,其他符号都是私有变量。
1.5.4 标准作者
某个标准的负责人,当然标准可以转卖,当前负责人不一定是创始作者。
此外,标准不一定需要编程,它仅仅涉及定义与某个抽象相关的数据结构。因此,不具备编程能力,但是具有较强抽象能力的人也可以创建和维护标准。但是从更好的数据结构定义角度,由编程人员维护标准是最合适的,但是编程人员的抽象能力往往不够。所以理想的情况下是某个标准后面有抽象能力较强和编程能力较强两者的组合。
参见4.11和4.12节内容。
1.6 创造增量价值
元宇宙代表的不仅是一种新的体验,它将对整个社会甚至数字信息化的进程带来全方位的影响,这种影响不仅仅是一种新的技术或者一种新的功能那么简单,它将包括对计算架构以及全新的信息表述方式这种深层次的变革。
很显然,这种由用户驱动的全新体验需求,用当下的技术架构是做不到的,而且它的限制的根源来源于更底层的计算架构。在近几十年的计算机时代中,底层的计算架构基本上没有发生太根本性变化,例如我们能感知到的:
- 近10年编译架构基本上没有太大变化,一些10年前的经典著名基本上现在还是适用的
- 近10年编程语言的发展也没有革命性的变化,不仅至2010年之后很少推出全新的语言,大部分语言设计也只是针对一些开发体验层面的选择,很多语言的核心思想甚至早在2000年之前就确定
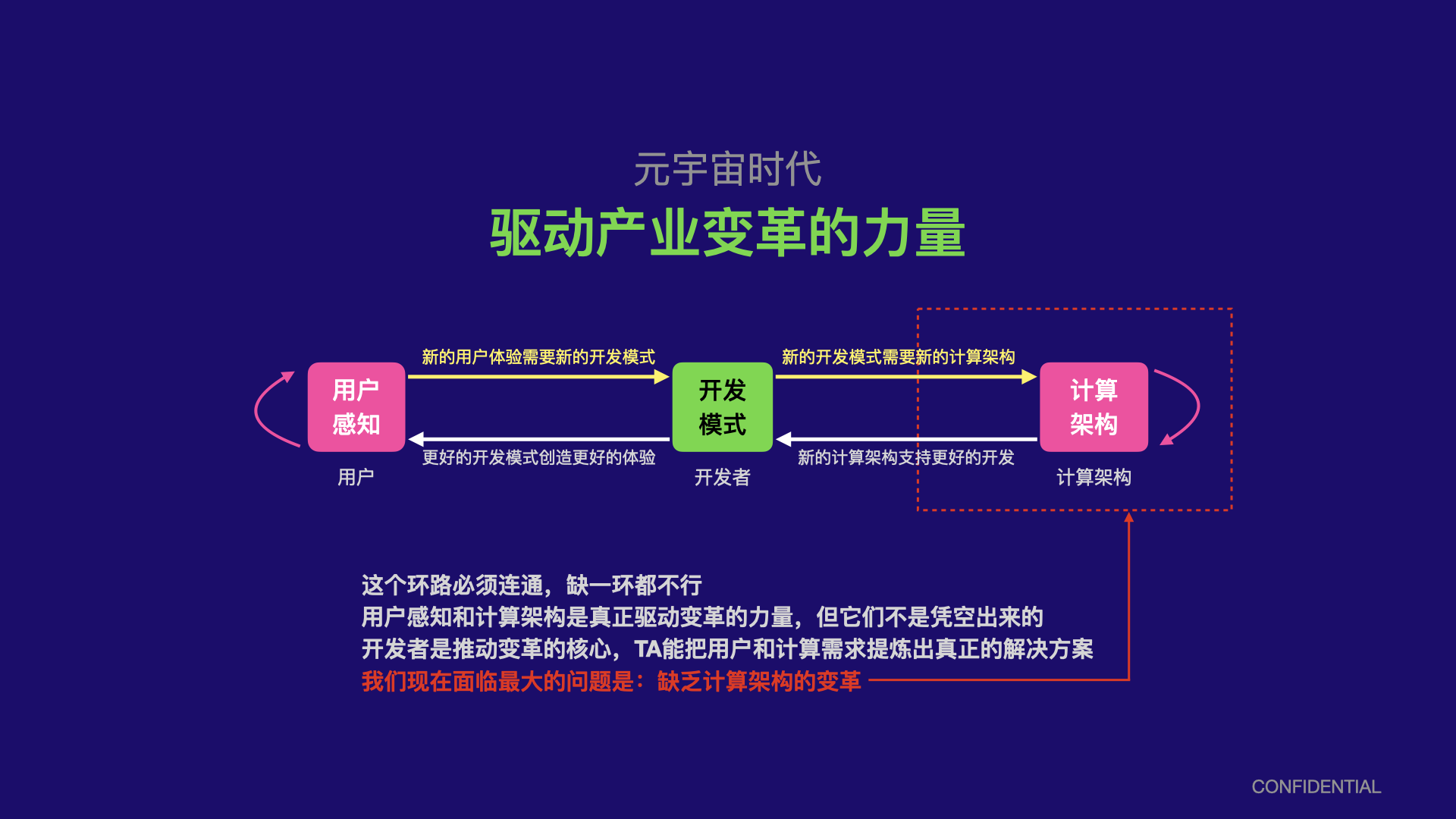
编译和编程语言是计算架构最重要的指向,因为它们连接计算机硬件和应用软件,它们的变革往往能够决定上层软件形态的变革,从而决定技术带给消费者的变革。
当元宇宙带来真正大规模、互操作、大并发等等这些传统计算模型不能应付的需求时,我们需要全新的思路,在计算架构层面创造全新的增量价值,才有机会驱动整个元宇宙的变革。
2. Reality Interoperable System
结构抽象,对于XR端的选择,如果卡包太多,会导致选择操作很复杂,参考淘宝购物,大家会把想买的商品放进购物车,最后一次性付款
让用户在手机端坐好归类,精选出确定或者大概率会使用的组件,然后简化实际的选择,甚至通过更加友好的命名规范来使用语言选择
总之就是需要更好的类型化,并且将用户对资源的选择过程中,融入分类,形成一个天然的筛选过程
定义创作的过程:
- 不仅仅是Create中的时间
- 像备忘录笔记一样随时记录
- 资源的选择准备过程
- 看别人的创作也是创作思考过程
- 甚至逻辑上的组织可能有一部份是非视觉相关的,所以资源管理本身要融入创作过程,即它不光是资源管理,也包含一定的逻辑组织,例如故事大纲结构等等,就像策划在组织表格的时候,比如编写人物故事对话
- 一定不能仅依赖于资源购买+XR端选择这样的传统模式,即交互复杂,也不符合实际的创作流程
2.1 Creation Scene Description
需要加入用户版权信息。
USD的asset resolution机制,使得可以直接加载creation.id的内存,而不需要单独写加载模块,但是需要在自定义resolution中加入权限验证,例如传入消费的app以及用户信息(Reality ID)。
USDZ可能是将一些Behavior转换为Schema,因为这些Schema是C++库,所以需要将USD的C++库放进iOS系统中;虽然USD提供有Python binding,但是它只是接口的封装,因为USD本身也是一门语言,语言本身需要解释或者编译,USD是将新的Schema生成解析的C++文件,所以需要放置在运行时,所以就不能动态定义,只能是系统级别的Schema,开发者通过脚本定义的数据结构还是需要增加一层解析;
为此USD文件中需要包含一些非USD的片段,例如定义一个特殊的Component或者Model,这可以通过asset resolution来与USD一起适配工作。这一部分可以不是USD语言,可以是自己定义的语法;
实际上USD文件不应该让用户看到和编辑,用户看到的是工程或者可视化的描述,或者属性表述。用户或者开发者也不需要编辑这么复杂的结构,USD本质上还是面向数据结构或者程序员的,RW的结构应该更简单、扁平。
2.1.1 分布式存储
对于实体对象的属性数据,可以不采用传统的属性结构进行存储,因为那样就会存储到一个文件,使其存档时会发生并发。
因为其实体对象属性本身是Table结构的,所以我们可以向内存访问一样,每次修改一个属性之后,这个属性利用虚拟内存系统自动存储到硬盘,然后等玩家退出或者程序崩溃的时候再统一存储到用户的数据存储服务器。
这样所有实体对象在云端存储的也是Table,不必存储到一个USD文件中。实际上在内存中它们也不必存储到一个数据结构,例如一个树形的数据结构。只有这样才能保证分布式计算。
将一个IO拆分为多个IO,可能会带来一定性能损失,但是考虑:
- 单个IO或者少数IO只能采用少量线程,如果是大文件解释也会很慢,没法有效利用多线程加载
- 现代NoSQL数据库对缓存,某些查询做了大量的加速,效率要大于单纯的文件或数据区查询
总之,这可以利用到多线程的优势,又能保证分布式。
2.1.2 内存分布式
尽量避免内存中较大的层次性的数据结构,应该都是扁平的,相关性通过组件通信来实现。所有数据都是扁平的。
但对于传统的网格、材质、动画等数据,因为这些数据内部存到大量相关性、引用等,如果将它们存储为扁平的,则解析代码的效率会比较低,通常这种紧耦合的数据都是使用OOP的方式来解析和执行计算。这种数据我们就保留传统的方式,使用USD来保存这些数据。
这样我们存储系统里面会有两类数据:
- 复杂层次结构数据,这部分主要是USD,用来解析传统的模型、动画等
- 简单层次结构数据,这部分主要是逻辑部分
对于其他一些复杂结构,例如状态机、行为树、AI等,如果这些规则是相对固定的,则可以使用单独的格式存储,它们在文件系统中像类似USD那样的文件形式存储,然后实体对象按单独的机制加载它们并进行解析。会定义一些专门的加载以及对其进行操作的组件。
内存中要尽量避免使用层次结构去聚合多个数据,除了像USD这种传统的数据除外,当然对于USD,我们也要尽量利用数据驱动的特性尽量把不相关独立的数据拆开。尽量避免较大的实体对象。
2.2 Creation Script
Creation有一个核心目标:
- 它应该像Lua一样简单,轻量的运行时。
- 它的说明文档只有50页pdf,每个开发者只需要了解这20页文档,不再需要阅读其他资料已学习更高级的技巧。
- 它同时面向专业开发者和普通用户
- 尽可能少的系统层API,不要全部暴露引擎层的API,甚至可以将引擎层的API修改不同的易于业务侧理解的API名字,它的所有API应该像Houdini一样,全部专注于业务,不需要开发者了解的就不暴露给开发者
Creation Script的核心目标是:
- 首要构建一套能够便于普通用户编辑、和共享逻辑的架构;所以他必须能够动态更新
- 次要目标是简化开发者的开发体验,例如只专注于逻辑,而不是复杂的面向对象组织设计,再比如简化多线程的开发,开发者应该感知不到并发编程;例如不能为了方便对Component 进行管理,就要求用户去配置一个包引用文件,而应该自动管理
- 应该是图灵完备的,不能限制开发者的能力
- 他应该基于一个已有的脚本语言,使他专注于上层架构,而不是去构建一套底层语言
- 复杂对象的构建在宿主,脚本主要做轻量计算
- 无垃圾回收,所有堆上的对象均有宿主分配和管理
传统语言几乎都是为了面向对象而生的,所以包含很多为支持面向对象的功能,如果数据驱动是需要的核心,是不是应该有一种新的语言,目前看来Lua更接近这种语言
编译器用途:
- 例如用于检查ECS的结构,不合法的类结构不能被加入到最终程序中
- 例如检查Component 数据内存分配大小等等
- 用于将底层面向对象的能力禁止面向开发者,但是保持底层能力对面向对象的使用
类型检查
TypeScript有很好的的类型检查,但是往往强类型的语言也有一定的限制,例如不允许像lua一样,在同一作用域内相同的变量名称改变类型,另外对于动态语言来讲,一般类型检查这种功能在运行时也是存在的,但本质上这个功能对于运行时不再必须,如果你能保证被检查过的源码没有被修改,一般语言不会把这个功能作为一个可选项
因此有必要设计一种类型检查,它可以被移除,使得仅在编辑时发生作用,而一旦发布之后,实际的运行时不需要这个类型检查的功能,但是还是会保留全部的源代码信息。并且自定义的类型检查可以容许更少的限制。
怎样为Lua添加新的语法
参考TypeScript相对于JavaScript 添加的功能。
Unity DOTS为什么没有默认把System中的并行性指定去掉,是因为他希望兼容传统的Component脚本,而按照传统的写法,没法去控制行为,所以只能开发者实现并行计算。
否则就需要像Roblox一样,需要用户自己将脚本挂在entity上,这就增加了复杂性
所以需要避免让开发者手动将Component与System之间进行关联
Minecraft通过直接在属性中进行编写MOLANG代码来避免该问题
例如开发者看到的文件或者对象只有Component,这样迫使开发者对数据进行抽象;
对于System,我们首先不需要开发者去关联一个Component和一个System,他们应该自动关联,例如通过Component来打开对应的System文件进行编辑
Component除了自身的逻辑属性,另外一些属性用来控制系统结构,例如System执行的顺序等,可以在Component中明确区分两种数据,或者这些固定结构的数据就以一个Component本身的Property形式显示,避免开发者写错
但System可能需要多个Component的数据,因此可以设计为一个System必须对应一个主Component(即使这个Component可能只是一个名字,而并没有任何数据,是有这种情况的,就是某些逻辑本身不包含任何数据,他可能就是一个对多种逻辑进行计算的一个组合逻辑,但是这种应该很少才对,毕竟大部分System应该关心的是自己,其他的是作为查询条件),这样仍然可以将System隐藏在Component中,但是System自身能够指定引用的其他Component作为查询条件,也即是在定义ArchType,可以在System的顶部使用类似。
XXXComponent a;
BBBComponent b;
然后在正文中就可以引用这些对象,解释器会自动将该变量从Entity中进行查询,并且检查如果Entity不包含该Component的时候进行自动添加,当然也可以检查冗余,即如果没有任何使用则不需要添加
但是Component的版本号在哪里设置,使用明明空间加版本号?
BBBBComponent(reality:name,1.2.3)
怎么默认指定?
开发者肯定是先下载了一个包含Component的包再进行编程,但是仍然可能有冲突,所以最好是需要明确指出,而不是自动分配,因为总有一个地方需要明确指出,使用单独的配置文件看起来并不是一个很好的方案
Python嵌入 (Embed in Python)。Python极其易于学习并且被广泛采用。Taichi的前端语法是Python的子集,这使得任何一个Python程序员都能够轻易地学习、使用Taichi。我们使用Python AST灵活的自省 (inspection) 机制来把Python的AST转化为Taichi的AST,随后进入我们自己的编译和运行时系统。将Taichi的前端嵌入进Python有如下好处:
- 容易运行。嵌入在解释性的Python语言而不是编译性的语言中,大大方便了Taichi程序的运行,因为母体语言的预先编译 (ahead-of-time compilation) 不再需要。
- 容易重用已有的Python基础设施并与其交互,包括IDE (PyCharm等)、包管理器 (pip)、已有的Python包(如matplotlib、numpy、torch等)。
即时 (Just-in-time, JIT) 编译。JIT不但提供了极强的编程灵活性,还延迟了”编译期常量“的需求。比如,在物理模拟器中,时间步长 ∆t 通常被实现成运行时变量,而使用JIT的时候则可以被处理成编译期常量。这允许编译器进行更多的优化,如常量折叠 (constant folding)。同时,Taichi支持模板元编程,伴随着JIT的懒惰编译技术大量节省了不必要的编译时间。另外,对于无法运行Python的环境,如移动端设备,我们也提供提前编译 (Ahead of time, AOT) 相关设施
对大众用户、或者偏美术、艺术类用户,最好的脚本语言是什么?图形化的吗?他应该具有两个特征:
- 对一般用户友好
- 适合数据驱动
- 适合DSL编译处理
面向数据编程:
传统的游戏开发是面向事件编程的,例如我们写的所有逻辑几乎都是在每一个frame的某个事件中发生的事情,例如在Unreal的蓝图中,它的起点也是针对某个事件,这有两个缺点:
事件的粒度,游戏逻辑中,几乎主要逻辑都是事件驱动,因此详细的事件非常多,所以大部分都是开发者自定义事件,这些事件由开发者自定义的状态机来进行管理,Framework层只有几个基本的游戏生命周期事件,开发者自定义事件之间没有标准,或者非常复杂,不方便维护
事件与逻辑不一致,像UE的蓝图是基于事件编程,如果我们要把这种能力开发给普通用户,这种没有标准的事件定义并不适合让用去去学习,这些事件通常也没有必然的逻辑联系,不容易理解,例如一个逻辑可能对应多个事件,显然用户需要了解的是逻辑,而非事件
数据代表的是逻辑,所以平台大部分都在设计这种数据,用户也便于理解,同时它代表的不是最小逻辑,而是逻辑模块,所以他将逻辑内部的实现细节(众多的碎片事件)进行隐藏
数据也代表接口,数据的标准有助于构建结构化表达,是逻辑更清晰,以一种更清晰的方式组织
面向数据编程,就像Houdini 中面向Node编程一样,一段Python 代码是受限的,它的输入输出是node ,同时又可以使用到python 本身的任意语言特性和能力;与此类似,面向数据编程也是针对一个特定的“数据”编写脚本,用户编写的是System,他的输入输出是数据Component
但跟传统的ECS架构不一样的是,它的Component 和System之间不是一一对应的,甚至不是自动挂载的,这个机制非常重要,一个Component 理论上可以被多个System消费,当然通常一个特定的Entity实例只有一对Component 与System的组合,因为理论上对一个实例的一个类型的数据,应该只有一个操作逻辑,除非多个System之间逻辑不一样,他们可能偏重数据的某一部份,但是这种情况通常是数据的粒度太大了,可以再进一步细分,当然可能有一些特例需要维持较大的数据。
所以这就使得app包里可能包含一个数据定义的多种逻辑,所以我们不能使用自动挂载,而需要依赖于版本制定,在开发或生成内容的时候,我们将一个System添加至一个Entity,他就生成对应的System引用和版本号,加载的时候是根据这个进行逻辑挂载,当然一个独立的应用本身在顶层也会记录所有引用的Component和System,这样便于预加载
比如如果数据是涉及动画,则数据包含动画时间和当前frame number 等动画信息
把数据当作一个类似Houdini 里面的可视节点,System是另一种类型的节点,拖动任意一个节点到一个Entity会自动加载变量,以及相应的组件版本依赖关系
Creation Script
它的语法部分接近Lua,但是因为所有Table全部由Table Engine接管,脚本中只有索引和基本类型,不存在堆中分配的对象,所以不需要GC
脚本只有简单的计算和函数形式,所有操作对象统一,函数只有简单的数值操作,对象都由底层分配
脚本负责函数内的栈上操作
底层负责堆上内存分配
这得益于统一的数据结构和内存管理
2.2.1 全局变量表(符号表)
符号表的核心意义在于,让不同开发者开发的组件之间可以相互交互,因为如果不是这样,那么我们整个应用程序就只能依赖于单个开发者开发的组件,或者每个开发者开发的组件只能独立工作而不能相互交互(在传统的应用开发流程中,开发者通过变量赋值和引用手动建立起了来自两个不同开发者开发的组件)
符号表隐含的逻辑是,组件之间的交互涉及的变量应该足够少,大部分应该是内部状态,例如COC中的Cannon:
Damage per second: 11
Hitpoints : 650/650
Range : 4-11tiles
Damage type : Area Splash
Targets : Ground
Favorite target : Any
 符号表使我们更加小心地定义我们的变量,使得不那么随意,符号表的全局通用性地位使我们更好地地抽象逻辑,确保设置确实的反应逻辑状态的变量。
符号表使我们更加小心地定义我们的变量,使得不那么随意,符号表的全局通用性地位使我们更好地地抽象逻辑,确保设置确实的反应逻辑状态的变量。
此外,符号表是一种很好的机制,使得我们很容易将一个组件的内部临时变量和对外表现特征的重要状态变量区分出来,逻辑更好清晰。使得代码逻辑更清晰,他人阅读更容易理解。
#version 1.0.0
namespace Global{
iHP //表示血量
iHelath //
iCoin //
vfPosition
sLabelName //用于UI显示名称
}
当然符号表更重要的价值是,实现组件之间相互调用的隐式参数传递,组件之间的依赖通常是比较少的变量,在OOP中这些变量即是两个类之间方法调用的参数,如果我们不区分公共和私有变量,则只要两个组件之间有依赖,就需要加载所有的数据,而实际上有些数据是不必要的,因此它有利于提升性能,只加载每个组件需要的数据。
此外,设置out变量的组件,对应的属性数据会被自动填充,因此避免了手动的变量定义、初始化和参数的传递,这是隐式函数调用的核心机制。当然,开发者应该保证一个全局变量应该同时具有消费者和逻辑处理,否则这个计算可能没有用处,这个通过设计来规避,编译器可以协助提示,因为一个正常的设计肯定是两者都有的;当然也有可能一个组件既充当生产者也充当消费者。
这是最核心的机制,因为如果不这样,要想在两个组件之间进行交互,就必须定义一种协议,这种协议通常就是传统程序语言中的引用机制,因为这样才能保证运行时变量可以识别,这就需要在B中定义公共变量,然后A组件需要引用B组件,这就形成耦合,但是不引用,语言本身的机制没法保证哪怕是同一个名字的变量执行同一个地址。
因此,通过符号表,整个事情变得简化:
- 共享变量只需要定义相同的名字,而不需要引用,这个相同的名字由符号表保证,而不是字符串,因为字符串又设计对应的解析,带来解释负担。而传统编译器中的符号表天生就是用来将多个名字相同的符号指向同一个内存地址。
- 避免了通用语言中只能通过引用来实现参数依赖和传递,而这种依赖是导致没法简化编程甚至无代码编程的根本原因。
当然,符号表机制不适合通用语言,它是游戏这种Update机制相结合才能发挥作用,因为两个Update之间的时间很小,有可能通过帧之间的变量共享来实现函数调用和参数传递。否则这种机制就不生效。
此外,这种机制必须配合解释器或者编译器工作,比如单纯集成Lua或者C#是不够的。
2.2.1.1 动态的符号表
在程序中,符号表应该是动态的,以提升解释的性能。因为符号可能会非常多。
首先在创建内容的时候,根据选择的组件计算所有用到的符号表,然后动态生成一个符号表,这可以是云端的一个接口。
当需要修改实体对象时,重新生成新的符号表。
2.2.1.2 符号表
所有交互都来源于符号表
符号表基本上就是为了交互而生
符号表引用就是为了避免直接引用,因为直接引用引入了代码编程思想,限制了组合的能力,除非组件之间完全独立无交互,只要交互通过直接引用就耦合了类型,符号表这是实现类型解耦的关键
符号表需要是公共资源的形式管理,用户可以下载很多开发者定义和上传的符号表,这些符号表由开发者上传,比较有名的符号表可能会得到很多其他开发者的支持和兼容,从而实现跨开发者之间的协作
多个开发者定义的符号表也可能有重复,需要统一的机制,这可以通过:
- 强化全局表,把开发者定义的符号表发展为全局表
- 全局表分类
- 建立表之间的映射和关联,这比较复杂
所有的类型引用都通过数据查找
但是数据不能完全代表类型
某种程度上,数据的组合才代表类型
ECS的最大问题可能是无法区分类型,只有定义字符串或者枚举数值,tag之类的?这些类型由变量的值而不是符号本身决定,这些值可以有开发者或者用户控制
但是tag需要是针对组件,而不是实体
- 实体可以任意复杂,他不可能具有单一类型
- 类型可能被多种组件访问,内存无法控制
定义多个标签,每个组件都包含自己的标签,或者跨组件之间的数据必须是结构体符号,这样结构体本身就包含了类型
这可能导致数据属性重复的结构体,但这没关系,本身数据就是有不同意义的,即使数据结构差不多
考虑只针对某种类型的怪物的血量造成伤害
这个类型标志应该是跟HP关联在一起,还是跟怪物实体呢?
需要一个万能标签,每个组件一个,但是名字相同,编译器保证重复问题
原子“数据”
一个组件的数据或者数据列表应该是有意义的,这个数据的组合应该充当类型,表示一类功能对应的数据,比如HP和Health 通常是组合的,所以我们就不应该单独使用HP,如果有多种类型都需要使用HP,这就需要定义一个结构体
当然这没问题,符号表的意义并不是全部打散成独立的符号,而是为了避免类型引用,但有一下问题:
- 理论上可以为同一实体添加多个HP,这需要开发者用户来避免
所以类型看起来更多应该是由组件的数据合作隐式定义,而不是由符号表来定义,符号表应该足够松散,这样来保证最大的灵活性
组件定义的TAG变量不来源于符号表,但是和符号表类似的定义,编译器特殊处理
或者TAG数组组件本身,是一个用来取代引用组件类型名称本身的一个标志
2.2.1.3 符号表定义标准
尽管从概念上,符号表表示的是一个变量属性,或者是变量的定义,它的目的看起来就是为解耦变量的声明与引用服务。
但是从系统的需求上看,一个符号表应该是包含一个完整的对某一些事情或某一类逻辑的一个完整数据结构,因此它定义的是一个标准。参见2.7节。
2.2.1.4 版本与兼容性
- 修改名称:可以做一个映射,编译器直接处理,甚至组件可以一键升级,代码替换最新名字
- 删除符号:如果发现缺失相关符号,相关的组件不再被解释/编译仅程序,并提示用户组件过期,需要更新;这部分通知通过Reality World进行管理
- 新增符号:会通知开发者,建议开发者支持
2.2.1.5 符号“定义”变量
在RealityIS中,组件并不真正的定义变量,例如它只能选择变量,但是不能决定变量的类型;此外,它存在着重复定义的问题。
为了解决如2.7.16.5节描述的重复定义变量的问题,组件中的变量定义是一种特殊的机制。整个变量定义和使用的过程如下:
- 符号表唯一定义一个变量,但其实它并没有分配内存,但它决定了变量的类型和结构
- 组件中引用符号表定义的变量,但也不是简单的引用
- 当一个对象第一次遇到某个符号时,它在该对象上添加该变量,并分配内存
- 当后续的组件引用相同的变量时,它始终将地址指向前面分配好的内存地址
见2.7.16.5节的更多描述。
2.2.1.6 符号定义不可分割的最小属性集合
一个符号应该定义一个不可拆分的数据集合。比如:
Position {
float x;
float y;
float z;
}
如果一个以上的属性总是同时出现,那么将它们定义为一个符号。
将多个相关的符号定义在一起,会迫使这些变量总是存储在同一个对象上,避免了函数因为多个参数分布在多个对象上导致的多层嵌套问题。
2.2.1.7 作为通知机制的符号
除了那些处于嵌套函数最底层的函数所消费的属性,这类属性通常不会触发其他的函数执行计算(显示、存储之类的函数除外),大部分属性除了数值本身,还具有通知属性:即告知其他相关组件,我的数值发生了变化,相关组件需要执行计算。
如果一个组件的值没有发生任何变化,根据组件作为纯函数的机制,后续相关组件都不需要执行计算,除了声明.UseDt的动画类组件除外。
如果动画类组件不受通知机制的影响,那么它会一直执行,这种情况下需外外部对象来执行一个类似Enable/Begin和Disable/End之类的操作。这可以通过Spawn来实现,也可以通过类似获取引用来实现控制,后续需要相关分析一下。
如果需要通过值的是否变化作为后续组件计算的依据,这就使得属性值实际上承担了两个功能:
- 后续组件会使用的输入值
- 通知功能
但这两个功能是有歧义的,例如如果一个技能要求扣除的HP是3,所以整个值3同时承担了通知功能和扣除的具体数值的功能,但是如果下一帧该技能继续释放,那么属性值依旧为3,但是此时系统会认为该值没有发生变化,因此通知功能失效。这说明,单一的值不能同时承载两个功能,它们分别需要自己的数值或者标记。
一种解决思路是在每一帧的末尾,把这些数值清零。但是这样做,其他有些属性会受影响,就是那些不是增量值的变量,它们需要始终存储自己的值,实际上只有像技能这种扣除性的增强属性才可以这样做。
另一种思路是要求所有增量型的变量始终执行,让开发者保证结果是正确的,例如下一帧如果该技能没有释放,那么就需要把值置零。但其实这种置零的过程会是后续的组件误以为发生了变化,根据默认行为。
这个问题在传统的开发中不会存在,是因为它们大多使用主动式的调用逻辑,即发起技能的函数会通过某种形式直接能够触发对扣血函数的调用(例如通过一些Manager之类的函数),因此其实它们不会存在一个中间状态的增量值,因为下一次没有技能释放则压根就不会调用这个函数。
另一种思路是通过消息的机制,传统的消息机制是将消息存放到一个队列中,然后响应者从消息列表获取消息并进行处理,当所有响应者都处理完毕时,这条消息就会被删除。
RealityIS的属性通过按依赖顺序执行的机制,使得属性充当了消息的功能。但是这个消息在一帧结束后并没有清除,而是这个值会永久存在,因此带来了上述问题。
像硬件的输入事件,本质上是类似的问题,但是通常系统输入并没有使用消息的机制传递,而是直接编写update函数,这样监听输入事件的脚本会一直执行,开发者需要保证每一帧的计算结果都不会进入不可预期的分支。但是因为处理输入事件的脚本不会很多,所以不会导致太大的问题。但是如果系统大量开发者自定义的逻辑也已这样的方式运行,则可能会有一定的性能损失。
最简单的方法是使用.UseDt(true)使其像输入组件一样应用执行。后续再考虑优化的方法。
2.2.1.8 存档属性
组件之间进行通信会有大量的属性,显然有很多属性是不需要存档的。而平台也无法判断那些属性需要存档,也无法让创作用户在创作的时候去指定那些属性需要存档,存档的功能属性本身是开发者和标准制定者可以决定的。所以,存档属性应该由符号表来定义。
不管是共享符号表或私有符号表都可以定义符号是否需要存档。
即使是全局共享符号表,有些仅是用来实现不同用户之间交换的符号是不需要存档的。例如那些仅仅是无关紧要的通知属性。
比如玩家在攻打一个Boss,这其中需要花费大量的精力,通常几分钟甚至十几分钟,这期间Boss会有很多状态变化,玩家的动作、动画状态、行为树等等也会发生很多变化、环境中的树木也可能临时被炸掉等等。但其中除了用户使用的技能道具等,其他大部分数据都不要存档。
Boss战存储的更多是一个大的结果,这样当其中出现崩溃时,玩家可以重新打Boss。
对于存档属性,运行时会保证当组件正常执行后,其修改的结果会被存档。
2.2.2 Entity
ID + TAG
每个实体有个隐藏private变量:TAG和TARGET用来定义组件本身的标识符,以及用作查询条件的标志符
在Entity上增加TAG,因此充当一个Entity的类型区分,创作者可以在Creation中创建一个Layer表对其进行管理,例如可以统一命名等。
对于System的TARGET,它指向Entity的TAG属性,虽然System对于一个Creation只有一个实例,但是System本身只包含方法,System的状态数据(private私有变量)是存储在每个Entity内部的,它具有多个实例。因此对于TARGET来说,每个Entity的值都不一样,因此Entity可以处理不同的类型目标Entity。
2.2.3 三种变量类型
#version 1.0
#order 5
namespace SomeComponent{
query Global.HP as hp
query Global.HP[] as hps
public Global.HP as hp
private fTemp = 100.
private TARGET = 20
}
三种类型变量说明:
- private 是每个组件的私有变量,只有该组件内部可以访问,这可以通过直接声明实现,因为没有从全局符号表引用声明,所以其他组件没有可能对其进行访问;private是实体的实例变量
- public 是每个组件的公共变量,可以被实体内跨组件访问,也可以被其他实体访问;public也是实体的实例变量;通常public变量由使用该变量的组件定义,可以多个组件中都重复定义,会被映射为同一个变量
- query不是组件本身的变量,它是指向外部变量的引用,它只能访问那些定义为public的实体
2.2.3.1 私有变量
私有变量只是实体内组件才可以访问的属性,实体是用户创建的,其所有权是属于用户的,同样,该实体所有的组件是由用户选择的,所以这个选择间接包含用户对该组件访问该实体数据的权限。
选择组件:
- 除了是一种功能构建行为
- 也是一种授权行为
组件能够访问自己所在实体的任何属性,不支持在实体内再划分权限,那么将会增加复杂度,而且看起来没有那种必要,实体这个粒度作为权限单位:
- 即是足够的,合理的
- 也是用户设置和管理起来相对比较容易的
2.2.3.2 写入权限
组件只有对自身实体所在的属性才具有写的权限,不能对其他实体数据进行修改,否则权限不可控制,因为权限是按照实体为单位进行构造的。
这也是一种拉取模式,参见2.2.11.2节。
2.2.3.3 私有变量不是组件的状态
一个实体的属性,要么作为组件的输入,要么作为组件的输出,它总是对一个实体的每个组件可见的。
但是像类似动画或者一些自定义跨帧逻辑的这种组件,他可能需要存储一些跨帧的状态,这个可以通过私有的符号表来定义,但它们跟其他属性之间存在一个主要区别:
- 这些变量一般只能被一个唯一的组件感知,其他组件不应该也不需要知道它的存在
但如果只这样,就造成一种潜在的问题,这些变量看起来充当了这些组件的状态:因为输入条件不变的情况下,可能有不同的输出,这破坏了组件充当纯函数的目标,也使得通过输入是否变更来决定是否需要执行组件计算变得困难,参见2.3.3节。
针对这种情况,一种解决方案:
- 让这些中间变量成为时间的函数,在每一次函数计算中,由组件函数根据dt参数计算而得
这种可能会每帧重复计算一些内容,但是其实可能问题不大,因为那些存储的中间状态,其实大部分是每帧都要代入dt进行重新计算的。
尽管这可能带来一定的性能损失,但是相对带来架构的简洁性,是可取的。例如在传统的函数式编程当中,为了维持函数的纯函数特性,以及变量的不可修改特性,其实也做了大量复制相关的操作,但是相对性能,它们带来的架构价值更大。何况RealityIS可以通过分布式及其他特性来弥补这些性能损失。
2.2.4 数据抽象:共享变量与解耦
变量的声明与程序执行指令的耦合,是现代计算架构最大的限制,这可能有2种原因:
- 现代编程语言主要是还是基于硬件计算架构的,它上面所做的抽象,更多是围绕用开发者(人的)的角度怎么去理解和组织机器代码的结构,而没有围绕人类理解事物真正的逻辑去进行调整。
- 现代的应用程序架构都是围绕单个独立的应用程序设计,即使有多个应用程序之间需要交互的需求,这些少量且相对比较固定的需求可以使用一些标准的形式解决,例如HTTP协议。
在未来的元宇宙时代,我们需要一些全新的编程架构,所以最重要的是:
- 我们需要在硬件架构和应用架构之间,建立起一个数据抽象架构,将传统硬件计算架构的限制隐藏起来,并且上层应用架构的能力可以更大的释放。
所以,RealityIS的核心逻辑,是通过对编译过程的改造,在操作系统和应用程序之间建立一个新的转换层,是能够将基于数据抽象的程序架构,转换为传统基于硬件架构的程序结构。
2.2.4.1 共享变量的声明
#version 1.0.0
#order 1000
namespace SomeComponent{
public Global.iHP as iHP = 5
public Global.vfPosition = (1000.0, 234.5, 400.8)
public Global.sLabelName = "Super Man"
private fTemp = 500.6
fn Update(fTime){
fTemp = fTemp * fTime
iHP = fTemp
}
}
由于每个组件定义变量的顺序可能不一样,所以编译器要进行排序。
此外,由于这里使用全局符号名与局部简写名字的区别,在解释器中,需要去除本地变量名称,使用统一的全局名称,因为不同组件对于同一个全局变量,可能使用不同的局部变量简写。
对于需要处理其他物体的组件,定义一个数组的形式,解释器自动查找:
#version 1.0.0
#order 1000
namespace HandleOtherComponent{
outer Global.iHP[]
outer Global.vPosition[]
out vPosition as position
fn Upadte{
for i in iHP{
if(distance(vPosition[i]-position)<10){
iHP[i]-=1
vPosition[i]=(10,10,10)
}
}
}
}
上述的类型用于由一些特定对象发起的行为,如果是全局组件,全局组件每个场景只有一个Entity可以拥有
#version 1.0.0
#order 10
namespace PhysicalComponent{
unique Global.Collider[] clliders
}
定义了global的属性解释器会解释唯一性,这也意味着有些组件是没有方法的,但没关系,从用户角度来说它仍然是一个功能,例如:
#version 1.0.0
#order 100
namespace ClidderComponent{
public Global.Cllider
public TAG = 100
}
也就是组件分为三类:
- 一类对自身进行处理
- 一类对其他对象进行修改,这种情况有一个发起的对象
- 一类是没有特定发起的对象,它是对于某些类型的通用行为,例如物理引擎
2.2.4.2 共享变量的初始化
生产者和消费者都可以设置初始值,其中一个修改会复写另一个,因为对于共享变量,一个实体只有一份数据。
初始化的方式:
- 编辑器中修改,每次选择一个组件,设置后,下次其他组件加载的也是修改后的值。
- 在运行时,用户选择一个物体,对其进行修改,运行态用户只看得见一份共享变量,组件只有私有变量可以单独设置。
- 通过代码的形式加载组件,按时间覆写数值。但一般情况下,组件的初始值应该由其定义默认设置,否则容易造成迷惑。一旦实例运行一段时间之后,值应该由持久化的数据进行加载初始化。
2.2.4.3 函数参数解耦
- 每个组件只需要对感兴趣的数据进行交互
- 游戏特有的Update机制保证两个对同样数据感兴趣的数据都能够按顺序被执行
剩下只要我们保证两个组件之间的逻辑顺序,它们之间就可以以间接的方式实现交互。在这个过程中,共同感兴趣的参数充当了函数参数,同时不需要引用其他组件进行调用。
这是一种全新的机制,只有这样,才能实现两个独立组件之间的交互,而且,除了对函数调用进行解耦,它还有一下三个好处:
- 每个组件只需要处理自己感兴趣的数据,不需要去关心跟其他组件之间的交互,例如就不会出现面向对象编程中常见的你调我还是我调用你的问题,这让我们将编程思想回归到本质,每个函数都只是处理自己感兴趣的数据,并输出相关的数据,但这个函数式编程还不太一样。现实生活中,大部分功能都是在处理数据,这种思维理解起来更简洁。
- 简化并发相关的问题,大部分并发相关的问题都是由于面向对象编程中的对象相互调用导致的。不仅不利于并行计算,而且容易导致各种并发问题,例如死锁,资源抢占等等,因为不可预期的多个对象会访问同一个对象。
- 还能减少因为变化导致的重构、重新发布程序等问题。当一个函数参数发生变化时,必须要修改调用者的代码,它可能使得其他组件不再可用或者崩溃,因而使得其他组件不太愿意更新到最新引用,从而导致系统进化很慢。函数解耦可以使得一个组件的修改至少并不会影响程序的运行。当然如果逻辑发生了较大的变化,程序的计算结果可能逻辑上是不及预期的。这种要有好的机制保证及时更新,但这种机制是系统更上一层的机制,在系统层,我们首先应该保证平台运行的稳定性。
2.2.4.4 赋值与解耦
传统的赋值语句本身就包含了耦合,它由一个读取语句和一个写入语句构成,虽然从逻辑上来讲没问题,其中包含安全问题
- 读取语句引入耦合,原本我只想给资源增加一定的增加,我并不需要关心总量
- 写入是重写,覆写操作,具有破坏性
尽管程序中有+=操作,但是由于它与写操作是同一权限,能够执行+=操作的变量意味着可以执行写操作,因此仍然具有破坏性
需要将原值读取出来,进行一定的计算,例如加减计算,然后进行赋值,这使得原本对值进行增量的操作逻辑,很容易写到实体外部,即增量来源的地方,这种操作引入了不必要的耦合,因为增量实体根本不需要包含这样的逻辑,但是如果要隔离权限,开发者必须得写一个类似Add(delta)的方法
Machinations 的资源流的一个重要基础,它将两个实体之间的联系,即经济的流动,都看成是增量的,这样经济之间的流动过程中,各个实体就只需要关心自己的事情,然后输入输出一个增量就可以,这个增量本身对两个实体没有任何耦合
生活中大部分其实就是这样的流程,想象一下,你要取100元钱,银行直接给你100,而不是你让银行先把所有钱给你,你拿掉100,再把剩下的钱存回去,如果你在数钱的时候被旁边的人抢走了怎么办呢?
Creation Script 中,组件之间(即对外部变量)的修改支持:
- 增量式修改
- 并且一个组件之间多个修改保证原子性
这使得每个组件只专注于构造自己的增量,大大见减少耦合,并且不需要编写复杂的方法来实现增量修改
如果实在是需要依赖于总量进行计算的,这种少数情况可以先读取总量,计算合适的增量,再对其进行修改
默认增量与默认赋值相比,虽然能实现的功能都没有差异,但是它避免了大部分情况下的耦合,毕竟大部分操作是增量,而且在ECS中在Component 中不适合写方法
编译器也可以进行优化,系统生成更优化的代码,当然这个功能本身不是为代码优化服务的,它是为用户开发效率服务的,能够简化逻辑关系,让用户逻辑更清晰。
2.2.5 组件语义化
符号表机制带来的最大价值,是它消除了模块之间的显示调用参数传递,使得一个组件退化为一个功能,而隐藏了传统编程中要使功能运行起来的参数传递,因为这就需要变量的声明和初始化,而变量的定义有涉及类型系统。这就不可避免导致对编程的学习。
当组件抽象为一个功能,它就可以语义化,一个功能用一个语义表示,而语义是所有人可以理解的。一旦用户选择一个语义,对应的功能及其跟其他功能之间的交互就会自动适配和工作,用户最多需要设置一些特定的属性值。
2.2.5.1 语义化与可视化
符号表及其游戏Update机制,联合起来解决了两个函数之间参数隐式传递的问题,使得不需要开发者或者用户显式指定两个模块之间的参数,既简化了逻辑开发,又使得函数或者代码功能的语义化成为可能
语义化以后的程序,形成可以用自然语言描述的结构,有了这个基础,再结合自然语言人工智能和语音方面的进展,可以做到最简化的内容创作
- 自然语言
- 结构化语言
这是两种完全不同的机制,虽然自然语言中本身也是有句子语法结构的,但是自然语言本身并没有编程语言那么高度结构化,例如即使包含语法错误,人与人之间的交流也可能因为相同的经历、知识等原因对其进行纠错,从而忽略错误的语法,然而机器执行的结构化语言也不同,除非是基于AI进行学习,但是那样又需要大量的数据学习
可视化图通常由一些:
- 节点和
- 节点之间的连接关系
来表示,节点表示一个流程的功能,而连接关系不仅表示了某种流程顺序,他还表示了流程之间需要遵循的参数约定
既然符号表解决了参数传递,那么剩下只需要显式声明节点的功能定义,则整个图可以构成结构化的描述,同时也是可视化的
由于自然语言不具备精确定义,所以需要定义明确的节点结构
这种结构最好是一种描述语言,他具有基础的语法结构,而基于这些结构进行扩展可以构建具体、复杂的实例
所谓语言结构,即包括它的参数(连接属性),它的功能属性都是明确的
相反,只是任意定义一些没有联系的基类,则无助于构建有价值的可视化图,因为尽管他可以连接一些节点构成图,但是这个图的流程和意义是完全没有意义的,没有价值的
2.2.5.2 能否自动生成Machinations
Machinations 提供了这样一个基础,他能构建起易于理解具有一定逻辑的可视化图,但是它的结构是以经济流动为基础的,有些逻辑不一定有明显的经济因素,所以可以对其进行扩展,有了这样严谨的语言结构,再把组件定义为这样的逻辑单元节点,则节点的语义就明确而且又意义了。
这样可以方便用户涉及Gameplay的玩法
对于每个Machinations中的元素,设计对应的Component,只要从这些Component集成的组件,就自动遵循相应的功能或者接口需求,就可以自动生成设计的可视化图。
或者甚至可以根据Machinations反向生成初始代码。
或者甚至如果Machinations是一种通用编程语言,所有的组件就要求开发者这样去做,这对于用户来讲,就更好控制逻辑行为。
可以对Machinations进行深入分析,加一定的改造。
2.2.5.3 复杂系统的仿真
复杂系统的仿真,对现代工业很多研究直观重要,并且由于真实世界中大部分深刻都机制都深藏于复杂系统中,往往那些直观简单的结构化机制并不足以洞悉这些系统的原理和影响,所以我们需要更好的程序机制来支持复杂系统的仿真。
然后由于复杂系统的特征,现在计算架构并不能很好的处理这类任务,例如:
- 复杂系统往往非常庞大,使用传统面向对象的机制通常无法维护这么庞大的系统交互关系,很难建模
- 复杂系统一般都是实时系统,它并不太适用于传统的应用程序架构,所以现在大部分仿真任务都是使用游戏引擎来执行
- 复杂系统往往还包含人的交互影响,是一个交互式系统
所以目前并没有很好的解决复杂问题仿真的程序机制或者系统软件,RealityIS有机会在这方面提供更好的基础架构和能力。
2.2.6 组件查询
To read or write data, you must first find the data you want to change.
The main way of processing DOTS data is ECS queries. Iterating over all entities that have a matching set of components, is at the center of the ECS architecture.
To identify which entities a system should process, use an EntityQuery. An entity query searches the existing archetypes for those that have the components that match your requirements. You can specify the following component requirements with a query:
var queryDescription = new EntityQueryDesc
{
None = new ComponentType[] { typeof(Frozen) },
All = new ComponentType[]{ typeof(RotationQuaternion),
ComponentType.ReadOnly<RotationSpeed>() }
};
EntityQuery query = GetEntityQuery(queryDescription);
按类型查询组件对用户来讲不太好理解,它让你必须很清楚所有实体中哪些实体具有哪些组件的组合
按类型查找也限制了组件的行为,它只跟类型一致,而实际上,一个攻击可能只针对某些类型的怪物,这些怪物的数据属性是相同的,即可以使用相同的组件,但是因为值的区间不同,它们被分为不同的类别,除非你重复定义Component,这些Component有相同的属性,否则你无法区分它们,即Component充当了类型,但是实际上它只是数据,不能完全充当类型。
怎么对于DOTS中的查询,由于符号表的意义是取代类型引用的,所以ECS中Component的类型需要放到符号表中,换句话说,符号表中的名称同时也表示了符号,因此符号表需要是结构体,像shader中的变量一样,这个结构体的名称或者这个结构体本身就代表了组件类型:
例如符号:
struct Position{
float x
float y
float z
}
组件中的定义:
#version 1.0
#order 1
namespace SomeComponent : Component{
public Global.Position as position
fn update(float dt){
}
}
外部引用的组件,使用query修饰符,表示这个变量不是该对象自身的变量,而是查询结果,如果有多重查询,需要定义一种联合查询的方式,但是可以先仅考虑但组件查询,Unity间接使用了多种组件的某些特定组合数据来定义一个System,因为单个组件无法确定数据类型
#version 1.0
#order 2
namespace AttackComponent:Component{
query Global.Position[] as positions
query Global.HP[] as hps
public Global.HP as hp
public Global.Position position
fn update(float dt){
if input == 'B' {
for i in positions{
if(distance(position-positions)<10){
positions[i].x -= hp
}
}
}
}
}
2.2.6.1 组件组合不是理想的查询方法
在Unity DOTS中,按组件组合查询有两个好处:
- 最大的好处是直接获取数据,因为System需要操作这些数据,所以直接声明这些类型就不会出错
- 然后才是在这个基础上,将组合定义为一种特定的逻辑类型
目前看起来形成这套机制的核心原因是因为前者;但是这种组合本质上不是真正的查询条件,他可能导致一些意想不到的结果。
因为一个Component能被多个System使用,就说明Component本身可以具备多个意义,例如两个不同的System有可能完全按照相反的逻辑去处理,在这种情况下,用户定义一个Component有可能刚好不是某个System期望的方式,然而最终它还是被当作了查询条件。w
2.2.6.2 显式声明
还是需要某种显式声明的类型,哪怕是Layer这样
感兴趣的数据+TAG数组(多个TAG感兴趣)
只需要声明自己感兴趣的数据就行
由于数据无法表达类型,有用户手动设定
可以像Unity一样定义一个Layer列表,方便用户对对象进行归类
Unity的Component 组合查询反而不好理解,太复杂,需要记忆更复杂的东西,相比Tag,tag概念足够简单
- 只要能任意查询,就可以满足通用性
- 符号表满足任意组件间通信
- 组件语义化
2.2.6.3 RUST ECS
You can use empty structs to help you identify specific entities. These are known as "marker components". Useful with query filters.
/// Add this to all menu ui entities to help identify them
#[derive(Component)]
struct MainMenuUI;
/// Marker for hostile game units
#[derive(Component)]
struct Enemy;
/// This will be used to identify the main player entity
#[derive(Component)]
struct Player;
2.2.6.4 Labels/Layers
2.2.7 Component + System
Unity将Component和System区分开,主要是为了将代码和数据分开,使得System中不包含任何数据;即System本身也不能有任何实例数据,因为那样相对于它需要处理的Component而言,其中存在了“全局变量”,这引入了实体间的相关性,耦合,并使得很难定义每个Component之间的状态。
但这也带来了不好的后果:
- 使用者需要分别单独添加Component和System
- 并且使用者必须很小心处理它们之间的关系,比如你定义了Component,但是如果你的系统没有添加相应的System,则数据可能没有用处,这些实体没有任何行为定义;反之,如果引入了System,但是场景中根本就没有对应Component对应的实体,则这些System也无法发挥作用。
Creation同时解决了上述两个问题,方法是将两者融为一体,但是通过编译器将属性抽取为Component(当然Unity也存在类似的转换机制);更进一步,Creation通过public、private和query标志符区分了公共变量、私有变量和引用变量,使逻辑更清晰。
除此之外,Creation和Unity在功能层面是一致的。
2.2.7.1 组件执行顺序
由于多个未知的程序可以对实体执行操作,所有很难保证顺序的正确性,这比Unity DOTS要复杂,后者由单个开发者开发所有组件,能够严格保证逻辑顺序。但是RealityIS中,同一个实体可能包含来自不同开发者定义的顺序,可能会完全冲突的。
如果允许用户自行去调整执行顺序,会一下子对用户提高了很多要求。
但是我们仔细去分析一下一般的情况,如果能够在做一下假设或者约束,那么问题就会简化很多:
- 1,所有对属性只读的组件都放在最后执行,所有对变量只读的组件之间不用关心任何顺序
- 2,所有对属性可写入或者只读的组件之间都顺序无关
或者更进一步,我们假设:
- 3,每个组件只有一个可写入属性
这样整个问题就可以非常简单地被处理,虚拟机动态调整组件的执行顺序,并且不需要用户或者开发者在关心任何顺序相关的事情。
现实中,这三个条件还是比较容易满足。其中对于第3条,这就有点像函数式编程,每个组件是一个 函数,该函数只有一个输出值,并且所有输入参数都是只读的。如果每个组件只有一个可写入的属性,那么就很容易区分出所有只读和可写入两大类组件。即是说,第三个假设可以把所有组件分为两类:只读的组件和只写的组件。
然而即便如此,还是剩下两个问题:
- A和B组件对两个属性交叉读写
- 只读或者只写属性之间由依赖关系
对于第一个问题,在对组件进行自动排序时,将无法推算实际的计算顺序。有两种处理方法:
- 一种是遇到冲突时交由用户来指定,但是由于组件的顺序是全局的,而不是根据用户设置来的,例如两个用户可能设置了相反的顺序,所以这种方法不可取,并且它需要用户介入。
- 第二种方法是由开发者来解决冲突
首先,开发者是最了解逻辑的,而且开发者一旦解决好冲突就不需要用户在做不必要并且增加复杂度的设置。可以把所有代码看成一个整个,当开发者在提交代码的时候,并不只是要考虑自己的代码冲突,还要考虑全局代码冲突。两个开发者提交代码总是有时间先后顺序,所以可以对于后提交代码的人,系统抛出所有可能与之冲突的组件。有开发者通过了解冲突组件的功能,并比较自己组件的功能,来设置依赖关系。
当然这种方式也不是完全可靠,例如开发者可以根本没有看对方组件的功能,随便设置了一个顺序,这时候可能导致错误逻辑。一种可能的方法是,对这些有冲突的组件,后面开发者的设置 结果会发送给前面开发者,前面开发者可以对执行顺序提出异议或者同意。
对于上述第二个问题,分三个层面:
- 开发者尽量避免编写这种在一帧之内有复杂依赖的组件,比如如果组件之前都完全没有依赖,那就不会存在这个问题
- 另一方面,具有这种复杂顺序的组件,通常对应的是一个开发者内部的逻辑,这时候它自己设置正确的顺序就好
- 对于组件之间的这种可能性,大多数情况下没有意义,可以不用理会,由用户自行发现问题后反馈给开发者协商处理
2.2.7.2 Change-driven update
事件表的意义:
- 通过建立事件队列,延迟到一起执行,消除一定程度的并发,同时能够做到并行计算,因为一些相同类型的事件可能对应相同的组件,即使同一个事件对应不同的组件,通过按组件类型排序和组织,也能学到按顺序并行;
- 将一部分由状态变化导致的分支转化为事件序列,当然实际处理机制可能不一样
数据库重组涉及更新符号表、以及Table的数据重新调整,符号表和Table API一样,需要符号表API
2.2.7.3 ECS
Unity中ECS的system 只有一个实例,它跟Component 之间的联系由System 对Entity的Query定义,但是带来的结果是系统初始化的时候需要独立完成两个操作:
- 设置每个Entity的Component
- 实例化所有系统会使用的System
这种弱关系的一个可能的结果是有些System 可能查询不到任何具有感兴趣的Component ,而且系统没法自动计算,只能由开发者手动加载
此外,这种System 对Component 类型的确定性引用,使得程序很难动态构建新的场景
而且关键是普通用户很难去理解上述两个操作之间的关系,例如:
- 如果用户给一个Entity 添加了某个Component ,但是他很难比较明确地要去再添加哪些System ,这可能需要类似于给一个对应表,而这种对应关系可能有很多
- 如果用户按照System 的功能描述添加了某个System ,他又可能忘了要给一些Entity 添加对应的Component ,程序没办法检查这种情况
- 此外,更严重的,System 的定义和开发必须了解Component 的定义,这就回到以前的问题:Component 需要协议,这很复杂
实际上System 和Component 是严格相关的,他们分开没有意义,在OOP中它们就是定义在一起的,在一起可以避免需要做两个独立看起来不相关的操作,但实际上是相关的
所以还是需要和在一起,使用全局符号表,但这带来一个新的理解上的问题:
System 全局应该只有一个实例,但是随着Component 一起加到一个对象,使得看起来每个Entity 对会执行这个方法
但这问题是否也不大:
- 对于内部组件,他本来也是需要每个对象执行一次,在ECS中只是我们强调并行,其中一份代码对多个数据执行,而隐藏了System 其实对每个实体执行的感觉,但是在内部其实是循环,所以本质上是那个实体都要执行
- 对于特定实体遍历其他实体,他其实也是那个实体都会执行,比如一个塔防游戏,那个炮塔都要遍历行走的怪物,看看是否在范围内,如果在范围内就对其造成伤害
- 对于全局的,那就更好理解,解释器保证全局只有一个,那么就是该实体执行了一次
到这里主要的问题在于,对多个实体的遍历往往带有一个条件形成分支,并且那个并行的组件A内部都在单独访问所有实体,又可能造成:
- 并发冲突,多个线程同时访问同一实体
- 内存局部性破坏,每个组件分别访问不同的数据
针对上述问题,解释器要把第二种情况的执行转换为一个一个组件A顺序执行,在每个顺序执行的组件内对感兴趣的数组进行并发计算
或者更好的方案,对所有感兴趣的实体数组,并发地安顺执行组件A对应的实例
这就是解释器的好处
当然,对于第二种情况,由于System 看起来可能被构造多个实例,所以需要解释器只构造一个实例,并记住哪些组件引用了这个实例,也就是在Unity中为了支持Entity的Query,他也需要实现一个数据库来记录这些引用关系,即使针对第一种和第三种组件也是一样的
2.2.7.4 ECS参数
基于Component 组合的方式改变了传统编程模型中的参数传递机制,传统的编程模型都需要参数传递,不管是:
- 通用编程语言
- 可视化编程语言
- 声明式编程
- HOUDINI 程序化编程
一个System 处理数据,这些数据可以分为:
- 内部定义数据,在对应的Component 中,内部定义通常用来保存帧与帧之间的内部状态
- 外部引用数据,定义一个全局较大的公共属性名称,每个名称有特定含义,仅有引用的名称才会动态组合成所有的数据,这些机制靠编译器来处理,全局属性表之间可能有依赖,编译器自动引入;如果一个插件开发者或者Creation开发者编写的组件需要跨系统引用,需要定义私有名称列表
Global Name
Private Name
这样一来,Table Engine 所做的大部分操作就是进行数组的生成、初始化、复制、排序、修改、SOA等,这部分通过原生的高效实现,通常Table是动态生成的,不知道维度和长度等信息,这就是Table要做的事情
Global Name中的每个属性名称都是具有语义的,相当于宾语,而每个System引用的Name都可以追踪,因此可以归纳出System大致的语义结构:
在什么条件下做什么事情,条件通常是Global Name中某个属性的值
条件 主语 谓语动词 宾语
如果$NAME<5 System 由System开发者填写,可以多个 Global Name
数据很少是只有一个System 单独消费,通常是多个System 会共享一些component 数据,例如物理引擎组件、动画系统或其他组件会修改位置,而渲染组件会使用这个组件进行渲染
一种常用的模式是:
- 一个或多个组件对某个数据进行修改,通常表现为读写
- 通常一个或者少数几个组件对数据进行消费,通常表现为只读,并且使用目的通常是为了给用户反馈,或者写入到系统或者进行数据存档
由于多个组件会访问数据,因此为了避免数据重复定义,有必要定义一个比较大的标准数据和对应属性名称:
- 其他系统通过引用使用
- 每个系统仅使用部分数据属性,通过显示声明引用
2.2.7.5 组件之间的通信
两种机制:
- 事件,参见2.2.7.2节,本质上是状态处理
- 直接调用,就是正常方法
2.2.7.6 单例组件
有一类组件,只可以添加到Root对象上,它不可以被添加到任何自定义实体对象上。这可以用来处理一些特殊情况。
2.2.8 消息通信
用户间通信的情况或类型有几下几种:
- 读取和感知,这是最基本权限,让别人可以了解一些你的属性,状态 ,甚至性格,以及可以怎样与你进行交互
- 交易,所有用户之间的涉及修改的操作都是一种交易,你必须消耗某种类型的资源,另一方获得某种类型的资源
暂时不开放那种会对其他人造成破坏性的功能,例如攻击别人,也就是Reality World没有暴力,没有坏人,没有破坏。
但你可能会因为经验不善而破产,例如地皮是需要租金的,因此你必须赚钱,否则你就没有收入。
当然最好的机制是你的创造力越强,付出的时间越多,收入越高,相比传统的模拟经营游戏主要 依赖于时间,这里我们更强调创造力,其实也是现实世界的能力。
2.2.8.1 系统机制
但现实世界有一些全局行为,例如天气对全体城市人员的 影响 ,例如政府的政策等,这些后续再考虑。早期是一个单纯的交易系统。
组件之间的消息通信大概可以分为两种:
- 基于ID:在组件内保存组件ID,然后直接发送只特定的一个或多个ID,就像Erlang中那样
- 基于类型:使用类型+UserID进行判断
前者的机制其实类似面向对象编程中的机制:首先你需要取得另一个对象的引用,然后你就可以向其发送消息(调用函数),当然Erlang使用Pid耦合度更低 一些。但耦合仍然是存在的,例如对方函数签名修改了,或者甚至删除不存在了,或者PID被修改了,都是可能引起问题的,程序开发者需要去小心地维护这种关系和结构。
RealityIS采用的是基于类型的机制。
基于类型的机制相对于基于ID的机制会引入一个新的问题,即 N:N的关系,基于ID的机制本质上是1:1的关系,其1:N的关系也是按顺序一个一个发送的,这些发送消息本身也是按顺序串行的。
首先介绍两种常见机制:
- Unity机制:Unity的System并不是单个组件的计算,它本质上要求开发者维护集合操作结构,那么对于N:N的问题,开发者自己编写两个嵌套的循环结构就可以了,但问题是每一个System都需要编写这种循环控制结构
- Erlang机制:尽管Erlang的发送消息是1:1的,但是接受消息确是N:1的,Erlang的机制是对每个进程使用一个邮箱存储一个消息列表,但是开发者并不需要感知到这个消息列表,开发者编写的还是对单个消息的处理,但要求开发者主动编写一个获取消息的操作,然后每个receive的操作就会被分配一个消息,直至邮箱中的所有消息被处理完毕
显然Erlang的机制对开发者更友好一些,但对于消息的发送方面,由于基于类型的过滤,一个组件间接多同时向多个组件发送消息,而不是像Erlang一样让开发者维护一个PID列表逐个逐个发送,因此需要运行时将这个发送的过程形成一次列表操作,来实现Unity机制中的外部循环,这样组件就可以避免引入列表操作的概念,而专注于逻辑。
在RealityIS中:
- 发送消息的逻辑是通过读取组件属性来实现的
- 处理消息的逻辑则是通过写入属性来实现的
这样就要求读取的组件属性不能超过1个,否则同时处理多个组件的消息就变得不可能,除非这多个属性同时来自于同一个实体。这也是一种过滤的条件,但是开发者可能不一定容易理解。
- 跨实体要求只读取一个属性
- 同一实体可以读取多个属性
不管怎样,发送者和接受者只能是一个实体。读取的所有属性组合构成发送者的过滤条件,而写入的属性组合构成接受者的过滤条件。剩下的问题就是Unity 也面临的问题,即单纯依靠类型过滤是不够的,需要另一个层次的过滤条件,就是用户添加的Type,但是组件开发者不需要考虑这个事情,因为这种特定的事情是由业务逻辑决定的。如果有定义,接受者和发送者必须手持相同的CID,并且只要其中一个拥有CID,它们就不能与所有不具备相同CID的组件进行通信,进一步,这种CID可以转化为公钥和私钥,避免被相同的CID进行通信,例如攻击者会尝试与所有CID进行通信,事实上他应该是默认方式。
2.2.8.2 组件安全
不能对其他人的Creation或者实体进行删除或者修改,理论上,对其他人的数据只能读取,所有的修改操作均是交易
- 私有
- 好友之间
- 所有用户(包括陌生人)
2.2.8.3 权限控制
每个公共属性,一般来讲,应该只有一个核心定义,其他的均是对它的引用,就像传统的编程语言中,对象只声明一次,因此它的权限也在这里被定义。
在Creation Script中,由于变量直接变成符号表,因此定义的概念被模糊,符号表之后的引用正确被保证,但是符号表的来源确实不清晰的,因此无法控制变量只能在一个地方被定义。甚至没法区分是谁“定义了”变量。比如,如果两个组件同时定义了一个属性,但分别使用了不同的权限控制,则可能产生歧义:
namespace ComponentA {
public readonly Global.HP as hp
}
namespace ComponentB {
public readwrite Global.HP as hp
}
当上述两个组件被添加到同一个实体了,权限将发生歧义。
实际上,这里由代码开发者来定义权限是不合适的,在传统的游戏开发中,为什么开发者可以定义权限,是因为开发者即是应用的拥有者,或者说开发者是按照拥有所属者的旨意或意愿进行设置的,所以不管怎样,开发者和应用Owner是同一人。
随着UGC或用户创作平台的兴起,这种身份的统一性发生了变化:开发者和应用Owner可能是独立不同的人,在这种情况下权限完全由开发者指定是不合适的。
但是,另外一些纯计算的数据属性,只有代码内部才会用到,并且用户不会关心,这些数据显然是应该由开发者控制的,而传统的编程语言中并没有区分这两种变量的权限:逻辑变量和公共变量或者用户变量。尽管开发者可以定义public和private权限,但是这种定义仍然有两个问题:
- 首先它的职责就不是为了区分用户控制与开发中间的区别,因此开发者往往不会有这样的意识
- 开发者定义的权限和用户Owner需求之间可能是有冲突的,因为开发者把权限设定之后就不能更改了,而实际上用户权限是可以发生修改的
- 两者之间的定义没有很强的约束性,例如理论上开发者将所有属性都定义为public都是可以的,而Creation Script保证public属性必须来源于符号表,这就是使得开发者会小心地区分。
Creation Script完美的区分了这两者的定义,并且可以实现用户的控制。
实际生活中,我们所属的东西是资产拥有者可以随便修改的,例如一个图书馆,用户可以设置它是否可以被访问,可以开启和关闭。传统的做法是把这些属性映射到一个数据表,然后由另一个程序去读取并修改这个数据表。这个流程非常复杂,增加了程序的复杂性,而Creation Script相当于是直接“修改程序”。
直接控制数据,甚至直接控制代码,是我们这个世界本来的形式。
2.2.8.4 时序性
见2.3.6.1节。
传统的分布式系统大多是响应式、异步的,它们单纯是通过消息传递来解耦进程之间的关系,但是同一个消息可能对应着多个响应者,这些响应者之间本身也可能存在依赖关系,因此这些复杂的关系不太容易梳理清楚,因此传统的分布式系统都默认不处理这种顺序,开发者需要自己小心地处理顺序。
然而实际上函数本身就是包含时序性信息的,例如你需要使用某个变量的值,这个变量的值的赋值语句必须限于使用这个变量的方法调用,而这个赋值语句很有可能就是另一个函数调用,那么就可以得出之前的函数调用顺序应该先于后面的函数调用。
当然上述的理论,这里有个巨大的缺陷,函数本身是一个与变量无关的方法,例如我在方法A之前调用了方法B,然后再在方法A之后也调用了方法B,那么A和B之间的顺序实际上是无法通过函数本身推导而出的。
但是如果我们首先确定了变量,并且这些变量在整个程序运行过程中的名字是不变的,所有函数要么以这些变量作为输入,要么作为输出,那么我们是有可能推导出函数之间的关系的。这种关系是基于变量的,而不是函数的,函数确定相关性,但是计算的是针对一个变量,它所关联的函数的顺序。
但通常这样就足够了,毕竟我们要保证的也只是变量的共享和并发问题,而不是要严格保证所有代码(方法)的执行顺序。
2.2.8.5 性能问题
最简单的分布式系统是传递消息,通常是以字符串的形式,这样的机制使得每次函数调用都需要对字符串进行编码和解码。
Erlang使用的信息通信,传输的是原生的Erlang对象,这些对象被封装成闭包的形式,整个上下文都被保存在一个内存中,其中的变量、函数、及其各自对象的作用域信息等。这样的机制避免了编解码,但是为了避免并发需要对数据进行复制,整个数据基本上是可读的。同时,因为这些上下文保存了类型及函数定义信息等,所以调用者与被调用者仍然还是需要被放在一起编译。因此缺乏可交互能力。
RealityIS通过共享符号表,使得可以从公共的地方获得类型信息,因此不需要放在一起编译。
同时通过赋值解耦的机制,将参数传递分开,因此天生去掉了共享内存的读取(通常是由于无序导致的),因此它可以直接传递数据对象,而不需要执行复制操作。整个程序几乎跟非并发的程序执行逻辑一致。
2.2.8.6 三种模式
如果我们把函数的输出限制只有一个变量,这也是大多数程序语言的规范,那么函数之间的调用有三种模式:
- 自己属性作为参数,其他对象属性作为返回值
- 自己属性作为返回值,其他对象属性作为输入
- 自己属性作为参数,自己的其他属性作为返回值
当然上述的划分也隐含地意味着参与函数交互的对象不超过2个。
通过这样的划分,我们就可以处理任意的程序调用:可以是主动修改别人的模式,也可以是被动消息通知的模式。
但这样的划分对于组件的执行顺序来讲,会存在一些干扰,使得可能没法计算出组件依赖关系,因为它们之间的关系可能存在循环。
一个简单的思路是,考虑到主动式修改的应该是少数,而且具有比较大的影响力,所以我们可以限定主动式(即上述第一种情况)的组件总是最优先执行,只有所有主动式组件执行完了才会执行其他组件,这个时候组件的顺序需要重新计算。
主动式计算替代了传统的消息列表机制,因为:
- 主动式计算总是被执行
- 主动式计算只与当前帧有关,不会缓存消息,实际上它都不需要消息列表,有点类似于传统编程中的立即调用,但是所有的理解调用是并行执行的。
由于主动式组件是在自己的函数内修改其他组件的变量,因此不需要缓存这种一次性的消息。
但是这种对外主动式写入的操作会导致并发冲突。Erlang为什么没有并发冲突就是它没有主动式调用,都是响应式的,任何对函数的调用都是转换为其他函数的消息列表,然后再其他函数内部去解决。
2.2.9 数据与存档
提供数据配置表,以及在脚本中访问数据的机制。
数据存储都自动发生,所以用户实体配置的数据都需要存档,但不需要用户指定。
2.2.9.1 数据配置
2.2.9.2 存档
将玩家的进度数据存档,需要存储至云端
2.2.9.3 不足
将数据跟对象管理起来,不足的地方是数据会随着对象的删除而删除,不像传统的数据是独立存储 在数据库中,删除对象并不会影响数据,然后可以有不同的逻辑把数据加载不同的对象上。这块需要有适当的机制。
2.2.10 通用性
2.2.10.1 独立类
独立的类定义和ECS是等价的,相当于把类的每个方法拆为一个组件,类的实例变量使用全局符号表共享,这样每个组件都可以读写;而Creation Script会区分组件内部和外部变量,因此把一些只有方法内部会使用的变量设置为私有变量,逻辑更加清晰;而传统OOP中,每个类拥有复杂的变量--因此复杂的状态,这些状态有些是表征实例级别状态的,而有些则只是内部两次Update之间的一些临时状态。因此这种划分使类结构逻辑更加清晰,我们能够区分和关注那些真正对外表现自身属性的状态变量。
理论上A和B组件可以完全不需要知道对方的存在,但这种完全无关的交互带来的一个后果是组件执行的顺序非常重要
- 编译器自动识别读写顺序,但这通常最多保证读和写之间,但是多个写之间也有可能有依赖,这种情况无法处理,所以还是需要依赖于后一种情况
- 手动标记执行顺序
2.2.10.2 没有返回值的函数调用
在A和B组件之间设置公共变量,如:
out Global.iHP as iHP如果是A调用B,即A需要向B传递参数,则A的order设置小于B,让A先于B执行即可,这样B执行的时候就可以得到A计算生成的参数
如果一个OOP方法内部有多个其他类的方法调用,则按顺序设置多个组件的order
总之,将OOP中的方法调用顺序转换为组件order的顺序
2.2.10.3 有返回值
- 如果B是辅助方法,可以设置为Library而不是组件的形式
- 如果B是实例,具有自己的实例变量,这个时候需要小心地将两者的方法调用关系拆分到两帧之间:A首先或者B上一帧输出的结果,进行计算,相当于B的返回值;然后A将参数输出,B执行的时候或者A的参数,并将计算结果存入到对用的输出参数;然后A在下一帧或者B输出的参数进行计算
当然,如果原来的OOP类特别复杂,就需要小心地进行重构,如果一个OOP方法内有两个即以上的实例间函数返回值调用,上述的方法就不行,需要对逻辑进行进一步梳理,比如如果是前后没有依赖独立的方法调用,则可以很好滴拆分
2.2.10.4 继承
继承通过组合实现
2.2.10.5 结构体
由于底层的Creation Table Engine需要保证数据是简单的数组结构,因为不能设置太复杂的数据结构,所以不支持自定义结构体,只支持基本类型和矢量等基本类型,其中Vector通过内部结构进行处理
当然其实组件的数据本身可以认为是一个结构体,如果两个组件之间需要共享多个变量,可以通过定义多个out参数实现,这就相当于传递一个隐式的结构体。
2.2.10.6 控制tick的频率
2.2.11 赋值与解耦
传统的赋值语句本身就包含了耦合,它由一个读取语句和一个写入语句构成,虽然从逻辑上来讲没问题,其中包含安全问题
- 读取语句引入耦合,原本我只想给资源增加一定的增加,我并不需要关心总量
- 写入是重写,覆写操作,具有破坏性
尽管程序中有+=操作,但是由于它与写操作是同一权限,能够执行+=操作的变量意味着可以执行写操作,因此仍然具有破坏性
需要将原值读取出来,进行一定的计算,例如加减计算,然后进行赋值,这使得原本对值进行增量的操作逻辑,很容易写到实体外部,即增量来源的地方,这种操作引入了不必要的耦合,因为增量实体根本不需要包含这样的逻辑,但是如果要隔离权限,开发者必须得写一个类似Add(delta)的方法
Machinations 的资源流的一个重要基础,它将两个实体之间的联系,即经济的流动,都看成是增量的,这样经济之间的流动过程中,各个实体就只需要关心自己的事情,然后输入输出一个增量就可以,这个增量本身对两个实体没有任何耦合
生活中大部分其实就是这样的流程,想象一下,你要取100元钱,银行直接给你100,而不是你让银行先把所有钱给你,你拿掉100,再把剩下的钱存回去,如果你在数钱的时候被旁边的人抢走了怎么办呢?
Creation Script 中,组件之间(即对外部变量)的修改支持:
- 增量式修改
- 并且一个组件之间多个修改保证原子性
这使得每个组件只专注于构造自己的增量,大大见减少耦合,并且不需要编写复杂的方法来实现增量修改
如果实在是需要依赖于总量进行计算的,这种少数情况可以先读取总量,计算合适的增量,再对其进行修改
默认增量与默认赋值相比,虽然能实现的功能都没有差异,但是它避免了大部分情况下的耦合,毕竟大部分操作是增量,而且在ECS中在Component 中不适合写方法
编译器也可以进行优化,系统生成更优化的代码,当然这个功能本身不是为代码优化服务的,它是为用户开发效率服务的,能够简化逻辑关系,让用户逻辑更清晰
2.2.11.1 去除直接赋值
剩下操作只有:
- 读取 .
- 增量运算,+=
其中读取操作主要用于:
- 判断资源是否够用,如果不够用的情况下,资源使用方可以方便显示一些提示信息
- 一些依赖于总量的增量运算,例如增加总量的10%
2.2.11.2 拉取还是传入
资源的两种流动模式:
- 流入模式,一般对应于收集资源,此时需要把一定数量的资源传入一个容器,而不是由该容器去拉取,因为它并没有一个拉取源,而是直接对容器执行一个增量计算
- 拉取模式,当我们需要消耗资源已完成某件事情时,通常由完成该事情的实体从资源容器进行拉取,该实体首先对容器执行一个减量计算(当然需要判断容量是否足够),然后执行自己的处理逻辑;
除了生产资源的源头,大部分逻辑都应该是拉取模式。这里主要的原因是耦合:如果需要资源变化的组件主动去修改其他逻辑:
- 这是不合理的,资源的变化组件不应该知道这些逻辑
- 这些逻辑是变化的,可能增加新的逻辑,那么这根本无法实现
所以,应该是由响应组件来拉取,如果某个值变化了,感兴趣的组件自行来读取值进行逻辑处理,这样系统可能随时增加对这些变化感兴趣的新的组件。
2.2.11.3 传递变化的增量
在传统的函数调用中,调用某个函数传递的参数通常是增量值,例如某个技能释放扣除多少血量。这个函数一旦调用完毕,则需要下一次释放技能的时候才会再次调用这个函数。
在OOP的做法是,一个大的函数体,有很多分支,函数首先判断输入,如果适配技能的使用,就进行技能释放分支,然后进而对实际的扣血的函数进行调用;如果没有输入发生或者没有进入技能执行分支,则后续的函数就不会被调用。尽管在这个过程中技能的扣血增量值还是被存放在技能对象中。
在RealityIS中,一切组件都是扁平的,意味着前面不会有这样的分支来阻挡前面的流程,所有组件默认都会被执行。为了实现功能,有两种方法:
- 每个增量属性都对应一个状态量,以说明是否需要执行后续的操作,这实际上是把OOP方法中那些分支转换为状态变量
- 动态增减组件,例如没有释放技能的时候就删除技能组件,这种在实践上很难操作
- 永远传递增量,例如技能组件,如果释放当做执行,修改值就设置为某个具体的数值,否则就设置为0,这样对后续组件没有实质性的影响,这里数值0实际上充当了一个状态值,他告诉后续组件该事件没有发生,但又可以让后续组件不需要处理状态,认为一直在发生。
第三种情况是最简单的架构,但是存在两个问题:
- 性能问题,这相当于传统OOP中那些所有的分支都被执行
- 每帧结束之后或者每帧开始之前,需要对增量值进行清零操作
前者可以通过配合change-driven的架构来实现,而对于后者,例如对于增量组件来讲,它对其他组件的影响是处于外循环,运行时可以在执行完所有被通知组件之后自动清零,这种情况下需要区分哪些是增量属性。
另一种做法是,让主动发生消息的组件自己维护增量值,这样就需要保证这类组件用于都需要执行,不受change-driven机制的影响。例如对于释放技能的组件,它每帧的监听输入,如果输入适配,就将增量设置为预设值,否则设置为0。这种方法应该是最简单的,不能给运行时加入太多逻辑的东西,而且通常发出事件的组件数量是少数的,例如大部分时间时间都是随时输入或者某些用户交互触发的,进而触发一连串的计算,如果源头不会传递,后续的很多计算也间接省掉了,就像OOP中的分支那样。但是相对于OOP,至少可以节省计算,但省不了内存。
2.2.11.4 同时支持拉取和写入
如果全部使用拉取,会存在效率的问题,并且拉取要求被影响着自行支持相关逻辑,这有时候不够灵活,例如已有的组件没有这个逻辑,如果新加一个组件主动去修改这些逻辑,那么修改会变得简单很多。
对于开放型可互操作的程序,也许这样的逻辑是合理的:
- 对用户权限内的组件使用主动写入的方式
- 对用户之间的通信使用拉取的方式
写入的方式倒是很好实现,比如通过writein或者writeout,运行时就可以推导出应该怎样处理。
但是同时支持双向的操作,有可能将使得组件依赖关系不可推导。这方面后续需要好好权衡。
2.2.12 符号泛型
编程语言中实现泛型来针对变化的类型进行自适应或者运行时解析,这些类型通常具有类似的处理流程或操作
但泛型本质上是编程的范畴,进一步,它:
- 一方面是为了节省重复代码
- 一方面是运行时推导类型,但运行时推导类型的需求往往是由于上面一条为了避免代码重复而导致的
- 当然也有单纯是为了支持变化的类型,或者类型作为变量,从这个角度,泛型的定义反而是为了这个服务
类型变量
实体变量
逻辑变量
public Global.HP as hp
public Global.Health as hp
将变量的逻辑映射与变量名区分,在保持逻辑不变的情况下,同一个组件可以处理不同的逻辑,这里“逻辑”本身成为了一个变量,用户可以将一个组件作用至不同的资源类型
传统的泛型要实现类似的功能则非常复杂,你需要把所有变量都转化为对象,并定义接口,然而这种接口非常难定义,因为同样的名称可以用做不同的逻辑,并且这种接口是容易变化的
- 但是数据是不会变化的
- 而且游戏中的逻辑通常修改的资源的数量是比较有限的,通常1,2个,或者3个,以上的很少了
一种不需要约定类型的泛型,只要数据结构类型匹配一样,并且这样类型的检查来源于符号表,而不是运行时
只针对简单结构
复杂结构体,里面的引用名称比较复杂,除非像Lua一样,按索引,但是索引又强调了顺序,顺序通常隐藏在逻辑当中,不过这个顺序倒是可以通过组件说明书说明
2.2.12.1 变量名称
符号表包含数据结构,只能定义结构体,结构体有名称,结构体中的变量也包含名称。
但是组件内部不能定义新的结构,而只能使用元组的数据结构,符号定义到组件变量之间的映射使用模式匹配。
Point
{
X = 10,
Y = 20.0
Z = 30.0
}
2.2.12.2 模式匹配
为了使符号定义与组件变量名称之间进行解耦,可以使用模式匹配。但不能使用传统函数式语言中的=符号,因为我们还是需要赋值符号,这里使用操作符as,但它的意义就相当于FP中的模式匹配。
注意,在Lua中使用索引值来避免调用者跟被调用者之间的耦合,但是这种方式不自然,还是需要引入模式匹配的方式,将值(内存地址)绑定到真正自定义的变量名称上。
CS中的模式匹配只在组件变量绑定时使用,其他组件内部不能使用模式匹配,称为符号绑定更有意义。
变量绑定必须来自于符号表,虽然用户可以替换,但也是替换另一个符号表:
(X, Y, Z) <- Point //read from
H -> HP //write to
通过模式匹配,实现了四个功能:
- 读:即使结构名字或者内部变量的名字不同,只要类型匹配,也可以作为参数
- 泛:可以将默认的Point符号替换为其他结构相同的符号,从而实现符号泛型
- 写:写入数据,不需要单独写入到变量,或者说需要构造数据结构
- 创建:除了获取变量及绑定之外,构造实体的时候,及Spaw函数可能也需要模式匹配。
2.2.12.3 组件内部无类型
实际上,类型主要用于不同类或者实体之间的交互,作为一个多变量的聚合方式,只需要传播单个类型变量名称既可以传递多个变量的值。
但实际上对于一个方法内部来讲,他要处理的全部是单个变量,多变量聚合的名称对于函数来讲没有意义,反而需要更复杂的机制去方法聚合体内部的变量,从这个角度讲,模式匹配简化了这种对实际内部变量的访问机制。
但它带来的不好一面,可能是构造实例的时候不能以一个聚合类型的整体进行赋值,而是需要对其中的每个变量都赋值,但是其实本来也是需要对每个变量赋值的。
2.2.13 并发
面向对象的无序相互引用,通常导致并发,而逻辑上他们不一定有并发,而且我们没有办法从逻辑上去控制这种并发的顺序,太复杂,完全无法预料对象之间以什么样的顺序和时机触发并发。
以组件为单位进行组织,能够更好地控制逻辑的顺序,从而能跟在逻辑上比较简单地避免掉一些不必要的并发
将共享变量和私有变量区分,私有变量不会触发并发,而共享变量因为从符号表引用,从而编译器能够有可能推导出组件对共享变量之间的依赖关系,比如能够把一些相互独立的组件并行执行
以对象为单位,那个对象执行的逻辑太复杂,存在不可预测的分支、跳转等逻辑,那个对象的指针引用可能导致不可预测的指令执行顺序和序列,因而无法很好地使用指令级并行,因此通常只能依赖线程级并行,但不可预测的混乱的对象引用关系将大大地导致并发问题
通过精心将同一组件的数据组织成数组,不光是能够控制逻辑顺序,从而避免一部分并发,同时将对象级别的线程并行转化为指令级并行,进一步,通过对依赖关系的识别能够更好地将多个独立的组件执行线程级并行,这里的核心是能够通过全局符号表和显式共享关系识别依赖关系
2.2.13.1 过程式编程
2.2.13.2 Erlang及OOP
2.2.13.3 适合游戏程序的并发模型
2.2.14 智能感知
当靠近一个物体,或者使用一个特定的探索命令的时候,如果其本身不具备识别对方的操作,可以动态查询对方的属性,然后动态提示是否需要安装新的操作脚本。
因为每个脚本需要用户手动选择,不可能自动安装所有脚本,但是系统本身是可以感知的。
比如购买一辆车,需要使用特定的购买方式等。
两个目标或价值:
- 动态移除:当一个场景中并不包含某个脚本可操作的实体时,可以移除一些组件,或者单纯略过这些组件(出于动态管理的复杂度),比如用户角色可能安装非常多的感知和交互组件,但是在某些场景中根本就没有可与之交互的实体
- 动态添加:有些类型的实体,例如一个广告物体,通常其本身并不包含全场景的机制,他们只是 临时体验
- 智能购买:让用户在试体验某个内容的时候,可以直接一键购买
2.2.15 交易与交互
所有用户之间涉及修改数据的的交互都是交易,当然其他的一般不具备破坏性的交互也可以,例如 读取 数据 。
2.2.14.1 HelpComponent
在一个未知的开放世界,很多东西都是未知的,当面对一个新的实体时,需要能够随时随地获取教程,说明怎样与之交互以及带来的影响
2.2.15 Components
2.2.15.1 NeuralComponent
2.2.15.2 TagComponent
2.2.15.3 RealityIDComponent
2.2.15.4 HelpComponent
在一个未知的开放世界,很多东西都是未知的,当面对一个新的实体时,需要能够随时随地获取教程,说明怎样与之交互以及带来的影响
2.2.15.5 DeltaComponent
参见2.2.11.3节。
2.2.16 最佳实践
2.2.16.1 more granular is better
Bevy has a smart scheduling algorithm that runs your systems in parallel as much as possible. It does that automatically, when your functions don't require conflicting access to the same data. Your game will scale to run on multiple CPU cores "for free"; that is, without requiring extra development effort from you.
To improve the chances for parallelism, you can make your data and code more granular. Split your data into smaller types / structs. Split your logic into multiple smaller systems / functions. Have each system access only the data that is relevant to it. The fewer access conflicts, the faster your game will run.
The general rule of thumb for Bevy performance is: more granular is better.
2.2.16.2 组件顺序
参见2.2.7.1节内容。
2.2.17 关于数据的本质
- 数据是不变的,但是数据结构是变得,我们可以把数据定义在任何地方,这就导致好像一个游戏的数据是不可空的
- 针对数据的操作与数据或者数据类型应该是解耦的,暂且称之为数据泛型
- AI编译器或者AI计算平台能够大力发展,模块化,很好的优化,是因为AI的数据结构特征很明显,或者抽象得很好
- 把数据抽象出来,才更容易看清逻辑的本质,比如易于管理,例如能够判断哪些逻辑可以并行,不然逻辑隐藏于一团乱麻之中,人和计算机都不容易识别其中的秩序
2.2.17.1 数据泛型
生活中,我们会发现,有些方法,道理或者逻辑,他们对许多不同的数据或事物都是相通的,我们可以把这些方法应用在不同的领域,比如一辆车子,他其实可以装任何东西,但是在程序员,一个对象所能处理数据却往往包含额外的类型信息,使得方法的处理不够通用
只要逻辑上能够保证合理,这个可以由用户确定,那么一个逻辑应该可以作用在具有不同意义的相同数据类型上,只要用户指定好输入输出
一种新型泛型
编程语言中实现泛型来针对变化的类型进行自适应或者运行时解析,这些类型通常具有类似的处理流程或操作
但泛型本质上是编程的范畴,进一步,它:
- 一方面是为了节省重复代码
- 一方面是运行时推导类型,但运行时推导类型的需求往往是由于上面一条为了避免代码重复而导致的
- 当然也有单纯是为了支持变化的类型,或者类型作为变量,从这个角度,泛型的定义反而是为了这个服务
类型变量
实体变量
逻辑变量
public Global.HP as hp
public Global.Health as hp
将变量的逻辑映射与变量名区分,在保持逻辑不变的情况下,同一个组件可以处理不同的逻辑,这里“逻辑”本身成为了一个变量,用户可以将一个组件作用至不同的资源类型
传统的泛型要实现类似的功能则非常复杂,你需要把所有变量都转化为对象,并定义接口,然而这种接口非常难定义,因为同样的名称可以用做不同的逻辑,并且这种接口是容易变化的
- 但是数据是不会变化的
- 而且游戏中的逻辑通常修改的资源的数量是比较有限的,通常1,2个,或者3个,以上的很少了
一种不需要约定类型的泛型,只要数据结构类型匹配一样,并且这样类型的检查来源于符号表,而不是运行时
只针对简单结构
复杂结构体,里面的引用名称比较复杂,除非像Lua一样,按索引,但是索引又强调了顺序,顺序通常隐藏在逻辑当中,不过这个顺序倒是可以通过组件说明书说明
2.2.17.2 接口、协议、参数、数据
接口是用来保证类之间协作的协议,这个协议没问题,它保证相互协作
但是在编程语言中,除了协议,它还多了一种身份,充当类型,类型被用于帮助语言进行检查,保证程序的合法性
但这是编程语言的需求,实际上并不是协议的需求,比如,在现实中,A和B协作,它们都会自己遵循一种第三方标准,A和B之间事前不需要相互协商,它们可以与任意遵循标准的实体之间进行交互,就算A和B最终发现它们遵循的标准版本不一样,但是大多数情况是一样的
这里的特点有两点:
- 不同在于A和B事前完全互不通信
- A和B在大多数情况下都能相互协作
- 标准往往是来自独立的第三方
程序语言中往往需要引入接口声明,这种耦合不光是协议本身,还包含了很多协议外的跟程序相关的东西,例如特定的程序包、签名的顺序,甚至有时候依赖的顺序,更糟糕的是,还必须把这些内容插入到代码中
你必须从那个接口继承,而不仅仅是遵循一个接口协议
即使你有自己的方法做了协议一样的事情,这还不够,你必须把代码移到接口方法、包装一下等等,你的修改代码
在遵循协议之外,引入了一些额外的负担
另一个情况是:协议通常关注数据,你能把这个数据进行处理,比如我买了一种特定的原材料,我拿过来进行加工,然后生产另一种材料,卖给其他厂家,我们约定的协议是原材料的规格和品类,但不是我们加工的方法或者步骤,我的方法和流程随时可以变动,只要我输入和输出的规格不变
在程序接口中,本意也是关注输入输出的数据规格,这本可以仅通过定义数据结构即可,但是程序需要保证运行时对象初始化、变量赋值、变量的合法性等等各种原因,他把输入输出数据和方法放到了一起,这里面也有更重要的原因是实时性和顺序:调用方需要立即获取返回结果
这使得编程语言的协议约定的更像是方法而不是数据,又加上编译器的类型系统等原因,协议被深度耦合在系统中,增加了复杂性
CreationXR仅关注数据及其结构,并且通过游戏特有的Update机制也能保证返回值被立即取得,但是它弱化了对方法相关的依赖,而数据可以通过公共符号表定义,不管是基本类型还是聚合类型
这种解耦大大的简化了程序组织的复杂性、也增加了灵活性,例如可以随时增加感兴趣的数据,或者执行不同的逻辑,但其他部分完全不受影响
当然带来的一个新的问题是:这种隐式的参数传递导致组件的实际目标并不是很明确,因为它很有可能做了一些不可控的事情,这种需要对组件功能进行描述,就像一个产品说明书,他到底做了什么,这样的说明书是普通用户可以理解的,语义化的
2.2.18 游戏程序跟传统程序的区别
2.2.18.1 Update机制
Update是游戏的核心驱动力:
- 它既是形成动态世界的基础
- 同时又由于每个对象都在实时更新自己的状态,因此使得系统之间的解耦变得可能,即每个子系统只需要处理自己的状态
传统的应用程序只操作业务规则,没有实体化,他们通常面对的是数据,数据结构,这种数据通常反应的是规则,而不是对象得概念
2.2.18.2 程序大小与空间数据结构
传统应用程序的程序包大小都比较小,例如一个手机app只有几十最多上百M,但是一个游戏往往都多大几个G,主机游戏甚至几十到上百G。
不光程序包的大小,计算时加载到显存的数据量更是差异巨大 ,例如应用程序通常只需要加载少量有关的数据,常驻内存中的数据通常不多,每个业务逻辑相关的数据通常都比较独立,即使少量单个逻辑需要的数据量比较大,也仅需在计算的时候即使加载就像,传统的应用程序通常对实时性要求没那么高。
而游戏程序内的数据通常高度关联,且包含空间数据结构,所以往往数据会非常大,且大多需要常驻内存,使得现代游戏程序的显存往往是不够的。空间数据结构不仅意味着比一般的数据量要大,而且为了加速计算,通常还需要包含很多冗余的数据和数据结构来达到实时性。
当未来的虚拟开放大世界需要更大的数据,这些数据可能远远超出单台计算机能够承载的显存大小。在这种情况下,这样的大世界将很难有效地运行,需要新的技术架构来支撑这种扩展需求。
2.2.18.3 架构复杂度
2.2.19 状态机、行为树与AI
2.2.20 安全
如果要让来自不同开发者的程序可以在一个内存环境运行,以及来自不同用户的实体对象在一个内存环境中进行交互,安全性是一个非常大的问题。这里的安全性涉及两个层面:
- 代码bug引起的程序崩溃
- 代码蓄意破坏系统和他人数据
后面通过严格控制程序实例化对象来实现,通过Creation Script的机制,开发者:
- 无法分配自己的内存
- 无法访问指针
- 甚至无法构造类型
- 无法访问系统带有众多数据的结构,例如场景树
所有提供给开发者的接口都要保证用户和系统安全性
2.2.21 组合与依赖
2.2.21.1 相关参数聚集到一个对象
大量中间变量:将嵌套的函数结构转化为扁平结构,其代价是存在大量中间变量属性,尽管这些变量不能算是破坏了纯函数的结构,但是他们带来一定的干扰,并且大量的中间变量如果都存储起来,既是不必要的,也浪费内存。
此外,由于在RealityIS中组件属性并没有严格的所属关系,它不是由单个组件拥有的,也不是由单个组件定义的,这也是RealityIS的核心机制,所以我们也不可能简单地通过在属性上加入一些变量attribute 来声明属性是否应该被存储。
由于属性并不是在使用的地方定义的,即不是在组件中定义的,这跟传统编程也是一个核心区别,RealityIS属性定义的地方在符号表中,这是唯一定义的地方,所以我们可以把这些attribute 定义在符号表中,即只有符号表要求存储的变量才会被持久化,其他数据都认为是中间变量。
但是也不能为了持久化把中间变量都放到私有表中,那样就不具备跟其他组件通信的能力,全局符号表的主要目的之一就是为了互操作性,所有需要互操作的都需要定义在全局表中,到全局表也有不需要持久化的属性。
中间变量存在于私有表也可以,但是他可能需要关联组件,使得计算的最终结果是一个全局符号表中的属性。
2.2.21.2 关联组件
事实上我们是否应该要求私有表中的符号总是不应该持久化,这样就会更加迫使开发者针对公共可交互属性进行开发,否则开发的组件将没有任何用处。
这带来两个好处:1是组件不再于单个独立组件的形式存在,而且一个相关联的组,这样的组更容易管理,粒度更大一点,2是标准的地位更高,所以组件真正是必须依赖于标准,更容易管理,整个程序机制更容易理解。
对于一个组件,不管中间状态如何,他的第一个输入(或者多个参数的其中之一)必须是全局符号表,然后最后一个写入的属性也必须是全局符号表,中间的大量属性属于中间属性,来自私有表,不会被持久化,所有这一连串的组件成为关联组件,他们形成依赖关系,而所有相互依赖的组形成一个纯函数。
但一个组件组中的所有函数如果均是作用于一个实体对象,则他们可以合并为一个大函数,因为反正中间过程别人无法交互,所以没有必要拆分。
拆分成多个中间变量适合于:这些变量可能分布于多个实体的时候,或者说的输入来自于多个实体,这种情况必须要借用中间变量才能实现。
所以理论上说,只要输入全局符号参数大于等于2,就需要某种形式上的中间变量,来进行归并。
所以也可以定义一种重载的机制,如果某个对象同时包含了多个参数,可以减少中间变量的归并过程,可能会有一定程度的性能提升,但是对架构简洁性造成的代价可能有点大,带来编码和运行时的复杂度。
一个大的组件组由多个小组件组合在一起,这些小组件构成一个较大逻辑的复杂细节,而组件组则是用户进行创作的单位,组件组内属于开发者进行维护的单位。
如果开发者的组件是多个输入参数,来自全局符号表,则他应该知道只有同时满足这些条件的单个对象才能执行计算,否则他应该始终假设单变量输入的形成,通过中间变量组合。
2.2.21.3 组件顺序
2.2.22 分布式
2.2.23 异常
由于RealityIS将一些完整的操作分散到多个组件当中,单个缺乏原子性,因为它可能是与其他组件一起构成了整个完整计算。所以我们不能像Erlang那样采取丢弃单个进程的方式,因为在Erlang中一个进程崩溃了并不会影响到其他进程,而且Erlang单个进程的任务比较独立。而RealityIS中某些组件崩溃了,意味着前面某些计算也需要取消。
因为RealityIS将采取非常不一样的异常机制:
- 如果一个组件崩溃了,整个该帧的所有计算都需要丢弃
比如采取响应式,如果一个炸弹爆炸了,但是后续对炸弹进行相应的组件却崩溃了,这个时候前面的炸弹就无效了。如果是一些其他更重要的逻辑发生,这样的影响就会非常严重。
当然传统游戏的做法是,当一个地方导致程序崩溃了,游戏会从一些固定的存档节点恢复,玩家需要从那些固定存档重新开始玩,这可能会带来一定的重复。
重复肯定是必须的,问题是对于一个没有关卡的开放世界,它的存档节点是非常复杂的。系统需要一套自动化的存档机制。
2.2.23.1 自动存档
构建一个存档机制,然后崩溃之后提示用户退出,并自动回退到上一个存档快照状态。
另一个情况是,尽管很多用户共同在一个开放世界运行组件,但是大部分组件之间的通信还都是在RealityID之内的,所以一般情况只需要退出单个用户即可。但也有可能某个跨用户之间的通信会影响到多个用户。
因为内容是由普通用户创建的,所以需要避免传统游戏设置的专门的存档节点的机制,原因是:
- 普通用户很难有这样的能力,存档往往是要打开程序的结构的,增加复杂性
- 开放式的世界其实很难设置存档节点
但每帧存储肯定代价值很大的,所以也要避免每帧存储。
2.2.23.2 检测存档属性
当属性定义为存档属性时,如果其值发生了改变,理论上这些修改都要存储起来。
比如玩家在攻打一个Boss,这其中需要花费大量的精力,通常几分钟甚至十几分钟,这期间Boss会有很多状态变化,玩家的动作、动画状态、行为树等等也会发生很多变化、环境中的树木也可能临时被炸掉等等。但其中除了用户使用的技能道具等,其他大部分数据都不要存档。
Boss战存储的更多是一个大的结果,这样当其中出现崩溃时,玩家可以重新打Boss。
2.2.23.3 属性独立存档
对于实体对象的属性数据,可以不采用传统的属性结构进行存储,因为那样就会存储到一个文件,使其存档时会发生并发。
因为其实体对象属性本身是Table结构的,所以我们可以向内存访问一样,每次修改一个属性之后,这个属性利用虚拟内存系统自动存储到硬盘,然后等玩家退出或者程序崩溃的时候再统一存储到用户的数据存储服务器。
这样所有实体对象在云端存储的也是Table,不必存储到一个USD文件中。实际上在内存中它们也不必存储到一个数据结构,例如一个树形的数据结构。只有这样才能保证分布式计算。
将一个IO拆分为多个IO,可能会带来一定性能损失,但是考虑:
- 单个IO或者少数IO只能采用少量线程,如果是大文件解释也会很慢,没法有效利用多线程加载
- 现代NoSQL数据库对缓存,某些查询做了大量的加速,效率要大于单纯的文件或数据区查询
总之,这可以利用到多线程的优势,又能保证分布式。
2.2.23.4 存储时间点
总的来说,有两个存储时间点:
- 用户退出应用时
- 用户的某个组件进程导致崩溃时
CreationVM会包含两份数据:
- 一份是所有组件的运行时数据
- 一份是所有组件的存档数据
当运行时组件修改了某个存档属性,这些值会被记录在内存中。开发者和运行时应该保证一旦这些值被修改,其之前的操作都是合法的、原子性的、不可修改的。所以这些数据可以被随时写入到用户真正的数据库文件中。
只是因为频繁写入数据库的IO操作,我们选择在一些关键事件发生时在写入数据库。在这种机制下,如果CreationVM机器本身崩溃,有导致有些属性没有被存档,因此下次用户需要重复执行某些操作。但是这并没有太大问题,游戏玩家已经习惯这种机制。
基于上述的机制,当用户组件进程发生崩溃时,由于CreationVM的存档属性并不包含一些中间值,所以所有这些都不会被写入到数据库。反之,CreationVM接收到崩溃通知之后,会立即将之前的存档属性写入的数据库,并写入崩溃日志。用户退出应用时也是同样的逻辑。
该机制的成功运作需要开发者和运行时协同工作:
- 开发者要保证当对一个存档属性进行修改时,之前的所有操作都是合法的,运行时可以放心存储这些数据
- 运行时需要保证,如果组件在存档属性的修改之前没有任何问题,那么运行时需要保证对存档属性的写入应该也不会出现问题
所以,一个组件的返回值应该始终位于函数的最后,不能再中间返回,或者对返回值对象赋值,或者写成以下方式更好:
(x, y, z) = Global.Position
Global.HP = map() {
...
x + y + z
}
最后一个字句默认是返回值,不需要return关键字,它返回的值会赋值给Global.HP,这里仍然通过模式匹配,使开发者不需要去关心Global.HP的内部结构。同时省掉了一些声明,如果跟输入变量一样的声明形式会多写一些无用的代码。
2.2.24 组件属性
.Component(name) //组件文件名和名称
.UseDt(true) //是否使用dt参数,一般用于动画或者跨帧行为
2.2.25 数据和组件之间的关系
数据和逻辑是程序的两个最基本元素和概念,有了这两个基本元素,我们基本上就可以编写任何程序。
2.2.25.1 大规模程序构造方法
然而,真正的软件规模是非常大的,它往往是由众多的开发人员(这些开发人员甚至可能在地理位置上完全隔离)开发的几十甚至上百万行代码的组合,这种规模的软件程序显然不可能仅由简单的变量和函数构成,那样的话我们将很难无管理错综交织、复杂的数据和函数引用。
为此,编程语言的设计者在数据和方法的基础上,添加了大量的抽象机制,例如类型、数据结构、继承、多态、重载、接口等等。这些机制的目标是要形成各种抽象,使得:
- 其他人员可以不需要关心一些实现细节,只需要关心与之交互的部分,即接口;
- 当然除此之外,这种抽象也是帮助开发人员自身从逻辑上更好地管理自己所编写的众多代码。
所以现代编程语言的发展,本质上都是在解决大规模软件构造的问题,现代编程语言主流的两种软件构造思路是面向对象和函数式编程。
2.2.25.2 数据和逻辑和问题
参见2.7.13.3节,RealityIS中的实体对象代表的是逻辑,即复合函数,因此实体对象从概念上仅包含逻辑,不包含数据,这也是简化用户组织逻辑的关键,即用户不需要关心数据,关心的仅仅是功能。
那么数据在哪里?以及数据是什么样的概念?
如果说数据被隐藏起来,它在哪里以什么形式存在呢?从用户层面来讲,表面上看数据仍然是附着于实体对象的,因为用户添加了某个函数或者复合函数之后,实体对象将会显示相应的参数,用户需要知晓这些参数来了解函数之间的逻辑关系。
但这些数据本质上是不需要用户管理的,RealityIS认为,所有数据都是用户数据,即所有数据是一个用户的巨大数据表,当我们创建一个实体对象以实现某个功能时,我们实际上是对这个大的用户实体对象中的某些属性进行修改,而从数据表中查询和写入数据的操作则由系统完成。
当然实际上并不是运行时动态从数据表中查询数据,那样就变成传统的面向数据库编程的模式,我们实际上是根据对象组件与数据之间的关系,在初始化的时候从数据库中找出这些数据,并按照对象的形式分散存储在内存中的各个位置,整个运行时的行为实际上跟传统的面向对象编程,更确切地说ECS的内存布局是类似的。
这种看待和处理数据的方式,是RealityIS与传统编程模型的巨大差异。
2.2.25.3 基于组合的构造方法
\2. “有”和”能”和实现
在组件模型中,对象由组件组成,所以其行为也由组件主导,例如一个对象拥有[Movement] 和 [Location],则我们可以认为它能够移动,这在整体上是十分和谐自然的,但当我们仔细考量,这个"能"是由于什么呢,是因为 [Movement]吗,是因为[Location]吗,还是同时因为 [Movement] 和 [Location]?当然是同时(这里便揭示出了组件和接口的展平对象方式是正交的),那移动的逻辑放到哪呢?答案是放在这个“切片“上。但在实际项目中会看到把逻辑放在 [Movement] 上的做法,这两种方式都是可取的,后一种拥有较为简单的实现并被广泛采用,而前一种拥有更精准的语义,更好的抽象(后一种种方式中 [Movement] 去访问并修改了 [Location] 的数据,这破坏了一定的封闭性,且形成了耦合,当然这种耦合也有一定的好处,如避免只添加了 [Movement] 这种无意义的情况发生)。
作者:BenzzZX 链接:https://zhuanlan.zhihu.com/p/41652478 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.2.25.4 数据是二等公民
2.2.25.5 组件是一等公民
2.3 Creation VM
跟引擎高度一体化,不是独立的虚拟机
2.3.1 Creation Table Engine
Table Engine维护一个Database,主要目标:
- 构造和存储所有基于Data-driven的数据,包括Component的数据、事件列表、Hierarchical Level数据、行为树/状态机等结构,所有数据都已数组的形式组织。
- 对Table数据进行新增、删除、修改、排序等操作。这些操作都需要延迟到Component进行后统一进行处理,而不是立即处理。
- 对于Component的数据,由于所有数据混在一起,需要按照ArchType进行组织。并且块元素的大小进行自动计算。
提供一些标准编程案例
虚拟机的设计:
如果数据都是Table类型的格式,那么动态需要的虚拟机可以设计为处理原生类型,所有Table数据的分配和管理都交给系统层,这样脚本需要生成的代码也为“纯代码”,这些字节码对应的操作数地址的分配则为C++层的编译型代码,而不是动态解释
避免了脚本语言复杂的数据地址分配:例如构造虚拟寄存器或者虚拟栈,以及对应为了构建虚拟寄存器而构造的符号表以及符号表的解释映射等
所有的代码,在虚拟机这一层都是转化为对table的某种操作,这些操作都封装为基础的C++层的代码,自动就处理了内存地址的分配
要拆解Table的基本操作,也就是STL中基础Vector的基础数据操作,应该能够提炼出所有可能的基础操作,然后封装为虚拟机层的高级基础指令
这样整个Table Library 就是一个类似STL的库,它封装一些特定的Table的操作类型和操作方法,面向数据驱动的整个架构,既支持原生C++调用,也支持虚拟机基础指令封装,这就好比Lua的某些方法由C实现,只不过这里的C操作是更低层的操作,并且这里的数据由C定义和分配,而不是像Lua一样由Lua分配再传给C,所以这里脚本语言的定义语言处理特殊的变量操作,例如脚本语言中对变量的使用都翻译为对C对象的使用,没有变量复制,没有数据只有指令
如果脚本语言中不含结构声明,或者没有自己的结构体,只有简单变量,那么整个解释过程是不是会快很多
2.3.1.1 数据存储:数组
为了实现每个组件的单独编译,首先组件访问的数据得是独立的,另外这些数据的布局得是固定的。
对于组件需要访问的每个变量,使用指针的方式是非常复杂的,因为这意味着虚拟机需要动态给每个组件中的每个地址赋值,这几乎是不无做到的,因为虚拟机只处理规则的内容,通用性的规则,但是每个组件对数据的访问确实不一样的,除非是解释器或者虚拟机自己分配的内存,但是这里一个实体的组件的数据不是由组件代码自己分配的(你如传统的寄存器寻址,就是解释器或者编译器直接针对代码设置好寄存器地址),而是由Creation Table自己分配的。
为了实现这种分离,组好的方式就是将组件访问的数据放在一个连续的内存地址中,然后:
- 虚拟机只要动态将起始地址传递给组件,这种规则是通用的
- 解释器将每个组件中的寻址转换为基于相对位置的寻址
这有点像虚拟机中执行函数调用,当然这里只采用栈式方法,所有函数需要访问的变量存储在一个栈中,函数按索引对栈中的内存进行访问。
2.3.1.2 无类型定义与垃圾回收
只有组件类型,组件只有数据,没有新的结构体定义,全局符号表中有一定的基础数据结构,但是其他的数据结构均有组件的数据定义隐式决定。
由于类型定义在脚本语言中,并且是按照单个组件的类型进行定义的,即AOS(array of struct),两个原因 :
- 第一并不利于高性能 计算,高性能计算需要是SOA的形式
- 其次,底层虚拟机并不了解组件的数据结构,导致不能动态构造对象;因此需要在脚本语言层面直接构造对象,这样脚本语言就需要实现复杂对象,及其相应的垃圾回收机制;
对于上述两个问题,Unity使用了离线编译的方式,将组件数据的构造转换成了另外某种形式的中间代码;这样使得可以SOA的形式进行 数据管理,但是它 可能不支持动态更新,或者至少需要动态更新整个编译后的中间代码?
当CTE试图将 上述过程放到运行时动态解析时,性能是需要重点考虑 的事情:
- 单纯A OS->SOA的开销
- 以及当场景中有 大量对象时 ,这些对象之间的数据关系等等的判断可能会非常 消耗时间
所以需要好好划分阶段,并把部分数据是否可以提前计算出来,例如对于一个Creation:
- 首先确定它引用的所有变量及其组合关系,这部分是否可以预计算成 某种格式,即是计算ArchType的时间,这些可以 在云端下载 资源 的 时候计算 好,下载时动态计算。
- 然后运行时首先就可以根据这些关系初始化数组
- 如果涉及用户在端侧编辑数据,则针对每个对象动态修改 ,但此时应该不会太影响性能。
因为这种AOS->SOA的转换,使得上层脚本语言定义的对象可以在虚拟机上进行初始化,从而减少脚本层面的复杂度,并使得原生语言 管理对象性能更高效。而这种转换机制背后的核心因素是两点:
解释器动态识别组件定义的数据结构,并从中提取属性及其符号
以及底层ECS的机制将这些属性转换为SOA数组,由于整个CTE都是已知基础数据类型的数组,所以间接地不需要关注上层 脚本实际的数据结构,每个元素按照索引进行寻址即可。
整个Table中没有任何未知Struct对象,所谓未知即是用户定义的struct。这里面的核心就是解释器动态对变量的内存地址进行重新映射,通过数组索引+基础变量类型,就能计算出正确的索引位置。因为数据在内存中是没有struct的概念的,struct的作用在于帮助编译器或者解释器计算内存中的索引位置。
当然,我们不能支持用户端自定义struct,否则虚拟机无法识别,就需要复杂的机制来识别结构体。由于游戏的特殊性:它能够将所有数据通过ECS的机制转化为Table,所以我们有就会去除掉结构体或者相关的类型解析,变成更简单的索引计算。
当然,为了考虑性能,这里可能需要考虑AOT的机制,即提前将索引的计算转化为中间形式,不然每次要通过虚拟机中的索引映射方法来动态计算索引,性能开支就会比较大。但是由于这个索引是跟运行时的动态相关联的,所以需要在对象的创建/修改/删除等环节进行重新动态计算。
2.3.1.3 运行时内存管理*
尽管Table中的数据在不断变化,但是这部分的变化在某种程度上跟垃圾回收的思路类型,例如:
- 当某段连续的内存不够时,需要重新度数据的布局进行调整
- 当某写对象不再使用时,垃圾回收器可能需要对某段内存数据进行擦除
- 记录对象之间的索引,关系等等
因此,这部分思想可以参考垃圾回收的一些思想和算法。
2.3.2 Add、Remove
对数组的操作一般由Component发起,但是不能立即对Table进行修改,因为其他Component正在访问这些数据,这些修改需要延迟到Component和其他操作执行完毕,需要使用诸如缓存队列之类的架构。原则就是:
- 数组结构的修改需要单独不理,不能影响当前操作
2.3.3 Change-driven Update
在每一帧中,每个组件通常做三种类型的事情:
- 不做任何判断,把整个逻辑完整执行一遍,哪怕其中涉及的数据没有任何变化(因此结果也不会有任何变化),这种计算策略是非常浪费的,但是它确是管理成本最低的方式。
- 第二种类型包含逻辑判断,因此一部分计算指令集于某些属性值的不同可能不会被执行
- 第三类是包含一些需要跨越多帧执行的逻辑,例如动画,它们通常只执行一段连续的时间,在这段时间里,由于属性数据都在发生变化,所以它需要像第一种方式一样完整执行;但是一旦这段时间结束,它可能就不再需要被执行。
对于第一和第二种类型,理论上它们都可以归结为一种,因为如果所有输入数据都不发生变化,那么理论上结果也不会有变化,因此可以不用执行。理论上第一种情况可以把某些属性数据作为判断条件,然后第一种情况就变为第二种情况。对于这两种情况,也有可能判断条件会包含多个,因此根据ECS的思路可以拆分,至少拆分成一个组件只包含一个判断条件。
如果一个组件只包含一种判断条件,那么就可以把这个判断条件设置为一个观察值,只有这个值发生变化时才需要完整执行整个组件的逻辑。这就是Change-driven update的核心思路。当然处于简单,我们只判断值是否发生变化,而不是检测更具体的条件,例如一个逻辑条件是变量a大于10,那么a由3变成4也是触发逻辑更新。但是将逻辑判断附加到属性值上则会非常复杂。
这对于一些包含复杂计算或者涉及较大数据加载的组件都是非常有益的。而且对于开发者来讲也不算复杂,可能就是每个组件定义一个或者多个状态变量,并知道这几个变量需要检测即可。当然需要开发者去判断是否这些值的变化能完全决定或覆盖整个逻辑计算。
只有修改过的数据才会Update
2.3.3.1 理论基础
在RealityIS中,每个组件理论上是一个纯函数,即如果输入没有发生变化,那么输出也不会发生变化,所以我们可以监测输入,只要输入的值没有发生改变,我们就不需要对其相关的组件进行计算。
当然这里动画是个例外,以及一些自行定义跨帧计算逻辑的组件,所以这可以通过组件的属性进行设置,要求是否对输入进行监测,以驱动组件计算。
.ChangedDriven(True)
当然参见2.2.3.3节可见,由于我们将所有跨帧状态看做是dt的函数,需要在每帧进行重复计算,所以组件函数本身仍然是纯函数,这里实质上是将dt也看做了一个 输入参数,而其他的组件可能是不会使用组件参数的。所以这里将组件属性名改为:
.UseDt(True)
可能更合适。
这里表面上看,好像可以通过函数是否引用dt进行自动推导,但是有一些特殊情况,例如函数只是使用dt来生成随机数,并不是计算跨帧状态。所以我们还是不能对dt的使用有任何假设。
2.3.3.2 管理与调度
总的原则,输入变化了才会导致组件执行这件事情是不需要让开发者感知的,更不应该需要它来控制这个过程,因为运行时是完全能够计算/推导出这一切的。当然,动画除外,或者更确切地说,是那些不依赖于输入,而自行定义了私有变量的组件,这些组件之所以定义私有变量,其目的就是在相同的输入下可能存在不同的输出,这就是传统OOP中状态的影响。参见2.2.3.3节。
在Bevy中,它依赖于由程序员决定一个组件是否对某个Component造成了修改,他需要每个组件使用mut关键字的查询,这样系统就可以判断其值是否可能被修改,但是不可修改的通常是少数。
跟Unity不一样,我们不能把Version Number暴露在Query中让开发者去比较,因为这本可以自动进行的。何况在Query中进行计算,这个组件的函数仍然进去了,只是进去之后才发现不需要计算。这个判断的固定结构完全可以交给运行时去管理的。
CreationVM运行时需要对每个块进行追踪,如果发现没有修改并且不是动画类型的,就不需要进行组件计算。
2.3.3.3 变更的判定
由于上述冗余的存在,不可能保证每个组件只有当输入发生改变的时候才进行计算,可能会存在大量重复计算。此外,即使是不同的输入,也可能存在相同的输出,因此,我们不能像Unity/Bevy那样仅凭组件是否对属性进行写操作来进行判断。
而且写操作这种逻辑是不变的,意味着如果存在大量的浪费,那么这种浪费会一直持续,这本身是一种结构性特征,可以交给运行时拉处理。
显然,我们需要对每个值进行判别来决定其属性是否发生变更,但由于组件处在并行计算中,不能统一对一个块设置一个isChanged变量,为了避免对共享变量的写操作,需要使用和组件数据一样的方式。
这里可以针对每个块中的每个可写属性设置一个通用的整数数组,当然还是SOA的形式,使得它们好像组件的另外一个属性,只是这个属性是由块进行管理的,而实体或者组件是感知不到的。
当组件函数对输入值进行写操作的时候,编译器会自动为机器码加入一段函数,这端函数其实做了一个判断:如果赋值的值与原来的值不一样,则对应实体对象对应的值为1,否则为 0。所以比如一个包含8个实体对象的块,其计算完之后的值如果没有发生改变,则值为:
00000000
如果其中的任何值为1,则意味着其值发生了改变,所有后续依赖于该属性的组件都应该执行计算。
对应的调度器应该把这个改变的状态传递给所有引用该属性的块。然后在这些块计算的时候,首先进行判断,除非所有值都为0,否则整个块都需要执行计算。
通过这种方式,每个块只需要保存一个数字,通过使用特殊的对位进行操作的寄存器分配,我们甚至每个对象只需要占用一个bit的存储,这个大小跟Unity DOTS的Version Number占用的存储差不多,但是其原理完全不一样。
并且基于值(而不是逻辑)的比较更可靠,通过编译器的适配,性能开销也几乎可以省略。
2.3.3.4 Version Tracking
![]()
Change tracking is a hard problem to solve efficiently and robustly. It’s easier to make it a responsibility of the content creators. They define what is static and what is dynamic. Unity doesn’t want to add complexity to content creators.
Fortunately the DOTS architecture has a nice solution for this problem. DOTS queries define read and write access properties to each component included in the query. This helps with scheduling, as multiple reads of the same data are race free and can be executed concurrently.
Since the write access is tracked explicitly and misuse is guarded by the compiler, we know which component arrays in each chunk were potentially modified.
To implement a “free” data version tracking system, we add a version number to each component array in each chunk. When write access is requested, the array version number is bumped to the global version counter, which is monotonically increasing. Systems store previously seen global version counter value. This value can be used as version change filter in future queries, to limit the query over chunks that have changed since the system saw them previously. This change tracking system is more robust than dirty flags and doesn’t require any additional bookkeeping.
We rely heavily on DOTS change tracking in the hybrid renderer.
Version numbers
Version numbers (also known as generations) detect potential changes. You can use them to implement efficient optimization strategies, such as to skip processing when data hasn't changed since the last frame of the application. It's useful to perform quick version checks on entities to improve the performance of your application.
This page outlines all of the different version numbers ECS uses, and the conditions that causes them to change.
All version numbers are 32-bit signed integers. They always increase unless they wrap around: signed integer overflow is defined behavior in C#. This means that to compare version numbers, you should use the (in)equality operator, not relational operators.
For example, the correct way to check if VersionB is more recent than VersionA is to use the following:
bool VersionBIsMoreRecent = (VersionB - VersionA) > 0;
There is usually no guarantee how much a version number increases by.
EntityId.Version
An EntityId is made of an index and a version number. Because ECS recycles indices, the version number is increased in EntityManager every time the entity is destroyed. If there is a mismatch in the version numbers when an EntityId is looked up in EntityManager, it means that the entity referred to doesn’t exist anymore.
For example, before you fetch the position of the enemy that a unit is tracking via an EntityId, you can call ComponentDataFromEntity.Exists. This uses the version number to check if the entity still exists.
World.Version
ECS increases the version number of a World every time it creates or destroys a manager (i.e. system).
EntityDataManager.GlobalVersion
EntityDataManager.GlobalVersion is increased before every job component system update.
You should use this version number in conjunction with System.LastSystemVersion.
System.LastSystemVersion
System.LastSystemVersion takes the value of EntityDataManager.GlobalVersion after every job component system update.
You should use this version number in conjunction with Chunk.ChangeVersion[].
Chunk.ChangeVersion
For each component type in the archetype, this array contains the value of EntityDataManager.GlobalVersion at the time the component array was last accessed as writeable within this chunk. This does not guarantee that anything has changed, only that it might have changed.
You can never access shared components as writeable, even if there is a version number stored for those too: it serves no purpose.
When you use the WithChangeFilter() function in an Entities.ForEach construction, ECS compares the Chunk.ChangeVersion for that specific component to System.LastSystemVersion, and it only processes chunks whose component arrays have been accessed as writeable after the system last started running.
For example, if the amount of health points of a group of units is guaranteed not to have changed since the previous frame, you can skip checking if those units should update their damage model.
EntityManager.m_ComponentTypeOrderVersion[]
For each non-shared component type, ECS increases the version number every time an iterator involving that type becomes invalid. In other words, anything that might modify arrays of that type (not instances).
For example, if you have static objects that a particular component identifies, and a per-chunk bounding box, you only need to update those bounding boxes if the type order version changes for that component.
SharedComponentDataManager.m_SharedComponentVersion[]
These version numbers increase when any structural change happens to the entities stored in a chunk that reference the shared component.
For example, if you keep a count of entities per shared component, you can rely on that version number to only redo each count if the corresponding version number changes.
2.3.3.5 Bevy's Change Detection
Bevy allows you to easily detect when data is changed. You can use this to perform actions in response to changes.
One of the main use cases is optimization – avoiding unnecessary work by only doing it if the relevant data has changed. Another use case is triggering special actions to occur on changes, like configuring something or sending the data somewhere.
Filtering
You can make a query that only yields entities if specific components on them have been modified.
Use query filters:
Added<T>: detect new component instances
- if the component was added to an existing entity
- if a new entity with the component was spawned
Changed<T>: detect component instances that have been changed
- triggers when the component is accessed mutably
- also triggers if the component is newly-added (as per
Added)
(If you want to react to removals, see the page on removal detection. It works differently and is much trickier to use.)
/// Print the stats of friendly players when they change
fn debug_stats_change(
query: Query<
// components
(&Health, &PlayerXp),
// filters
(Without<Enemy>, Or<(Changed<Health>, Changed<PlayerXp>)>),
>,
) {
for (health, xp) in query.iter() {
eprintln!(
"hp: {}+{}, xp: {}",
health.hp, health.extra, xp.0
);
}
}
/// detect new enemies and print their health
fn debug_new_hostiles(
query: Query<(Entity, &Health), Added<Enemy>>,
) {
for (entity, health) in query.iter() {
eprintln!("Entity {:?} is now an enemy! HP: {}", entity, health.hp);
}
}
Checking
If you want to access all the entities, as normal, regardless of if they have been modified, but you just want to check the status, you can use the special ChangeTrackers query parameter.
/// Make sprites flash red on frames when the Health changes
fn debug_damage(
mut query: Query<(&mut Sprite, ChangeTrackers<Health>)>,
) {
for (mut sprite, tracker) in query.iter_mut() {
// detect if the Health changed this frame
if tracker.is_changed() {
sprite.color = Color::RED;
} else {
// extra check so we don't mutate on every frame without changes
if sprite.color != Color::WHITE {
sprite.color = Color::WHITE;
}
}
}
}
This is useful for processing all entities, but doing different things depending on if they have been modified.
For resources, change detection is provided via methods on the Res/ResMut system parameters.
fn check_res_changed(
my_res: Res<MyResource>,
) {
if my_res.is_changed() {
// do something
}
}
fn check_res_added(
// use Option, not to panic if the resource doesn't exist yet
my_res: Option<Res<MyResource>>,
) {
if let Some(my_res) = my_res {
// the resource exists
if my_res.is_added() {
// it was just added
// do something
}
}
}
Note that change detection cannot currently be used to detect states changes (via the State resource) (bug).
What gets detected
Changed detection is triggered by DerefMut. Simply accessing components via a mutable query, without actually performing a &mut access, will not trigger it.
This makes change detection quite accurate. You can rely on it to optimize your game's performance, or to otherwise trigger things to happen.
Also note that when you mutate a component, Bevy does not track if the new value is actually different from the old value. It will always trigger the change detection. If you want to avoid that, simply check it yourself:
fn update_player_xp(
mut query: Query<&mut PlayerXp>,
) {
for mut xp in query.iter_mut() {
let new_xp = maybe_lvl_up(&xp);
// avoid triggering change detection if the value is the same
if new_xp != *xp {
*xp = new_xp;
}
}
}
Change detection works on a per-system granularity, and is reliable. A system will not detect changes that it made itself, only those done by other systems, and only if it has not seen them before (the changes happened since the last time it ran). If your system only runs sometimes (such as with states or run criteria), you do not have to worry about missing changes.
Beware of frame delay / 1-frame-lag. This can occur if Bevy runs the detecting system before the changing system. The detecting system will see the change the next time it runs, typically on the next frame update.
If you need to ensure that changes are handled immediately / during the same frame, you can use explicit system ordering.
However, when detecting component additions with Added (which are typically done using Commands), this is not enough; you need stages.
2.3.4 编译
由于System是不依赖于数据及数据结构的,它只包含一个相对索引地址,每个System使用的所有数据都可以通过这个相对索引地址进行查找,所以编译器只是计算了每个变量的一个索引地址,通过堆而不是堆栈指针的方式。
因此,每个组件在开发完成之后它的编译工作就结束了。
而在实际运行的时候,用户请求一个实体,云端会根据这个实体配置(对组件的引用),对实体的数据进行组织,它会根据System对数据的使用定义,将这些数据精心组织在Creation Table中,然后再将适当的数组及其索引发送给System的代码进行执行即可。
所以:
- 在编辑器Reality Create中,开发者每写完一个组件(例如一个System)都会进行编译,除非他再次修改组件源代码,否则不需要再重新编译,属于一种AOT的形式。
- 对于用户,它通常直接在Reality World app中进行操作,TA做的事情主要是修改实体的配置数据,当这些数据发生修改之后,这个过程不会涉及代码重新编译,只有Creation Table对数据的内存布局进行重新调整。
所以,尽管整个代码的组织方式看起来很复杂,得益于这种数据分离的机制,编译逻辑相对还是比较简单。
2.3.4.1 AOT
2.3.4.2 机器码在内存中的顺序
由于每个虚拟机内部的组件执行顺序是相对比较固定的,所以我们可以修改组件机器码在内存中的位置,按照组件的执行顺序进行存储,这样组件指令的加载将能够充分利用缓存特性,进一步提升性能。
2.3.4.3 客户端的字节码
有些客户端,如iOS并不永续直接加载机器码,这时候会退化为执行字节码。
当然由于已经关于组件和数据的更多信息,我们仍然可以对端侧的字节码虚拟机进行更多的优化。
此外,由于端侧只计算跟显示相关的逻辑,核心、复杂的计算逻辑还是在后端进行计算,所以性能影响并不大。因为端侧其他逻辑如渲染和物理模拟,仍然是C++代码。
2.3.5 链接和加载
在传统的编译过程中,因为源代码之间相互引用了类型及内存地址,所以它们需要链接在一起。虽然为了实现如增量更新等,能够避免改动一个问题就需要重新编译整个系统,但是链接过程是省不了的,链接的过程即是把各个源代码中相互引用的部分链接起来。
链接的机制对于大型实时系统的限制如下:
- 增加了启动时的加载时间
- 使得程序规模很难伸缩,因为更大规模的程序意味着更大规模的链接时间
- 同时,如果链接文件增多,很难管理到底要加载那些动态库,如果每个动态库只使用一点信息,那系统内存会导致大量的浪费。
虽然静态类型的语言其链接过程只需要发生一次,但是对于动态语言来讲,这样的链接过程需要在加载的时候执行,这增加了应用程序启动加载时的时间。
所以,为了解决大型系统的动态解释问题,我们必须要要能够将程序分成很小的碎片,并且去除相互间的依赖关系,从而彻底去除掉链接这个环境。
具体需要做到几点:
- 源代码之间没有相互类型引用,或者说源代码没有复杂的类型系统,只有基本类型
- 源代码访问的数据地址通过运行时动态分配,即不需要通过编译器实现指定和计算数据地址
- 当然数据的动态分配要足够简单,否则也会增加性能开支,参见Creation Table相关内容
- 源代码要足够碎片化,使得系统可以尽可能加载更少的代码
最终,RealityIS几乎可以完全抛弃动态链接这一部分的计算过程。
2.3.6 组件关系与计算图
维护一个表,记录所有当前程序中使用的组件,并根据组件中的数据定义,管理实体对象内存数据的布局,组件的执行顺序等事情。
2.3.6.1 组件之间的依赖关系及顺序
给定一个程序,或者Creation,首先需要根据组件之间的依赖关系计算它们的执行顺序。基于一下的原理可以计算出这个顺序:
- 每个组件只有一个输入和输出
- 所有输入和输出参数都来自符号表
基于上述两个关系,可以计算出所有组件的计算顺序。按照这样的顺序执行:
- 既可以保证时序性
- 有不需要开发者处理复杂的顺序机制,实际上对于复杂的组合,这种顺序几乎是不可维护的
很多分布式系统都采用消息机制或者响应式的方式,很难保证时序的问题,而时序的问题可能会带来很多bug以及开发和维护的复杂度。
RealityIS本质上是将消息列表进行精心的组织,使得事件的分发不再是异步的。
传统的分布式系统大多是响应式、异步的,它们单纯是通过消息传递来解耦进程之间的关系,但是同一个消息可能对应着多个响应者,这些响应者之间本身也可能存在依赖关系,因此这些复杂的关系不太容易梳理清楚,因此传统的分布式系统都默认不处理这种顺序,开发者需要自己小心地处理顺序。
然而实际上函数本身就是包含时序性信息的,例如你需要使用某个变量的值,这个变量的值的赋值语句必须限于使用这个变量的方法调用,而这个赋值语句很有可能就是另一个函数调用,那么就可以得出之前的函数调用顺序应该先于后面的函数调用。
当然上述的理论,这里有个巨大的缺陷,函数本身是一个与变量无关的方法,例如我在方法A之前调用了方法B,然后再在方法A之后也调用了方法B,那么A和B之间的顺序实际上是无法通过函数本身推导而出的。
但是如果我们首先确定了变量,并且这些变量在整个程序运行过程中的名字是不变的,所有函数要么以这些变量作为输入,要么作为输出,那么我们是有可能推导出函数之间的关系的。这种关系是基于变量的,而不是函数的,函数确定相关性,但是计算的是针对一个变量,它所关联的函数的顺序。
但通常这样就足够了,毕竟我们要保证的也只是变量的共享和并发问题,而不是要严格保证所有代码(方法)的执行顺序。
2.3.6.2 深度学习中计算图的启示
OneFlow的核心思路,是根据模型的计算图,静态地推导出节点之间的依赖关系,然后利用Actor模型,把每个节点当做一个Actor,通过 依赖关系来决定计算顺序,通过计算图节点内部的状态来管理Actor的计算。Actor之间消息传递的是对应节点的状态,如果一个计算节点的上游已经计算完毕,则当前Actor进行执行状态,可以被空闲的计算机进行计算。此外在计算一个节点之前,如果涉及数据需要处理如拷贝的,则有专门处理数据拷贝的Actor会进行处理。
OneFlow的核心还是因为静态的计算图可以完整推算出所有节点的计算顺序,然后可以依据这个顺序进行分布式调度。
RealityIS相对于OneFlow有以下一些区别:
- 计算图的节点类型是固定的,因此可以有很多信息帮助推断节点之间的依赖关系和状态,而RealityIS的组件之间的依赖关系是不能事先推断出来的,每个组件的方法参数都不一样,没法进行这样的全局推断,所以它只能动态计算,不能有一个已知的依赖关系来全局指导
- 计算图节点之间的依赖关系是事先静态推导出来的,而由于缺乏上述那样的类型信息,RealityIS的依赖顺序只能运行时动态计算
- 计算图的计算不是实时的,它是一次性的计算,因此Actor之间通过消息协调顺序所带来的开销并无太大影响,但是如果一个模型特别大,这种调度对于实时系统的开销是很大的
- OneFlow以节点在计算单元,而RealityIS中对象或者一个对象内部的组件之间的依赖关系会更加复杂,而且还要考虑UserID带来的信息维度对应的复杂度,如果单纯以逻辑计算单元如组件为一个Actor,会带来非常大的状态同步和消息通信的问题。
- Actor模式本身是不需要保存状态的,而游戏中的数据需要持久保存,除非对象被销毁
显然,对于两者而言,核心的问题均是计算顺序或者说计算单元之间的依赖关系的问题。
- 在传统的面向对象模型中,整个程序的计算顺序完全内置于代码内部
- 在深度学习模型的计算图中,计算顺序其实也是已知的,类似于上述面向对象计算模型,OneFlow只是把这种依赖顺序转换为数据,来指导分布式计算而已。而为什么它能够提取这种顺序,是因为计算图将数据和计算分离,数据充当了计算之间的连接,并且天然划分成不同的细分几点,因此自然容易将这种顺序数据抽取出来。
- 在游戏架构中,这个事情会比较复杂点
一方面,游戏组件之间的依赖关系肯定是可以推导出来的,但这有个重要的前提:那就是每个组件的输入输出关系需要非常明确,传统的计算图其实就充当了这样一个明确的关系,这种输入输入关系决定了节点之间的计算顺序。然而传统游戏中,假设两个组件A和B,A对某个数据属性进行写入,然后B对A写书的数据进行读取,这样我们就可以推断出A应该先于B执行。然后我们在传统面向对象编程中仅仅把变量当中一个可读可写的普通变量,因此运行时或者编译器并不能推断出哪个组件对该属性进行只读操作,而哪个组件对该属性进行写操作。因此系统没法推断组件之间的依赖关系,一般指采取一种比较野蛮的方式:即全局地给组件加一个计算顺序,或者说指定某个组件对其他组件的依赖关系。这种方法显然不够鲁棒,因为同样一个组件在不同的对象中可能需要存在不同的计算顺序,特别是当使用一些模式 匹配的方式的时候,组件的顺序更是不确定的。
为了解决这个问题,RealityIS对属性的访问需要明确定义读与写的关系,这其实就是间接地定义清楚了计算图,这样运行时就可以进行依赖顺序的推断。
所以:
- 用户创建对象实际上是创建了一个计算图,只不过与深度学习中的计算图相比,它们的节点都具有全局属性,从而根据这些公共属性进行推断,而RealityIS需要根据模式匹配来进行推断。
- 运行时,所有Creation内部的每个对象的组件形成一个依赖关系表,多个对象的依赖关系表在合并在一个统一的依赖关系表。最终运行时按照这个依赖关系表的顺序进行计算。由于要考虑并行性,同一个组件对应的多个对象时并行计算的,因此数据的组织也是不一样的。
在判断多个对象的并行性时需要注意,只有同一个组件作用于相同的符号时,我们才认为它是逻辑上可以并行计算的。如果一个相同的组件通过模式匹配作用域不同的符号,则它应该独立计算。
2.3.6.3 谁来控制函数的执行顺序
在传统的程序中,函数执行顺序隐藏于代码中,由程序员开发的时候通过逻辑来设定好函数调用顺序,这样的方式由两个缺点:
- 顺序隐藏于代码中,不利于维护逻辑
- 数据也都是局部于函数而设定的,缺乏全局控制,数据管理也隐藏于局部,不利于全局维护
上述的问题也就导致开发者必须要去了解编程的知识,管理极度复杂,且不利于扩展和维护。
计算图,将数据和函数分离,推导出明确的计算顺序,这个顺序保存在一种图数据结构,运行时根据这个图的结构来控制计算。这带来两个缺点:
- 图通常表现为树形结构,对其节点的调用表现为大量的树的查询操作,尤其实际情况是函数数量非常多,这种运行时的查询成本会非常高。
- 图是一种顺序结构,不利于表达表达并行性,例如如果独立的子图之间采用了相同的组件,理论上它们可以并行执行,但是单纯的图是无法表达这种信息的,所以它无法在节点级别实现SIMD并行计算。
与之相应的是,RealityIS基于函数之间的输入输出关系构建类似的计算图,然后基于这个计算图来确定函数的计算顺序,但与计算图不同的是,它并不是直接保存计算图的结构,而是将这些顺序展平为一个线性的函数数组结构,这避免了运行时的树结构查询。
将图拉平同样意味着计算图必须是有向无环图,图不能是连通的,那样就无法推导一个确定的顺序。
同时RealityIS在单纯表示执行顺序的图结构信息之外,添加了一个额外的信息:
组件ID
传统的计算图只考虑组件类型,并且这种类型信息主要是用来帮助实现Fusion之类的优化操作,而不是用来辅助节点之间的计算顺序。
RealityIS会考虑组件的命名空间,或者ID,并赋予这个ID一个意义:即所有包含相同ID的对象,它们处理该组件的逻辑顺序是一样的。所以开发者在设计一个组件时,除了函数代码本身,它还有一定的逻辑意义,这个是有道理的,现实世界中我们总是对一些执行步骤包含一些逻辑意义,他并不是单纯的执行一些操作,这些操作之间通常有逻辑顺序,这种逻辑顺序恰恰是人类用户管理逻辑的核心,换句话说它就是我们所说的逻辑,而不是具体细节。RealityIS通过这种机制给用户提供一种管理逻辑的方法。更重要的是,这样的逻辑使得可以使用语义来表述一个组件。
基于这的机制和思想,RealityIS的函数执行顺序有一下特点:
- 所有函数的顺序被预计算或者实时计算为一个线性数组,这样运行时只需要遍历数组即可,没有复杂的数据结构查询
- 函数除了代码之外,还包含逻辑意义
- 逻辑意义使得多个对象之间可以并行计算
2.3.6.4 组件函数签名列表
由于需要动态调用组件机器码,并且这些动态调用的代码序列不能编译为机器码,因此动态的脚本代码是无法知道组件函数信息的,因此无法知道该怎么将实体的组件数据传递到组件函数调用栈上。
因此需要存储每个组件的方法签名,这样运行时可以直接据此构造函数调用栈。
尽管整个参数传递的过程是动态的,但是它只涉及小段数据的复制,大部分组件函数内的计算就可以并行计算,并且是按照机器码进行计算。
这也是其中动态的一部分,因此我们不可能使用AOT将所有逻辑事先编译,只有组件是可以编译的,但是为了保证任意的并发分配,并发的管理部分都是必须动态的,这是无法避免的。
2.3.7 隐式虚拟机*
只要有虚拟机的存在,源代码都是编译为某种形式的字节码,然后这些字节码在虚拟机上执行。由于字节码不是机器码,而是由虚拟机读取一条一条的字节码进行解释执行,所以这就直接导致一个结果是:
- 字节码中的指令序列完全无法被硬件优化,例如指令预取等
硬件只能识别虚拟机中编译为机器码的指令,而虚拟机通常不包含逻辑,只有一些通用函数,所以整个计算中从内存中读取指令会存在一定的性能损失,最极端的情况下,整个字节码中的指令都无法缓存,而每一个指令的执行都需要独立从内存中加载指令到寄存器进行执行。
即使是脚本逻辑源代码中包含很多顺序指令,硬件也无法很好的预取,因为编译为机器码的虚拟机代码并不包含这些逻辑指令。
考虑如果是静态语言,在编译过程中将IR转换为机器码的时候,对于每一个函数,它其中的每个符号的地址都转换为栈中的一个地址,而栈顶指针由维持着一个相对位置,这个位置由运行时实时分配,栈顶指针通常会被保持在寄存器中,所以访问速度很快。
我们可以借助上述类似的思路,使Creation Script实现类型静态语言的性能:
- AOT将组件编译为机器码,在这个过程中,每个组件被当做一个函数,组件中访问的符号全部被转换为相对位置;其实每个组件完全按照类似于传统静态编程语言中函数的方式进行编译,比如分配函数调用之前的栈初始化,以及结束后清楚栈中的数据。只不过这里栈中的数据由虚拟机实时的放进去,而不是机器码中插入的代码来执行这个过程,但是保持后面函数对栈中数据的访问方式是一样的
- 运行时虚拟机首先分配栈中的数据,可能涉及将Creation Table中的数据复制到方法栈中,然后组件方法中的机器码就可以正常执行
- 组件执行结束之后,虚拟机需要将其中的结果读回到Creation Table中对应的数据中
其中后面两个过程,可能无法在虚拟机中动态决定,因为其中包含不同的索引,名称等等,可能还需要需要讲相应的代码编译到组件函数的首部和尾部,让 它们自己来决定执行栈中数据的管理。
但是,这里是否可以考虑能够省掉向栈中复制数据的问题,改为直接读取Table中的数据,但这需要保证每个组件的数据连续,但是由于不同组件使用的标准符号会比较复杂,所以不可能保证这些变量都连续(像一个方法栈一样),所以可能复制还是不可避免的。
总之,通过上述类似的思路,也许我们可以做到使用动态脚本语言具有类似静态语言的性能。
2.3.7.1 组件机器码的调用栈
如果组件被编译为一个方法的机器码,并且方法收尾包含对方法栈的变量操作,那么由于这些操作的机器码是固定的,分配的内存地址及寄存器等也是固定的,所以要保证跟运行时的Table VM有效配合,Table VM传给方法组件的数据的顺序必须是固定的,这部分要通过上一节的组件关系管理来处理。这样组件机器码才能取到正确的数据。
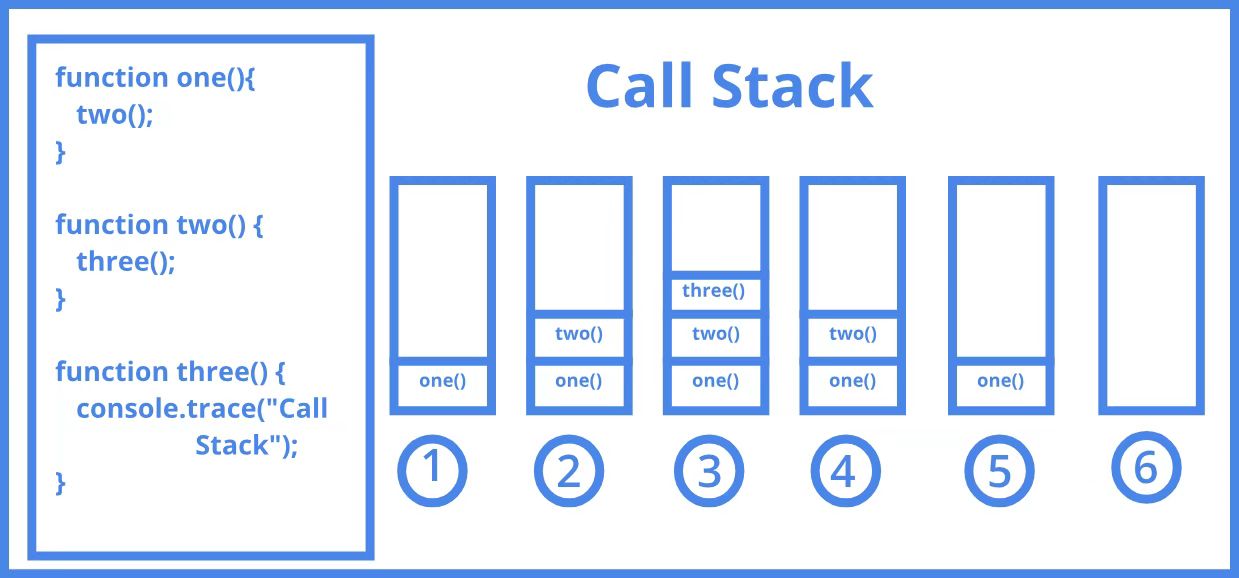
将组件编译为机器码,最大的问题是机器码中编码了对内存的调用,即寄存器分配部分,这部分也是编译跟解释最大的不同。通过固定分配好的寄存器,CPU能够使用寄存器来缓存变量,而不需要每个变量都从内存中读取,那样就多了很多寄存器变量读取写入的指令,并且无法利用传统CPU的一些硬件优化手段,如指令预取等。
编译的机器码包含了变量的寄存器分配,这些寄存器地址通常是基于一个调用栈来实现的,通过调用栈,每个函数执行的所有指令都是固定不变的。而保证任意函数调用都可以有序进行的协作机制主要就是:
- 栈顶指针
- 函数返回值
所以这两个数值需要运行时动态传给组件的函数机器码。在传统的静态编译型语言中,调用函数的部分也是机器码,因此从哪里获取函数参数的值都可以编码为固定的指令,但是在动态性语言中,这部分是可变的。
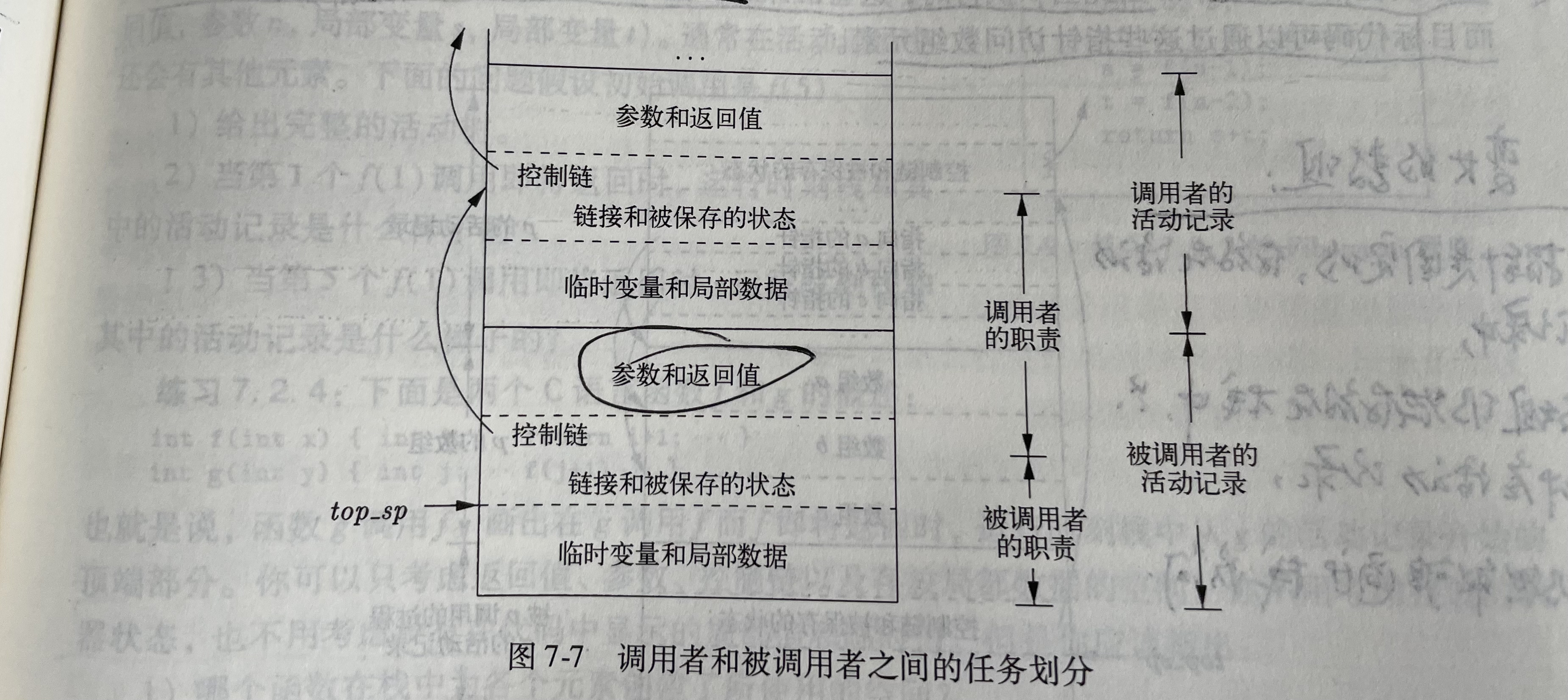
可以参照动态性语言虚拟机的做法,在一个虚拟机的循环中读取变量并获取地址,然后传递给被调函数的函数调用栈,包括栈顶指针和函数返回值。
但这里的问题可能是,虚拟机并不知道组件的函数调用栈的布局,即是函数的签名或者类型定义,所以需要将每个组件的函数签名信息存放在组件关系管理数据中。
另外一个精巧的点是,HotSpot VM使用OS线程来实现Java线程,并且一个Java线程上运行的所有native函数和Java方法都共用一个调用栈。所以HotSpot VM也把这种做法叫做“混合模式栈”(mixed-mode stack或者简称mixed stack)。解释器可以直接使用CPU的栈指针寄存器来表示自己的栈顶指针。
作者:RednaxelaFX 链接:https://www.zhihu.com/question/55141871/answer/143053269 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2.3.8 调度器
如果完全按照组件为粒度进行调度,可能导致的一个问题是:
- 一个客户端的众多组件被分配到较多的服务器,所以单个客户端需要和很多服务器进行同步
这里面其实是两个相互冲突的目标的权衡:
- 将尽可能多的来自不同客户端的组件放在一个服务器执行可以提升并行性,甚至可以放到GPU执行
- 将同一个客户端的组件尽可能放在同一个服务器,可以较少客户端的链接数量
所以,需要尽可能将单个客户端的组件至少放到同一个服务器中心进行计算,实际上这也是可行的,组件的执行主要还是依赖于CPU,所以不需要很大的并行度,例如8个、16个或者最多32个组件一起执行就差不多,而这样的要求很容易满足。
单个组件单次计算的数量不要太多,这样对运行时组织管理数据的要求会降低,例如8/16/32个。这样少量的组件并行计算需求也更容易对客户端进行管理,例如可能一两个客户端甚至单个客户端都可以达到这个要求。
同一个服务器中心,设置客户端管理调度,每个客户端尽可能跟一个或者少数几个服务器调度管理器相连接,而这些调度器负责对服务器中心的服务器进行管理,主要是:
- 收集来自同一服务器中心的不同服务器的组件计算结果,然后通过单次链接与单个客户端进行同步
2.3.9 动态符号表
传统的编译架构中,符号表主要用于记录用户自定义类型的结构,以帮助编译器进行内存地址分配。当然现代面向对象对象中,自定义结构本身是可以嵌套的,并且自定义结构体可能会包含方法,因此它也用来辅助作用域的计算。

本质上,符号表由源代码中生成,然后用于帮助编译器进行内存地址分配,然后编译好的机器码就不再需要符号表,符号表只是作为编译阶段的一种中间数据。但这也说明,从源代码本身就可以推导实际运行时变量的内存地址,所以动态语言的原理即使如果,它们动态地从符号表计算一个变量的地址,而不是依赖编译分配好的固定地址。
所以基本上,如果语言需要具有某种动态性,运行时内存中实时计算和存储符号表就是不可避免的。这里的动态性主要是指那些必须从符号表类型系统推导的属性,例如对象某个属性的地址,函数的参数列表以及参数的数据类型等等。
由此看,动态语言至少有以下两种较大的性能开销:
- 动态符号查询,符号表往往是比较复杂的树形结构,查询效率较低
- 字节码中的寄存器没有分配,所有变量都需要从内存而不是寄存器读取
RealityIS针对这两个问题,对于前者,它采用如下的优化手段:
- 简化类型结构,更少的层次,基本上没有嵌套的数据结构,更简单的数据结构,用户无法定义复杂的结构
- 让单台VM具有更少的类型结构,由于每个VM倾向于将大量相似的逻辑放到同一台服务器计算,因此同一台服务器拥有更少的类型信息及组件
通过上述两个优化,RealityIS对于类型的动态性方面的性能损失就降到了比较低的水平。
对于第二个问题,由于组件的逻辑是相对比较独立的,尽管组件定义的时候关联了一定的类型信息,但是我们通过运行时动态绑定函数调用栈来使函数的机器码可以独立编译。因此理论上组件的计算效率可以接近静态型语言。
参见2.3.7.1节。
2.3.10 虚拟机架构
2.3.10.1 服务端
后端由于可以动态加载动态链接库,所以直接使用JIT
2.3.10.2 客户端
客户端由于iOS不允许使用JIT,所以只能使用解释器:
- Wasm3虚拟机,该虚拟机用于将Wasm字节码动态解释执行,发生在运行时
- Wasm interpreter,该解释器用于将CreationScript解释为Wasm字节码,主要发生在编辑时
因为函数调用栈及其相关的机制,是被编译器编译到最终的代码中去的,是在代码的每个函数首位插入了一段控制代码,然后程序就能够按照这种机制执行,而不是操作系统提供了该机制,这里操作系统其实只提供了一个栈顶指针的概念。
所以我们完全可以把这种机制也部分实现在虚拟机中,首先虚拟机添加两个方法块,类似于原来静态语言代码中函数首尾添加的部分,由于这部分的代码结构都是一样的,所以可以在虚拟机中添加两个代码块,只不过这两部分的参数部分从解释器动态得来。
然后当一个函数组件开始调用的之前,首先运行时构造好调用栈的参数信息,并调用虚拟机首先执行函数开始块,传入调用栈的栈顶指针以及返回/回调地址,这样虚拟机后面的代码中的参数就只需要指定相对地址,可以比较作为常数写入到Wasm指令中,这样Wasm解释器执行指令就不需要再查找内存地址,CPU也可以直接将计算的结果写回到寄存器而不是内存,因为我们假设地址都是相对的,那么在解释为Wasm指令的解释器中,就可以直接把代码转化为对寄存器的意义,而不是单纯给他值,假设CPU啥也不知道,完全需要解释器根据每个指令的意义动态判断。最后函数执行完了,再回调解释器开始下一步。
这样节省每个指令都需要写入写出内存的操作,因为内存地址已知了,所以字节码中的指令都是常数,就不需要再内存中查找地址。
剩下主要的性能损失,就是指令的缓存、预取这些操作了,因为硬件级的指令预取肯定是只能来自编译好的机器码,这个跟OS有关,无法避免,由于动态解释的指令不是机器码,虚拟机无法应用这些,但是相比于内存的流进流出,其带来的性能损失应该可以完全抵消掉。
这里的核心在外部动态构造方法调用栈。这可控软件构造可以实现的,传统的OOP等构造方法,因为不能管理数据,所以很难动态构造,因为你无法知道方法签名,需要反射等很复杂的机制。这其实相当于把 编译器静态编译时对方法参数的信息拿都运行时,动态计算很费性能,这些信息一般在运行时都没有了。
记得好像《编译原理》中说原本函数添加的首尾两块控制程序是可以放到函数外码的,但是为了调用简单全部复制到每个函内部。我们的方法相当于是把这个还原回来,把它分来。因为我们现在函数是动态的,所以不能那样去构造。
即我们解释器生成的指令中,大部分操作数都是常量而不是变量,变量意味着Wasm字节码在解释执行的时候有需要多几条读取内存地址的指令,这带来两个结果:1)指令数减少,这也减少了Wasm虚拟机中查找机器码指令跳来跳去的频率,传统的虚拟机相对与静态语言的代码上的差别就是,静态代码是连续的,但是会存在代码重复,虚拟机的机器码是很少的,只有标准指令,但是就会跳转比较频繁以克服没有重复的问题,不过取指令相对于计算都是独立的指令,应该很快的;2)因为中间计算结果直接放寄存器,减少内存流进流出。
这样函数作为类型就是有非常大价值的,它帮助CreationScript解释器怎样生成Wasm字节码,以管理上述行为的执行。而且它只需要函数类型或者定义就行,不需要知道具体调用什么函数,可以单独编译/解释每个组件函数。
这其实就是lua的机制:
基于寄存器的虚拟机实现
基于寄存器实现的虚拟机,操作数的数据结构是存放在CPU的寄存器中的,对于这种模型来说没有PUSH和POP操作,但是指令中需要包含操作数的地址(或者是寄存器),并且指令需要显式的知道操作数的地址,而基于堆栈的虚拟机指令不包含操作数的信息,操作数直接通过SP得到,例如,在基于寄存器的虚拟机实现下,一个加法操作其指令将会是下面这幅图所示.
ADD R1, R2, R3 ;# Add contents of R1 and R2, store result in R3
就像上面提到的一样,基于寄存器实现的虚拟机是没有PUSH和POP这类操作的,因此加法指令只有一行,不像基于堆栈的虚拟机实现那样,这里需要显式说明操作数的位置(这里是放在R1,R2寄存器中),优点就是避免了大量PUSH和POP的开销,因此基于寄存器的虚拟机实现在指令分发循环要比基于堆栈的虚拟机要快. 除了上面的提到的可以避免POP和PUSH这类操作带来的开销外,基于寄存器的虚拟机实现还有一些其它的优点, 例如可以实现某些无法在基于堆栈实现的虚拟机中完成的优化操作,假设现在要执行一条减法操作,对于基于寄存器实现的虚拟机来说会将计算的结果保存在一个寄存器中,当这条减法指令再次执行的时候,可以直接得到计算结果,不需要再次执行. 尽管基于寄存器的虚拟机实现又如上诸多的优点,但是相比于基于堆栈的虚拟机实现来说,也存在着一些问题,例如,基于寄存器实现的虚拟机的指令平均长度都要大于基于堆栈的虚拟机实现,因为前者需要将操作数的位置放在指令中,而后者指令是不需要知道操作数的位置的,操作数直接通过SP获得,因为后者的指令长度要小于前者.
寄存器数量问题。
但也有不同:
这就是上面提到指令长度的问题。寄存器虚拟机指令的操作数直接执行内存地址,地址比较长,它没有调用栈,数据在内存中没有顺序。我们仍然可以构造调用栈来是指令的操作数变成相对位置,这样指令就比较小。
Lua只是为了执行性能,可以不考虑调用栈,但是我们要考虑安全性,调用栈是必须得,因此可以结合两者优势。
指令长度的减少可以大大减少Wasm字节码二进制文件的大小。
2.4. CreationXR
跟手机最大不同是:
- 手具有在三维世界中的位置,具备创建立体视觉物体的基础,不再仅限于平面
- 由于SLAM,人在三维世界的移动也具有3D位置,所以人身的移动也是交互的一种输入
- XR眼镜的屏幕更大,世界不再仅限于手机大小的屏幕尺寸
当然前两者在手机也是可以做到,只是体验没那么好
硬件设备的交互只限于手势识别、定位等基础接口,应用层要定义真正的交互接口:
- 随着手指的移动,生成不同风格的笔刷
- 当用户勾勒一个多边形之后,生成封闭的几何物体
- 当用户将两个多边形拼在一起,自动合并成物体
- 对几何表面的纹理涂鸦、材质编辑,喷绘
- 可能涉及很多物理模拟,这样更加真实
由于手势位置不是绝对精准的,所以snapping 算法很关键……
手势识别很关键
传统PC或者手机二维空间创建3D很大的问题在于,每一个操作都需要一个菜单,或者说每一个功能都是一个菜单,一个3D软件基本是就是一个菜单的几何,用户需要首先原则一种模式,然后在该模式下原则具体的功能进行操作,菜单可能上百,想象就是堡垒之夜都好多菜单
但当选择菜单以后,实际的原子3D操作并不多,在XR中,这一切都可以通过手势来大大简化,例如:
- 单手五指收拢就是缩小,张开就是放大
- 食指移动就是移动
- 左手掌🖐️可以控制一个物体,左手手势充当一些控制模式
2D vs. 3D
传统2D鼠标没有前后深度上的概念,然而:
- 场景是3D的
- 当前的摄像机主要是特定于某些比较近的物体
这意味着,当你需要对某些距离比较远的物体进行编辑时,必须要将摄像机移动到这些地方附近,然而PC上移动摄像机非常麻烦,因为没有3D距离,我们只能借助鼠标或者屏幕上左右上下的概念,这种平面向3D的映射使得只能实现相对于当前位置:
- 左右上下移动
- 或者左右上下旋转
这意味着移动到一个较远的地方会非常麻烦,而3D的交互则不一样,他可以直接将手指触及到的一个点拉到眼前
2.4.1 Unified XR Input
2.4.2 XR Scene Understanding
2.4.3 Data-driven Architecture
数据驱动应该仅关注用户逻辑层,引擎层面的开发还是使用传统的面向对象结构,或者有一些数据驱动,但它不是ECS架构,而是为了便于如跨平台性、渲染管线配置等这样的目的,除此之外,面向对象具有更好的能力·
2.4.4 交互
要想在XR设备上进行交互(包括内容创作),并且面向更大众的用户,必须具有更低交互门槛,传统的互动程序如游戏的操作门槛还是比较高。例如,使用手势触摸等按键控制人物在3D空间中进行行走,使用复杂的按键组合控制角色完成一些复杂的东西,仍然是游戏门槛比较高的其中一个部门。
当然,操控技巧本身被当做游戏机制很核心的一部分,它能带来玩法的乐趣,这无可厚非,但是互动内容背后本身所表达的故事、系统之间交互的机制等仍然才是互动内容的核心,它表达的东西会更多。
所以,和计算架构一样,我们也需要在交互领域做一些基础创新。
2.4.4.1 基于空间的交互
空间交互式互动内容交互的主要形式,包括移动摄像头、移动场景、选择物体、移动物体等等,常用的一些操作方式,如手机上的滑动、点击、双击等手势,以及PC上的键盘和鼠标,或者主机游戏机上的遥感和控制手柄。
大部分互动内容最频繁和最核心的操作是关于Camera的移动,这既可以是移动角色,也可以是移动场景,但不管怎样,几乎都需要一种机制能够控制在整个空间进行操作。这样的手势操作通常比较复杂,尤其对于较远处物体的操作,会随着距离和遮挡等问题变得更复杂。
以角色对参考系移动世界,和以世界为参考系移动角色,这两种操作类似,但是当你需要同时支持这两者是,事情会变得复杂,尤其移动物体会面临更多空间条件。《堡垒之夜》针对此设计了一种统一的架构,在手机模式中,它将物体与角色之间,借助固定的屏幕中央位置保持一种相对关系,因此可以把物体的移动操作与玩家的Camera结合起来。大大简化了这种交互的方式。

尽管这种方式简化了操作,但是如果在XR的环境(包括手机、AR和VR眼镜),由于设备本身具备定位功能,因此它跟真实世界的3维空间关联起来,我们可以借助人在真实3维空间的移动与虚拟Camera结合起来,这使得:
- 虚拟空间是可以相对静止不动的
- 真实空间人的移动充当了虚拟Camera的移动
借助上述的方式,我们有望可以进一步简化XR的空间交互门槛。
2.4.4.2 基于语音+AI的交互
大部分传统的互动内容交互都是只涉及到3D的空间交互,但是当这种交互转换到XR设备时,会导致一个新的问题:
- 即原本在手机上只需要点击屏幕选择的方式,也需要变成一种空间交互
这大大增加了门槛,例如下图所示,每一个物品的选择都需要移动虚拟遥感来确定要操作的内容。这在传统的手机或者PC上原本是很简单的事情。
针对此,除了上述的空间变换方法,另一个重要的方面是让所操作的内容尽可能语义化,然后我们就可以借助语音来辅助操作。传统的方式很难使用语音辅助,因为信息都是按结构描述的,信息通过没有语义。我们可能需要对每个元素加个标签之类的来辅助语音。
RealityIS组件的语义特性,使得我们可能在创作内容的时候,尽可能较少对空间交互的依赖,从而使整个创作过程更简单。
2.5 Creation AI
2.5.1 Semantics-based Creating
基于 语义 的 内容创作
2.5.2 Procedural Content Generation
2.5.3 Intelligent Simulation
2.5.4 Research
行为分析与研究
2.6 Creation Cloud
2.6.1 Creation Management
2.6.1.1 CreationID
2、场景到达及时性
游戏中的场景都很大,而且都预设一定的流程和路线,比如:
- 每个玩家都必须从起点,通过前面所有游戏设计师设计的关卡,才能到达某个场景点;
- 即使是静态场景如塔防,三消游戏,模拟经营游戏,它的状态也不一样,你必须从零开始把前面的等级都完成了,才能看到该场景的某个状态
- 即使如世界相对比较静态的开放场景,它的整个世界都很大,你很难让另一个玩家直接定位到某个你指定的地方,他们可能要有一会才能到达,例如一般会分为一些区,玩家可能能进去一个大区一个固定的位置,但是剩下的要独立行走一段时间,并且要知道方向
然而我们需要的是让被分享的玩家能够最及时的、立刻呈现某个兴趣点,并且朋友看到的是同一状态,甚至同一个Camera的位置,这种设计通常是小场景的,独立的,无比较复杂状态的操作
2.6.2 Creation Code Library
代码库是以标准为单位对其进行分类,每个标准会对应无数个实现该标准的组件,但是标准并不包含组件,它只作为用户选择组件或者开发者开发者的一种分类,例如为了实现不同标准之间的交互,某个组件可能使用来自两个标准的符号。
2.6.2.1 标准管理
标准管理比较简单,它就是一个数据结构的定义。
当然围绕标准会有社区和讨论,标准作为一种组件分类和检索依据,可以查询所有与该标准相关的组件。
标准的名称是唯一的。
不同的开发者都可以定义类似的标准,只是你需要去发展自己的标准,例如通过自己开发更丰富的组件,或者邀请别的开发者针对你的标准开组件。
每个标准只包含两个版本,以减少版本管理的复杂度,以及始终保持用户组件更新,参见4.11.3.4节的内容。
2.6.2.2 组件及包管理
组件包的管理包括两个部分:
- 开发者表写组件时,对引用的标准符号进行解释和加载
- 用户对实体添加或者修改组件时,自动加载组件,以及动态修改Creation Table的布局
与传统的包管理方式不同,这里不需要开发者或者用户手动维护版本号,参见2.7.5节的内容。
2.6.3 Multi-player Services
2.6.3.1 Voice Service
Um, and it's true that there are negative people out there sometimes, but the far majority of encounters are positive. Um, and also the far majority of social engagement on fortnight isn't with random strangers. It's not what many to many with millions of people are participating. It's players together with their friends, talking with their friends, kind of as an isolated group, uh, wandering through a much larger outside world. And a lot of the decisions we've made in the game have really contributed to the positivity here. One is that we have voice chat, so you can chat with your friends, but voice chat only works with people in your squad that either you're explicitly friends with and you explicitly joined up with, or you're friends explicitly joined up with.
And epic is con conscientiously making an effort to do this in everything we do. Uh, for example, we're moving to a web RTC based, uh, voice coms framework, um, in Fortnite for voice and text and video chat, so that we can start integrating with other services, you know, other platforms, other stores, other echo systems, other chat clients, um, and have shared social experiences across different game clients. You know, we already have some standards for identity and authentication. We can expand them from there with new standards, for friends and connectivity.
2.6.4 端云协同
现有引擎架构很难做到端云协同,例如大家想到的:
- UI和交互放端侧
- 云端可以共享的在多个用户之间共享
但这些都很难,或者在原有引擎架构下拆分很难。
除此之外,其实还有另外一些协同,例如AOT的预编译等,这种需要软件架构跟自己流程的联合设计。
2.6.4.1 在云端执行脚本
大部分组件都应该在云端执行,尤其考虑到很多逻辑实际上跟用户显示是无关的。
2.6.4.2 Client as a Display
一个核心思路:端侧只需要存储和计算跟显示相关的内容,比如大部分UI和视觉效果相关的内容。其他的逻辑和数据,如果它们虽然是核心数据,但是不会直接显示,也不应该存在于客户端内存中。
所以脚本中要区分哪些是显示组件,哪些数据是跟显示相关的。
对于那些与显示相关的数据,它们在客户端内存中都会有存储的值,但是这些值有可能是服务器计算出来的,如果是服务器写入的值,服务器会自动处理,使得对于端侧来讲,这个值好像就是端侧自己某个逻辑计算的,它随时可以从内存中获取到变量的值。
所以RealityIS要将这一切隐藏起来,使得对于端侧来讲,他像一个虚拟内存,端侧随时都可以获取到这些变量的值。
2.6.4.3 在云端计算需要加载的组件
2.6.4.4 计算实体和组件的关系
2.6.4.5 计算当前请求中所有组件的执行(依赖)顺序
2.6.5 并行计算
传统的面向对象很难抽取出小颗粒的计算,所以几乎无法做并行计算,一个游戏必须在一个机器上运行,因为它需要加载所有的数据和代码。而当这个“游戏”是一个无穷的元宇宙世界时,这种计算会变得越来越低效和昂贵。
传统的做法,如果不对数据做精心的管理,最多只能做到三个层面:
- 模块级的多线程
- 流水线级的多线程
- 虚拟化流水线
前者的主要问题是,它的数据仍然没有拆分,所以理论上它可以在一个机器内很好地做多线程,但是当分配到多台机器时,每台机器都要拷贝几乎所有的、相同的数据,使得并行计算的管理难度大大增加。
流水线级的多线程,因为流水线之间的顺序,也会增加管理和调度的难度。
这部分主要针对 GPU,由于GPU计算是高度并行的,线程之间依赖比较小 ,所有理论上可以分区域或者分块进行计算。但这不是绝对的,例如纹理采样,阴影,后处理等技术,通过是需要对纹理进行任意采样的,采用虚拟化流水线这一块有很多问题需要处理。目前看起来仅有类似Epic Games的几何裁剪是合理的,保证计算是维持在一个上限,而现代GPU计算这样的上限通常问题不大。但缺点是这部分数据管理的开销也不小。
但不管怎样,GPU的渲染部分通过裁剪,目前看起来是存在比较完善的理论和工程实践了,所以最大的问题是CPU的逻辑。
当所有计算处于一个应用程序内,逻辑计算将会非常复杂,所以从这个角度来看,OOP必然不合适,Unreal Engine的方式还没有存在较大的问题,是因为它的游戏逻辑部分的规模还不够大。
所以必然要将数据和逻辑拆分成一段一段小的计算单元,不管对于数据还是计算指令,这样就使得可以无限并行化,因此ECS类似的数据驱动几乎是未来唯一的解决方案,它在一个程序内部天生地将数据和逻辑区分出来。
2.6.5.1 分布式Creation Table
当计算和数据能够被划分为小块数据时,一个游戏世界不再被看做是一个不可 分割的整体,它的数据和程序都可以被简单地划分为多个独立的数据,因此一个游戏世界很容易被分配到多台服务器上运行。
每个客户端只需要保证知道不同的游戏对象对应的服务器地址即可。
整个并行计算架构变为:
- 渲染在客户端执行,通过很好的几何裁剪保证性能的上限
- 逻辑在云端被很好地分布计算
2.6.6 RPC
一般游戏中
2.7 核心编程思想
2.7.1 避免全局变量
2.7.2 函数式编程
2.7.2.1 基本构造单元
以列表为核心的基础操作,将代码分为两部分:
- 操作列表的核心功能,如filter,map和reduce
- 高阶函数
前者在函数式程序语言中通常通过库的形式提供,开发者更多使用这些库并提供高阶函数。
在RealityIS中有类似的思想,我们将所有实体对象看做列表,整个程序的计算都是并行计算,都是针对列表的计算,哪怕整个列表只有一个元素(运行时会根据元素个数以决定是否需要使用并行化指令)。在RealityIS中,filter,map和reduce这些底层函数由平台提供,开发者提供的类似于高阶函数。
每个组件包含三个函数:
- filter:提供筛选条件
- map:一般的逻辑处理
- reduce:合并统计之类的功能,需要添加一些累加值变量
运行时会首先执行filter函数,以确保map和reduce执行的函数参数对象不能为空,事实上运行时也保证filter执行的集合列表也不会为空。
所以CreationSctipt没有空值的概念。每个组件处理的也都是单个实体对象,它们一般不处理集合。
2.7.2.2 列表操作
对于每一个组件,它不光是处理该组件自身的逻辑,他其实也包含处理集合的功能,即:
- 处理实体自身的逻辑,例如map
- 处理实体所在集合的逻辑,例如filter或者reduce,order等
对于后者来说,传统的做法通常涉及for,while循环等,在一个集合的层面去操作,例如Unity ECS中开发者是获取一个类型的列表,然后开发者自定决定对列表的遍历。
借助函数式编程的一列理念,例如Erlang,它们把for或者while之类的循环转换为递归,然后开发者就可以聚焦于处理对单个元素的处理逻辑,这样就可以将对列表的操作和对元素的操作统一到单个操作中。当然对于集合操作来讲,其中的单个操作可能涉及到对多种情况的处理,这种情况倒是很好处理。
参见Erlang的lists模块。
2.7.3 数据驱动
2.7.4 ECS
2.7.5 包及依赖管理
包管理的机制主要是避免用户或者开发者触碰和配置别人的源代码。
但与传统的包管理思想不同,Reality World的主要创新在于不需要用户或者开发者配置版本号之类的事情,这不管对于开发者还是用户来讲,整个流程和思路都简化了很多。
2.7.6 动态解释
在一个开放世界,很多事情都在实时变化,所以传统的编译型平台肯定不再合适。动态解析是必不可少的,只是要做到:
- 局部解析,每个局部组件可以单独解释,而不需要改了一个脚本需要其他人都重新解释代码
- 解释效率要足够高
对于RealityIS,每个组件在发布的时候就编译好了,后续对组件的使用都不会重新对组件进行编译。当然这种情况下,底层的虚拟机需要将组件需要的数据地址计算正确并给到组件源代码。这种需求对于面向对象的方法是不太可行的,但是有了Creation Table将所有数据转换为数组的形式后,组件中的所有地址都是一个相对地址的偏移,所以能够简化这件事情。
为了保证大规模的动态代码执行,整个编译系统必须以一个组件为单位进行,而不能跟其他的代码有任何形式的关联或交叉编译。当然,传统的多个代码链接在一起的过程式因为这些代码之间存在引用,例如编译器为了解释某个类型,或者将变量执行某个内存地址,或者为某个对象分配多大的内存数据,这些导致需要交叉关联。而在RealityIS中,每个组件跟其他组件之间是无关联的,至少组件不需要知道其他组件的任何信息,而即使简洁的关系也是由虚拟机来决定的,所以对于RealityIS来说,对每个组件执行独立的编译就足够了。
所以,RealityIS是在Runtime的时候,根据用户实体配置实时加载编译好的组件机器码或者字节码,然后根据配置进行实时数据分配,并将实时的数据地址传递给组件指令进行执行。
尽管动态分配组件的数据内存分布会影响运行时性能,但这样的时机只发生在第一次加载程序,以及用户对实体的组件进行修改的时候,因此总体上不会对运行时性能造成太大的影响。
除此之外,由于动态解释的效率比较低,因此又不能将所有的逻辑和数据都使用动态脚本进行解析,那样整个系统的效率将会非常低。理想的状态是能够结合脚本语言的灵活性与原生系统语言的高性能,然后一般的语言机制却很难做到这样,因为数据跟程序逻辑通常是高度耦合的,它通常都是有一台机器同时执行数据的分配和逻辑的解释。比如现在的脚本语言,它都包含自己独立的虚拟机,使得脚本中的一些都是由该虚拟机管理的。虚拟机本身就是一台能够执行通用计算的机器。即使脚本语言也能够跟自定义的宿主程序进行交互,整个交互的过程却是非常复杂,比如这种复杂的过程肯定不适合普通的用户去配置,而且他也要求暴露一些底层的接口给平台,这样将会带来安全风险。
将组件的数据内存分配交给虚拟机来做,能够简化这个事情,让宿主层来管理和加载数据,将大大提升系统的性能。这样脚本语言省掉很多事情,只专注于唯一需要专注的逻辑计算指令。比如:
- 不用担心复杂数据的分配和寻址
- 不需要垃圾回收管理复杂的数据
- 由于省掉数据分配,以及更简单的组件开发规则(例如不需要定义复杂的面向对象机制),整个解释器也会变得非常简单
所以RealityIS整体上类似AOT,但是它也不是全部AOT,因为它的数据组织部分需要在Runtime执行,这样保证既有比较好的动态性,又有比较好的性能保证。
2.7.7 责权让渡
将很多原本需要程序员管理的事情交给运行时管理,例如对象的查找筛选,赋值,运用,对象状态管理等
2.7.8 并发消息队列
最好的并发模型就是Erlang的独立进程并发方式,但是基于ECS的数据管理会让这个事情可以做的更好。
2.7.8.1 数据本身就是消息队列
按照传统的做法可能就是需要单独构建一些消息队列,让后通过消息队列驱动更新,或者说就是单纯的但消息直接通知。
在ECS中,我们可以把实体对象的数据列表本身就当做一个消息队列,它满足消息队列的基本元素:
- 每个列表都处理同类型的消息,因此能够定位接受者
- 每个实体对象数据本身就携带了通信的消息数据
再加上一些对列表的filter等操作,就可以避免掉一些冗余的数据,比如那些没有任何变更的数据,也可以作为filter本身的一个选项。
当然这潜在的问题是性能问题,即列表数据不可以修改,或者重新组织的代价很高。但是也有两种方式
- 考虑到数据是只读的,其实也可以把这部分重新复制一份重新组织,传递给使用者,这样可以提升并行计算性能
- 或者干脆不管理问题也不大
2.7.8.2 并行伸缩性
Erlang并不擅长做GPU编程,因为这类问题通常都需要对大量数据进行数值计算。
Erlang中的易并行问题所处的层级要更高一些,一般来讲,它们都是像聊天服务器,电话交换机,web服务器,消息队列,web爬虫之类的应用,可以 把这类应用中工作的执行体表示成一组相互独立的逻辑实体。
Erlang仅关注函数半身,不关注数据管理,因此函数之间传递的数据,也可能像OOP一样,分布在分散的区域,不具备数据局部性。
RealityIS能够精心地对同类型数据进行更好地管理,以实现更好的并行计算。从这个层面看,他有点类似于把Erlang中那些同类型的计算都串联起来,放在其并行执行,但是由于Erlang并没有管理数据,所有要想在Erlang中管理并行其实很难,语言中并没有这一层机制。
除此之外,Erlang中还有一个与之相关的缺点是,不能保证进程之间的执行顺序。你只能发起进程,甚至不能取回返回值,也不知道它什么时候或者有没有执行完毕。
除了上述的因素,在RealityIS中,还可以实现大规模并行计算。在传统的端侧或者单机的游戏运行时,同一类型的实体对象通常是少数,比如可能就是几个,甚至很少超过几十个,除非跟图形渲染相关的部分。
但是当我们把这些计算放到云端,多个用户就可能汇集更大的同类对象,这种数量也许大到几千上万而可以 完全转移到GPU进行并行计算。这能够更充分的利用计算资源。
当然问题是,每个 同类型的计算结果或消息可能要分发到数千个客户端,但这个问题也许可以通过传统的一些服务器相关技术进行管理。
2.7.9 Let is crash
错误是不可避免的,因此找出好的处理错误和问题的方法,而不是企图防止错误的出现,这是Erlang的哲学。
实现方式或者原则:如果系统中某个部分出现了错误,造成了数据破坏,那么这个部分应该尽快死忙以防止错误和坏数据传播到系统的剩余部分。
2.7.9.1 容错机制
一种更安全的解决方法是,确保让崩溃和正常关闭具有同样的效果。这种效果可以通过像:
- 无共享,系统各个部分内存完全隔离
- 单一赋值,可以进一步隔离单一进程
- 避免使用锁,如果发生崩溃时有部分数据是被加锁的,那么会导致其他进程无法访问这部分数据,导致这部分数据状态不一致
在Erlang中,如果一个进程坏了,会发送最后一条消息出去,并且系统会保证这条消息被发出去,及这个部分默认认为不会出错。
在RealityIS中,一个组件内部的不同地方可能导致出错,但是因为RealityIS不是像Erlang一样独立进程执行,而是会去修改一些共享数据,因此如果这种修改之后再发生崩溃,就会导致其他模块的状态可能不是预期的。
所以,为了防止相关的不一致问题,可以从一下方面达到类似Erlang的效果
- 每个组件只允许修改一个共享属性,不能同时对多个属性进行修改。因为本身我们的属性经过了标准的精心设计,每个属性都是代表具有比较独立的意义,因此不同属性的修改应该使用不同的组件。
- 必须确保在整个组件没有错误的情况下,最后才会安全地修改属性,这个属性修改就像Erlang把消息发出去一样,本身不会出错。
- 除了上述的属性,RealityIS中的每个组件就像函数式编程一样,对其他状态数据不会造成任何破坏,因此可以随意丢弃掉该组件执行的部分而不影响整个系统。
- 其他像Reduce累加数的概念也类似
- 如果一个组件是处理Reduce,则它不能处理Map,因为两个逻辑可以进一步拆分,否则同一个组件不好管理。
2.7.9.2 并发调度
Erlang使用了基于异步消息传递的轻量进程的方法。
首先不能依靠操作系统来实现进程,而是通过在VM中实现进程,使可以对优化和可靠性进行完全掌控。比如,在Erlang中,一个进程大概占用300个字的内存空间,创建时间只有几微秒。
为了管理程序所创建的所有进程,VM会为每个核启动一个线程来充当一个调度器(scheduler)。每个调度器有一个运行队列(run queue),也就是一个Erlang进程列表,会给其中的每个进程分配一小段运行时间片。当某个调度器的运行队列中任务过多时,会把一部分任务迁移到其他队列中。这意味着,每个ErlangVM都会进行负载操作,程序员无需关心。VM还会进行其他优化工作,例如,对发向过载进程的消息进行限速,以调节和均衡负载。
这跟RealityIS的设计理念一样,调度器是每个核的时钟控制,就是游戏中的update循环,当然这里处理时间分配本身,还需要做一些在核内进行调度和核之间通信的事情。而消息列表实际上是携带者函数之间的参数,而在RealityIS中一个实体对象列表的数据,实际上也就是组件会使用到的函数参数。
只不过相对于Erlang的并发性,RealityIS还同时实现了并行计算。
2.7.10 组合优于继承
OOP通常通过复杂的继承机制来定义一个包含特定功能集合的对象,这些功能都已函数的形式被封装在一个类中。
FP则强调组合优于继承,其中的逻辑主要是因为FP中的函数通常是“无状态的”,独立的,对应于一个特定的输入,它的输出总是保持不变,因为不涉及到任何内部状态的修改,所以同样的输入不会受到任何影响。因此,这样的相互独立的纯函数是可以任意组合的,不同函数组合的一个更复杂的函数就构成一个特定功能的复杂函数或者复杂功能。
从上面的描述可以看出,所谓的组合其实并没有那么简单,它并不像ECS中那种平行的组合一样,他其实隐含着一定的编程逻辑,因为这些函数的组合是通过将函数作为另一个函数的参数的形式进行组合,它更像是一些函数连载一起,而每个函数作为另一个函数的参数,像插槽一样扣在一起,但是这些卡扣本身是有一定逻辑的,你需要知道将哪个函数连在另外一个函数的参数上,也即是意味着你其实要明白所有这些函数连在一起的执行逻辑和流程。
当然一般这种组合的层次不会很深,例如通常都是一个“业务函数”+一个高阶函数即可,但理论上可以根据抽象层级产生那种多层的复杂函数嵌套关系。
因此,如果某个函数的修改涉及到参数及返回值类型这种结构性的修改,其实“组合”本身还是需要修改的,只是相对于OOP而言,它可能只修改相关的函数调用部分,而不是重新去修改继承结构或者修改数据结构。
对于RealityIS而言,组件本身充当了业务函数,高阶函数被隐藏在组件的运行时调度中,因此这里不存在那种函数调用函数的嵌套关系,因此也即意味着我们无法实现多层函数嵌套,因为总共就只有两层:平台一层(高阶函数),组件一层。
2.7.10.1 组件之间的逻辑关系
当然组件之间是存在关系的,这种关系体现在前后两个组件之间的串联:前者将计算结果存在在一个变量中作为后一个组件的参数,这种关系跟多个函数嵌套是类似的:一个函数被作为函数传递给另一个函数,它也只是在那个函数中去计算一个特定的值,这个函数最终实际使用的也是它计算的结果,至于它动态传给它的参数,本身存在于RealityIS的实体对象数据上。
所以:
- 这种组合的结果,跟FP中基于函数的组合本质上是类似的
- 虽然组件之中看起来有状态参数,但是组件本身的实现跟FP中的函数是一样独立的,这些参数只是由业务层传来的实际处理的一个数据而已
- 并且对于FP而言,他很多时候也需要去记住一些状态,组件简化了这种机制
- 更特别的,这种平行的组合不要求用户理解组件之间的逻辑关系,这种逻辑关系还包括函数的签名及函数等,而不仅仅是逻辑流程
当然缺点是,这样平行的组合不太容易从全局把握清楚,而且有可能漏掉一些东西。
所以,需要在组件中定义好依赖关系,进行自动载入。
2.7.10.2 Machinations
组件之间的逻辑关系由Machinations描述。
2.7.11 模式匹配
模式匹配的几个目的:
- 变量绑定,省略参数传递的赋值,绑定等操作
- 结构解构
- 简化条件语句
- 函数调用解耦
这些因素在CreationScript中本身就不是问题,所以不需要函数式语言中的模式匹配,因为在组件中开发者都没有机会去构建结构和变量。
当然传统的正则表达式还是需要提供。但不用像FP那样成为语言的核心功能。
enum ShapeType {Retangle, Circle, Square};
struct Shape {
enum ShapeType kind;
union {
struct {int width, height; } retangleData;
struct {int radius; } circleData;
struct {int side; } squareData;
} shapeData;
};
double area(struct Shape* s){
if(s->kind == Rectangle) {
int width, ht;
width = s->ShapeData.rectangleData.width;
ht = s->ShapeData.rectangleData.height;
return width * ht;
}
else if(s->kind == Circle){
...
}
}
这段C代码基本上就是对函数的参数执行模式匹配操作,但程序员必须编写模式匹配的代码,并保证它是正确的。
而在对应的Erlang代码里,我们只需要编写模式,Erlang编译器就会生成最佳的模式匹配代码,用它来选择正确的程序入口点。
2.7.12.1 隐式的模式匹配
虽然CreationScript并不需要向开发者提供模式匹配的语法和能力,但是CreationScript本身则会使用模式匹配,这发生在开发者定义组件参数的时候,为了避免开发者解构特定解构的属性带来的耦合。例如:
(x, y, z) = Global.Position
这里Position可能对内部的元组使用不同的属性名字,这就使得开发者需要去了解这个名字,进而编写的组件代码与整个名字耦合,所以不利用函数重用,例如具有相同数据类型组合的元组就不能再使用这个函数。
所以,组件的参数必须使用元组的模式匹配的方式,让组件可以编写与具体结构无关的代码。
2.7.12.2 名字匹配
模式匹配是匹配数据结构,这个概念是面向程序员的,即编译器只是帮助你做一个类型检查,可以达到两个目的:
- 确定函数调用的合法性,保证正确的参数及其格式
- 帮助节省一些冗余代码,比如如果两个数据的数据类型是不一样的,则需要拆开为基本类型再进行逐个比较,这些冗余代码不光包含从数据结构中读取特定的数据字段,还包括对接受函数参数变量的赋值,模式匹配避免了这些冗余代码
但是对于一个完整的函数的调用,用户仍然需要指定函数参数,对于不同的数据结构,用户还需要了解结构后面的数据布局,这些对于普通用户都是很繁琐的。
名字匹配是模式匹配的升级版本,它有两点变化:
- 它简化了数据的结构定义,它鼓励更扁平的数据结构,而不是嵌套的数据结构
- 它除了保证结构匹配,还需要保证名字匹配,这样就可以避免用户输入参数,函数调用退化为语义组合
当然,这样做需要结合数据定义的共识,即所有程序面向公共数据编程,而不是自行定义数据结构。
当然用户可以手工指定参数,此时名字匹配退化为模式匹配。
2.7.12 分布式
分布式内置于语言内,在CreationVM上实现分布式调度,以及UDP远程消息通信
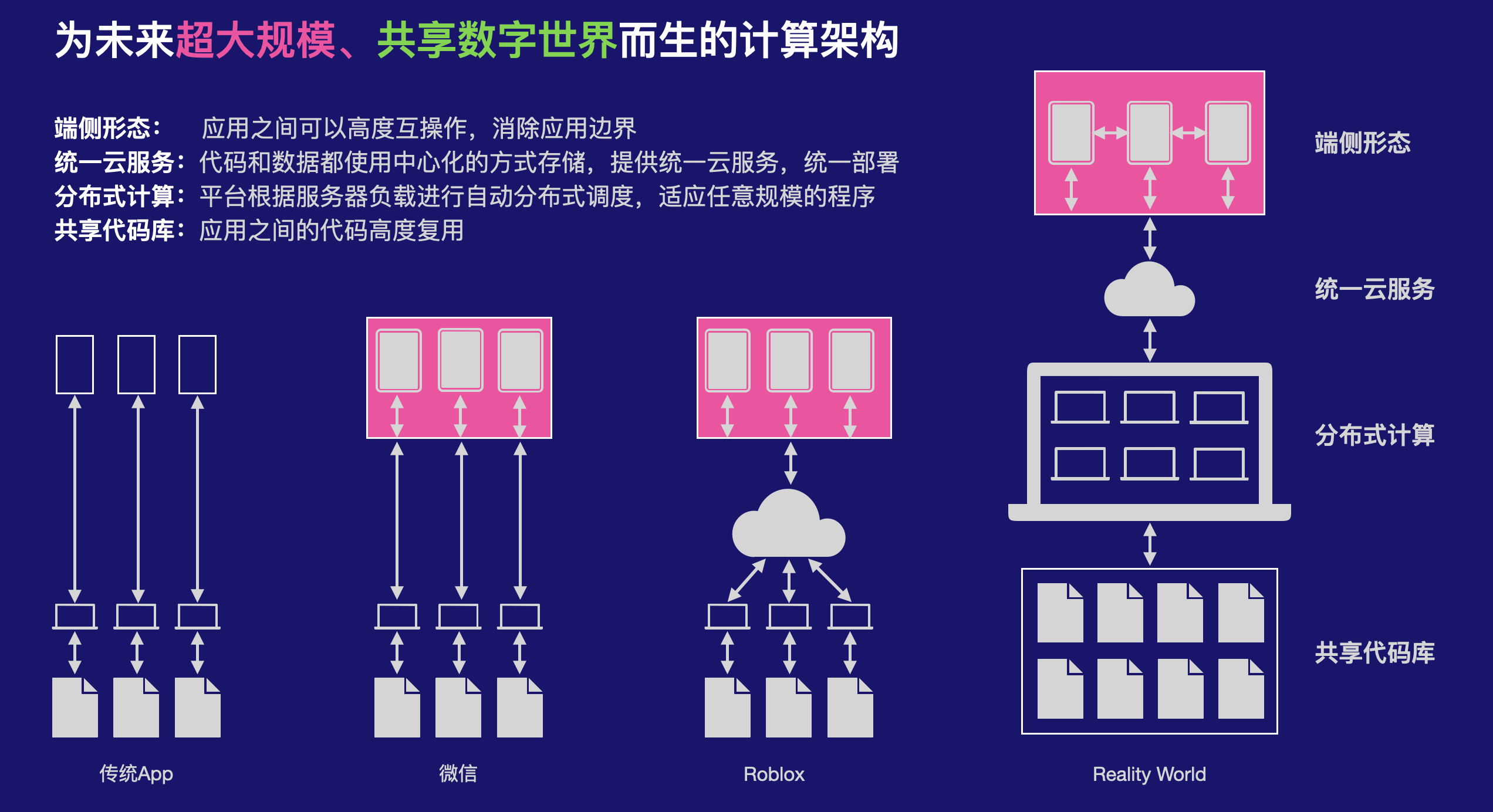
2.7.12.1 Actor模型
传统的Actor模型中,Actor之间是高度独立的,并且计算完返回结果就可以,然而游戏中的状态是需要持久保存的,所以这导致它并不能单纯地把Actor当成一个独立对象,仅仅使用消息通信是不够的,也需要持久保存状态。
具体在管理上,他需要维护一个Actor列表,并保证它们每一帧都会按照某种顺序执行,Actor之间包含依赖关系;而不仅仅是独立管理每个Actor自身的状态。
2.7.13 柯里化与部分施用
如果一个函数有多个参数,其中一些参数的值可以带入函数,但是此时不计算,而是形成一个新的函数,这个函数包含一部分上下文,但是这个上下文是不变的。然后当我们把剩下的参数带入函数,进行整个函数的计算。
这个效果就是柯里化或者称为部分施用。
其实,RealityIS的整个组件计算方式,跟柯里化的思路是类似的。一部分属性先带入早期的一些组件进行计算,是在为后续的组件计算构造上下文。只不过整个上下文是由运行时自动管理,而不需要开发者手动管理,并记住那些构造。

这个思路是RealityIS可复用与可组合的理论基础,正是这样的机制使得函数式编程中那种嵌套的柯里化机制可以转变为扁平的组合结构。但是其后面的核心理论是一致的。
其实如果可视化展开,RealityIS的组合也应该是嵌套的,跟函数式编程的结果是一致的。只不过运行时以不同的方式去维持闭包里面的那些变量。
2.7.13.1 扁平化的秘密
可以证明,理论上RealityIS的组件组合跟函数式编程是等效的,那么为什么能实现扁平组合呢?
这里的核心秘密在于,游戏机制中组件的跨帧通信将赋值语句解耦了!
在传统的编程或者函数编程中,一个函数接受另一个函数作为参数,并将计算的结果赋值给一个变量作为上下文存储起来,这些上下文通常根据函数的作用域进行管理。
但正是因为赋值语句,所以函数作为参数只能嵌套进另一个函数,而不是随意组合到一起由它们自由发挥作用。
当然随意组合要想自动发挥作为,还需要参数与函数之间自动关联和关系,这就是RealityIS在定义变量的时候就约束好的。
所以,通过跨帧的赋值,函数参数就一不用跟函数的上下文是耦合在一起的,所以可以独立存在和组合,再加上上述描述的函数与变量之间的自动关系,所以就能够实现嵌套函数的机制。
尽管RealityIS不支持取自来自两个不同实体对象的参数,但是如果我们把来自A的影响计算的函数结果存储在B中,然后再取B的值在C中进行计算,这其实间接就是一个多个深层函数嵌套的结果。更深层次的嵌套可以一次来推。
所以RealityIS是完全的函数式编程,只是上下文中的变量或者计算结果被跨帧的实体变量进行保存而已。
这简化了整个计算架构,同时简化了用户编程。
2.7.13.2 嵌套降低并行性
传统的函数式编程通过嵌套来实现组合。尽管单个函数的功能是小粒度的,但是嵌套的函数则形成了特化,嵌套组合后的函数几乎都是具有不同逻辑的函数,因此几乎无法进行并行。
对于函数式编程的另一个问题是,因为函数的参数本是另一个函数,而不是一般的数据,这些函数可能具有不同的逻辑,因此即使我们能够把所有对这些函数的调用汇集起来,仍然不能够实现并行计算。
所以,为了提升并行性,我们需要把函数作为参数的机制转换为传递值的机制,尽管看起来传递的参数是一个值,但是因为每一个实际计算的值都经过了前面一连串的函数计算过程,所以本质上这个组合仍然满足一个嵌套的复合函数。
而RealityIS就是这样的机制,通过扁平化,不仅保留了函数式编程本身的特质,而且通过将每个函数调用都独立出来,使得相同的组件可以完全实现并行计算。
2.7.13.3 函数式编程与复合
函数式编程(FP)本身的概念比较简单了,就是相对于面向对象(OOP),FP的函数内部没有状态,完全依赖于外部输入,所以任何输入都有唯一的输出,这种称为没有副作用的方式,就很容易实现并发,也很容易管理代码复用。
复合的原理
复合操作本身是把多个组件以某种方式组合在一起,一般来说一个函数调用另一个函数,其形成的整体也是一个复合体。对于复合操作本身,我们关注两个事情:
- 需不需要处理各种复杂的参数,因为复合操作本身是函数调用
- 还是简单的组合在一起,函数本身包含有映射关系
我们显然是希望后者,这就是为什么传统的函数调用封装机制不太利于用来作为一种面向普通用户的复用机制。
对于复合体来讲,我们关注两个层面:
- 该复合体是否包含状态
- 还是该复合体仅仅是一个功能组合体
其中前者就是传统的命令式编程所代表的方法,在OOP中,方法一般是附着于某个对象的,而对象一般拥有私有状态,因此即使多个对象以某种方式形成一个整体,当在使用某个这样的复合体时,调用者就需要设置很多参数,不同的参数下复合体会表现出不同的功能结果。这样就使得复合体不利于使用,尽管复合体本身可以包含一些默认参数,但是还是需要小心维护这些参数才能保证结构的正确性,这就是为什么很多软件或者库需要设置很多参数,有时候哪些参数忘掉了或者设置错了,整个软件就可能出现不可预期的行为。
尽管传统的实体经济中的大部分部件是以这样的方式运行,例如每个机器都带有各种参数,使用者需要首先设置相应的参数,然后再下达运作命令。例如洗衣机的命令可能很简单,但是其他一些工业机器可能则比较复杂。这是因为一台实体的机器,它没有办法接受一个外在的输入设置,主要的输入方法是手工操作,大部分机器并不允许插入一个外接信号源以可编程的方式设置参数。然而在计算机程序中我们使可以这样做的,因此我们可以把这些状态全部调整为复合体的参数,让复合体本身不带任何状态。
因为一旦复合体的使用包含手工设置参数的流程,并且这些设置的位置和格式还多种多样,使用者就无法做到自动化,并且这样的方式不利于普通用户使用。
这就是最核心的部分,复合不能以带有状态的对象为单位进行复合,这也是函数式编程模式中复合机制的特征,面向对象编程模型中以对象对单位,对象是第一等公民,函数是对象的组成部分,所以对象本身就很容易包含状态,以至于很难形成一种很好的复合机制。
当然,以对象为单位来管理复合体,比以函数为单位来管理复合体要简单的多,函数的粒度还是比较细。所以在RealityIS中,我们以对象为单位来管理复合体,一个对象即是一个复合体,对象本身不包含任何状态,这个对象其实就是函数式编程中的一个复合函数的扁平形式。此外,实体对象并不是单纯一堆函数的组合,这些函数之间必须是有相互依赖关系,对象原则上只代表一个复合函数,如果一个对象内有一个或多个复合函数是孤立的,则他们应该表示为不同的实体对象。
复合的机制
关于FP的复合,他其实和数学中的复合函数概念是类似的,就是一个嵌套的结构:
![]()
FP实现复合的机制就是将函数本身看作一个对象,因此就可以作为一个参数传递给另一个函数,相当于另一个函数中某个未知变量是由这个作为参数的函数计算出来的,这样形成的结果几乎就跟复合函数是一样的效果。
但是我们看复合函数,它是有结构的,不是任意组合的,你需要理解几个函数复合之后的那个结果的结构才能很好地复合,例如你换一个函数复合以后表现出的特征可能是完全不一样的。因此这种复合方式只适合程序员,不能把这种方式丢给普通用户,普通用户需要一种更扁平的,不需要了解那么多结构的组合方式:多一个组件只是多一个功能,但他不会说让行为结果完全变了。
可组合性跟互操作性是高度关联的,实际上它们并不是独立的概念,组合是需要互操作辅助的,因为组件或者函数之间终归是有联系的,需要解决这个联系,现有的体系就是只考虑解耦而不去维护这个联系,所以到目前为止几乎找不到比较好的可组合性的架构,原因就是没有解决互操作的问题,但反之解决了互操作,可组合性更像是一个结果,所以其实核心是互操作,这涉及编程语言架构,这就是为什么我们一直当作最核心的问题。
2.7.14 Serverless
从概念上讲,CreationScript提供给开发者的就是一种真正的Serverless服务:即开发者只需要编写一个简单函数,平台自动实现伸缩和并发,开发者完全不需要考虑服务器相关的事情。
Serverless是一种理念,现有云厂商有一种实现,但这种实现并不是Severless的终极形态。
现在云厂商提供的Serverless,他们其实还只是将计算托管简化到一个函数,而不是整个程序,这样便于伸缩,而云厂商实现的伸缩也比较简单,因为这个函数本身是与其他业务没有耦合的,所以他们把函数和数据复制到其他服务器执行就好。
但是这里面有很大的限制,他只限于几乎完全独立的函数,无法复用状态(游戏每一帧都要计算,需要维持一些状态),也无法实现Streaming等等一些特性,对实时性支持也比较差,函数存活的时间也不好控制。
因为他们只是单纯执行一个函数,并没有做太多事情,而完全要依赖于开发者自身去考虑怎样拆分逻辑。
我们的CreationScript,他是结合自己的数据特征和游戏运行机制,实现的一套并发控制语言,它通过虚拟机与组件(一个函数)的配合来实现一些如状态持久共享,Streaming,并发分发,函数之间的通信等等,这些机制如果没有运行时虚拟机的定制是很难做到的。
通过函数/组件跟语言、运行时虚拟机的结合,开发者开发一个组件时完全不需要考虑组件之间怎么去组织逻辑的事情,平台会自动把这些组件函数分配到Serverless的架构中去,这就是我们定义的不同的更好的Serverless架构。
这就是为什么我们强调RealityIS是一个大型的动态程序的原因,里面开发者开发的每一个组件,都是一个很小的逻辑,都可以被独立分配到不同的服务器计算,组件之间也是低耦合的,所以我就可以完全动态地控制他们,根据需要只加载会用到的那一部分程序,也可以根据服务器负载把不同的组件分配到不同的服务器执行,但是这些组件之间并不仅仅是按函数把他们拆出来而已,函数之间还是有关系的,并不是完全独立的,这种调用关系要靠RealityIS运行时虚拟机来支持,这是最关键的部分,否则他就只是一个现在的云厂商类似的Serverless服务而已。
2.7.15 自动化测试
游戏中那些动画、渲染、物理模拟等视觉因素之后,游戏背后的机制可以抽象为一套经济系统,其中所有的行为都抽象为资源,这套机制就是关于这些各种各样的资源随着玩家的介入进行怎样的流动,例如玩家用金币购买道具,用不同的道具组合形成新的道具,这些都可以说是经济的流动,而Machinations 可以模拟这套流动的机制,它是一套语言,理论上可以模拟所有经济系统的流动机制。
这里面的价值有两点:
- 由于游戏机制的数值平衡很重要,所以他可以快速测试这套机制的合理性,进而调整数值,否则不合理的机制直接就导致玩家流失,这跟应用程序不太一样
- 如果我们的可组合性足够好,我们是可以在这套系统和程序之间自动转换的,这样就进一步降低门槛,设计师是用更符合逻辑的视觉方式去设计游戏,而不是去思考代码结构,这个其实是我们组合组件进行创作的一种手段,它会成为我们面向组合的“开发或者设计语言”
将来我们第一家要收购的公司就是Machinations ,当然如果不能收购,我们自己也会做一套类似思路的工具。
2.7.16 面向数据编程
数据通常存在于一个对象,而数据最终是函数调用进行通信的信息,因此我们必须知道数据从哪里来,怎样被定义,怎样作为参数传递给函数,因此,整个编程过程中,我们几乎总在关注对象,因为对象是数据的封装实体。对象的结构本身形成数据类型。
但对象的结构本身包含了太多额外的信息,例如:
- 对象结构通常是跟具体问题耦合的,因为对象的结构通常就是这些问题的映射
- 对象结构的实现本身没有统一标准
因此不仅使用的人需要去理解和关注这些类型信息,开发的人也容易将一些类型信息耦合到函数方法中。这些都是额外的负担。
为了避免这样一些问题,我们来分析一些不同的方法。
2.7.16.1 好的方法设计应该不带类型
首先,方法的设计不用带带入太多自定义类型参数。
当我们在设计一个方法的时候,脑袋中应该想到的是它应该是一个通用方法,而不是针对某些特定类型的对象设计的方法。所以我们第一件要做的事情就是确保方法的参数中没有任何特定的自定义的数据结构,除非这种结构是被广泛使用、理解和认可、并且不会频繁改动的共识。
这种情况这些特殊的数据类型实际上充当了一个类似基本类型的地位。他可能应用于某个领域或者一个行业,而不是一个只为了解决特定问题而定义的数据结构。
如果一个函数的参数类型都是大家已知的“基本类型”,我们在传递参数的时候就不再需要定义固定的调用者及处理调用关系,任何只要具有这些参数的上下文均可以随意发起调用。
2.7.16.2 对方法参数进行模式匹配
当然实际上我们很难做到一个方法的参数类型完全不用自定义类型,比如如2.7.17节的描述所示,拥有多个函数参数在RealityIS中是不可控的,这种情况,我们可能需要将一些数据进行聚合,使得这些参数只能被存放在一个实体对象中。
如果函数的参数使用了结构体,并且这种结构体内的变量允许使用不同的名字,那么这样就会是函数的定义与某个特定解构发生耦合,为此,RealityIS使用模式匹配来解决这个问题,参见2.7.12.1节。
2.7.16.3 数据驱动的编程
另一些方法使用数据驱动的架构来避免一些面向对象设计的问题,游戏中著名的数据驱动架构是ECS架构。
这类方法有两个问题:
- 数据与功能之间的关系较弱,很难比较直观地看出数据与函数之间的关系,而对于RealityIS来将,我们需要使用数据与函数的关系来推导很多事情
- 数据与功能之间的关系需要开发者小心地维护,例如你可能给实体对象添加了Component,但是你可能忘了在System添加相应的filter;你可能正确地处理好了System,但是可能忘了给正确的Entity添加对应的Component。因为这两者是分离的,很难维护。
此外,ECS中System实际上耦合了Component的类型结构,所以Component的修改必然涉及到System的修改。
2.7.16.4 面向数据编程
根据上面的分析,我们得出好的编程模型的三个特征:
- 数据需要与功能相关联
- 但功能不能与结构相耦合
- 模式匹配可以用来解决上述问题
我们再来进一步分析一下函数和数据在程序中的作用,特别地,从可复用的角度。
从可复用的角度,实际上一个函数仅关心输入数据的类型,不关心任何对于调用者这些数据到底从哪里来。例如对于具有两个输入参数a和b的函数fun(),其输出参数c,它实际运行过程中这些变量的来源可能有三种情况。
- a,b和c来自同一对象
- a,c来自同一对象,b来自另一对象
- a,b和c分别来自不同的对象
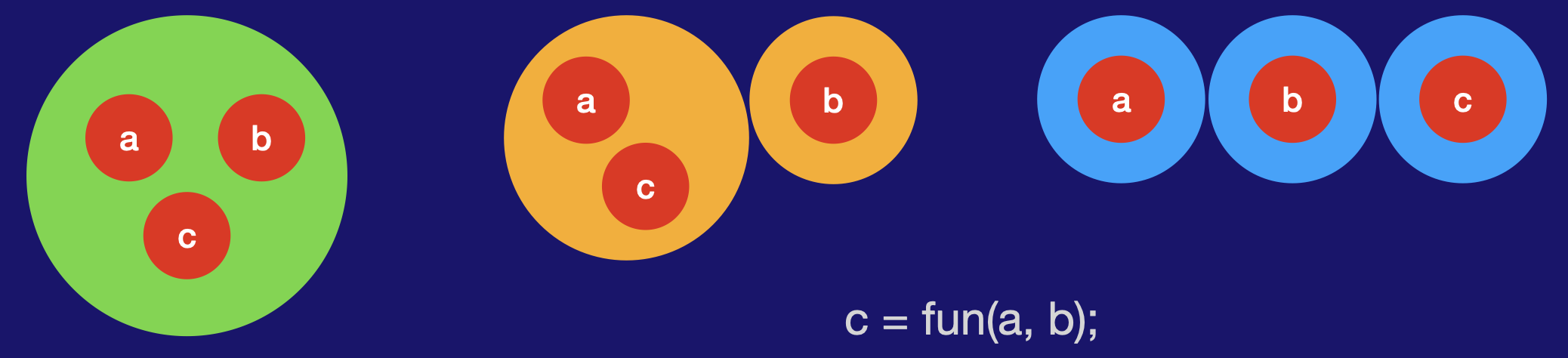
对于上述的不同的数据来源,或者说对于调用者的不同数据结构,好的设计是:我不管你们从哪里弄来这些数据,只要你把a,b和c三个变量的地址给我就行。
当然上述的要求通过模式匹配是可以实现的,但是为了满足数据与功能相关联的要求,RealityIS使用了一种非常不同的思路。
想一想:我们所理解的一个对象通常由功能定义的,没有功能就没有数据,没有功能就没有对象。当我们在定义一个对象时,对象中数据和功能的关系通常是很混乱的:有的数据可能压根没被任何方法用到,有些方法可能根本就不需要某些参数,这就出现冗余,不利于管理。
如果要进行管理,是应该根据数据来管理功能呢,还是应该由功能来管理数据,这两种看起来管理起来都很复杂。
另一方面,实际上对于用户,功能属性应该是主要,而对于程序,数据属性更重要。
RealityIS选择的方式是,让每一个组件的数据和功能完全相关联,组件不需要的数据就不需要定义,组件定义的数据必须在函数中被使用,这样就避免了冗余,并且让数据跟功能是完全对应的。
那怎样定义一个实体对象呢,就是根据组件功能进行组合,选择了哪些组件,实体对象就是相应组件对应属性的集合。这样在定义对象的时候,我其实是根据功能来定义对象的,我们根本没有关心其中的数据,而RealityIS的机制保证功能和数据的完全对应而没有冗余的。这避免了ECS的问题:
- 只需要维护功能,而不需要同时管理功能和数据
- 不需要维护和管理功能和数据之间的关系
2.7.16.5 组件引用变量
但除了上面的好处,RealityIS也与之带来了另一个新的问题:多个组件之间复杂的关系导致了一个实体对象同一个参数的多重定义。例如对于Global.Position属性,组件A和B都同时感兴趣,如果将A和B组合为一个对象,就会出现2次Position的定义。
这部分就是CreationScript独特的地方,理解它的核心在于:
- 变量是有符号表定义的
- 而组件只是在引用变量
这就是说,跟传统的编程不一样,RealityIS中一个组件并不会定义任何变量,所有变量都必须在符号表中定义。当一个组件“定义”一个变量是,它实际上是引用了符号表中的某个定义,但这不是个普通的直接引用,因为这个变量并没有事先在其他地方初始化。
所以,CreationScript组件中的属性声明还隐含着一个重大的意义:
- 如果这个对象还没有定义过该变量,那么就按照符号表的定义为该对象定义一个变量
- 如果对象已经存在这个符号,则将变量指向这个变量的内存地址
这种独特的设计,完美地消除了由组件组合带来的冗余,并且保持了数据跟功能的紧密联系。
2.7.16.6 用户定义对象
与之带来的另一个变化是,RealityIS的对象是由用户定义的,而不是开发者定义的。用户定义的数据可以形成任意的分布,这也为程序进一步带来了复杂性,参见下一节的内容。
2.7.17 函数参数数量
上一节的面向数据编程,它实际上假设,函数的参数可能会来自任意对象。
这从编程本身的概念看是没问题的,但是因为RealityIS引入由运行时管理数据的方式,这些对象之间更多是通过组件类型进行组合,而不是实际的对象进行组合。
因为指定对象的过程:
- 要么通过程序写死,这样就无法动态适应变化的场景
- 要么必须通过用户手动指定函数与之交互的对象
这两者都会导致可伸缩性和易用性问题。因此RealityIS选择按照类型进行自动匹配,但这带来多层循环的问题。例如如下的场景:
- 如果所有变量都位于同一个对象,那么整个组件就是执行一次计算
- 如果有一个参数来自另一个对象,则需要增加一层循环
- 如果另外2个参数来自另外两个对象,就需要2层循环
- 以此类推。。。
显然,这带来了复杂性。
我们无法预知实际的运行时情况会是怎样,这些变量可能来自任意的组合,因为对象完全是由用户来组织的。为了应对这种情况,我们可以作为两个假设:
- 如果某个组件使用了2个以上的参数,我们默认认为开发者是希望所有这些参数都位于同一个对象,这样系统只要筛选出同时具有所有属性的对象即可
- 但如果用户指定了外部变量,那么一个函数只能指定一个外部变量,因为多重嵌套的循环会带来复杂性
2.7.17.1 单参数函数
限制单参数函数,理论上不会对程序的表达能力带来限制,因为大部分基础的操作符都是二元甚至一元操作符,其他的操作符都可以转换为二元操作符。
但是拆散成二元操作确实会带来一定复杂性,这些复杂性可以通过一下几个方面进行缓解:
- 相关属性尽量定义为一个符号,这样就保证它们始终存在于一个实体对象时,所以其实尽管最终对象之间的通信是二元的,但是内部的很多逻辑还是不受限制的,这样的关系实际上类似于交互的对象是两个,这在现实生活中也是比较客观的,交易的对象之间通常都是两个人,多边协议的机制是比较少的,多边的机制也可以通过各种寻找一个代理出来交易,这个过程实际上就是内部变量进行归并的过程。
- 归并的事情由组件开发者来隐藏。组件开发者通过一些内部私有变量来隐藏大量归并的细节,使得对于用户而言,他看到的只是一个整体的组件。
2.7.18 响应式编程
主动式编程往往容易导致并发,因此RealityIS主要是响应式编程,但是与其他完全通过消息通过的机制不同,RealityIS能够实现原生的参数传递。
但与之带来的问题是原子性,比如在Erlang单个进程是可以丢弃的,但是RealityIS的单个进程只是执行上独立,但是跟其他组件存在较强的关联。这方面主要通过存档机制来解决这个问题。
2.7.19 程序中的动态性
硬件架构本身并没有限制和定义一个程序应该怎样组织,它跟程序的组织结构是分离的,硬件只需要知道我自执行某个指令的时候从哪里获取数据以及将数据(计算结果或中间变量)写回到哪个地址。
操作系统对程序代码文件的组织进行了一定的定义,比如加载并执行包含机器码的二进制文件。编译器应该将程序代码编译为一个或多个二进制文件,在这个二进制文件中,程序被组织为一些方法构成的代码块,操作系统为这些代码块生成地址,并将地址映射到程序中的符号对应的地址。但除此之外,操作系统本身也没有对程序源代码的组织进行一定的约束,例如程序中对任何代码块或者变量的地址映射还是由编译器决定的。而这些代码块本身是怎么生成的,例如是由OOP中的继承关系,还是由函数式编程中扁平与数据状态独立的组织关系,这些都没有任何要求。
因此,程序的组织和编译理论上可以是任意的,面向对象或者函数式编程都只是其中一种特殊的程序组织方式。
因此,理论上,构建一种极度动态的程序组织方式是可行的。
为了简化程序的编译过程,早期的编程语言大多是静态的,即一旦编译完成之后,整个程序的逻辑都被编译为固定的二进制机器码。如果需要对代码进行修改,就需要重新进行编译。
当然,在这种情况下,程序仍然具有一定的动态性,例如你可以声明一个执行某个方法的地址指针,如果你知道自己程序中有多个方法包含相同的签名,那么可以将这些方法的内存地址赋值给一个相同的变量,因此程序可以在运行时动态地对不同的方法进行调用。与之类似,一个指针也可以执行多个具有相同类型定义的对象,运行时对这些函数对象的动态方法也不会导致程序崩溃。
然而,这样的动态能力是非常有限的,本质上,整个程序的逻辑定义是固定的,程序只是在某些代码块执行的先后顺序上能够进行一定的自由组合而已。
2.7.19.1 动态的重要性
随着互操作、可扩展性等需求越来越大,以及部署到用户环境的成本。我们越来越需要程序具有更强的动态性。
当前已有一些技术架构用于实现一些动态性,参见下一节的内容。
然而对于未来而言,最重要的动态性在于,由于所有子程序本质上处于一个共同的内存环境,因此程序的组织方式会发生根本性的变化,这些变化包括但不限于:
- 程序代码本身非常巨大,所以没有办法编译为单个应用程序
- 由于总的程序数量巨大,因此它不可能全部加载到一个内存环境,必须要进行按需加载
- 按需加载意味着需要分析用户程序的依赖关系,动态地决定需要加载哪些代码
- 动态代码组织意味着,传统程序中那些类型查询、内存地址计算都要动态计算
这些需求与现代计算架构是天生不兼容的,因此我们必须要开发新的计算架构。

2.7.19.2 动态性的本质和分类
动态性是指一个程序可以不必按照完全编译好的机器码执行计算的能力,动态性往往意味着能够对已经编译好的程序进行一定的扩展或者更新。前面已经介绍,对于静态语言而言,它也存在着一定的动态性,这可以称为逻辑上的动态性,即所有逻辑是固定编译好的,只是程序根据运行时环境动态决定计算顺序,这一般都是基于指针来实现的,包括:
- 动态选择函数
- 动态选择类型
上述的动态性严格来说对程序的可扩展能力并没有任何帮助,除非编译好的程序代码中已经包含所有可能的功能,但显然那是不可能的。因此我们更常期待的动态性,更多是指扩展动态性,即能够动态加入一些之前编译好的程序不具备的功能。
扩展动态性包括可以通过很多方式进行实现,例如:
- 静态的程序库,可以通过链接过程动态加载第三方静态库
- 动态的脚本语言,这种一般通过虚拟机对动态的函数和类型进行解释
其中对于静态程序库,它本质上是利用前面的逻辑动态性能力来实现的。尽管这些第三方程序库中可能包括新的类型或者函数定义,但是它们均已经编译为静态的机器码,即自身已经包含了整个程序的执行机制,例如对这些类型进行解析以计算地址。
而动态脚本语言则不同,由于其中涉及的新的数据类型或者函数定义没有边编译为静态机器码,所以这些脚本语言需要被一种称为虚拟机的程序进行动态的解释,这个解释的过程实际上就是动态地模拟编译的过程,对类型的结构进行查询以计算地址。但由于这些定义的函数并没有被编译为机器码,而是由虚拟机动态执行,所以这个执行过程并不能够很好的利用到硬件的一些特性,例如指令的预取,分支预测等等。因此动态脚本语言的性能通常比机器码要低得多。
利用上述这些动态的能力,加上合适的架构设计,可以设计出具有比较好扩展性的程序。几个例子:
- 例如传统游戏引擎中的插件机制
- 例如Lua脚本语言可以增加新的逻辑代码
- 例如在Erlang中,由于每个进程启动时始终加载最新的脚本代码,因此可以实现动态更新。注意这种机制与Lua相比存在本质架构上的区别,Lua的热加载只是一种语言的功能,但是这个加载的过程或者说架构需要开发者自己去构建。不同的应用往往会设计出不同的热更新机制。而Erlang是一种内建于语言的机制,开发者只需要将对应目录下的代码更新,Erlang会自行加载,更不需要开发者做额外的事情。
深入思考动态性的本质,或者说理解它要解决的核心问题,大概可以归结为两点:
- 去耦合
- 可扩展
- 自动更新
去耦合是从程序语言机制本身看待动态性,语言层面的动态性大多涉及某种解耦的操作,使运行时可以动态替换一些方法或者说解析某些新的类型。可扩展性是从应用程序开发者的角度看待动态性,它往往是运用前面语言提供的解耦机制来实现的某种架构设计。

而自动更新是针对用户而言的,它具有最高的要求。传统的应用程序,受限于编程语言的架构,当程序需要更新时,用户不得不重新安装整个应用程序。虽然像在游戏开发中,开发者会使用如Lua这样的动态脚本语言来实现某些程度的热更新,但是大的功能本质上还是需要重新下载和安装应用程序。
尽管现在如App Store等使用一种自动更新的机制,使得不需要用户手动进行应用更新,看起来实现了应用的自动更新,因为对用户基本上没有造成什么困扰。但是这个问题其实本质上还不是用户层面的问题,它是由用户需求推生出的开发者的问题。尽管对整个正常进行修改,然后重新发布整个程序不会对用户造成困扰,但是我们可以在两个方面做的更好:
- 能否值修改部分代码,然后不需要对整个程序进行重新编译,就可以最简单地发布更新。当然这里说的是完整功能的修改,而不是如Lua那样的扩展修改。
- 在多应用互操作的环境,怎样让相互引用的子系统之间执行更好地协作更新
上述两点,当前的语言机制几乎是做不到的,这需要对语言和编译过程进行重构。
2.7.19.3 动态的限制和缺点
尽管通过上述的一些机制,现代的计算架构也能够实现一定的动态性,但基本上现在的动态性架构本质上不是为了真正的多应用互操作而设计的,它们更多是从程序语言的角度去设计,只是提供了一些方便开发者进行一定限度扩展的机制。例如新的脚本不能任意访问之前内存数据,往往都是预留固定的接口。这使得新的脚本基本上只能用来对程序进行扩展新功能,并且这些新功能对之前的代码相对比较独立。
2.7.19.4 程序方法的动态组织
如果所有的子程序在同一个“内存”或者执行环境运行,使它们看起来像一个超级巨大的应用程序,其中包含千千万万甚至上亿级的代码文件。那么对于每一个用户而言,TA所需要运行实际计算的“程序”只能是这些所有程序中的很小一部分。同样很显然的是,这个用户“程序”必然是动态生成的。
怎么动态组合某个用户定义的“程序”,就成为动态性的最大问题。
因为动态组合程序,不像想象中那么简单,比如说每个代码文件设置一个ID,然后建立一个用户程序数据库。因为程序代码总是关联着类型,类型和方法引用往往来自其他文件,因此程序结构本身是一个及其错综复杂的系统,根本不可能通过文件级别进行划分和组合。而如果要通过传统的编译解释机制:即通过首先构建所有类型定义的符号表,然后通过符号表查询和计算地址空间,这就几乎等于每一次运行用户程序就需要加载解析几乎所有代码。
为了应对和管理这种新的需求,程序结构的组织方式需要发生很大的变化。过去的思维是我们不考虑程序的组织结构,只需要考虑应用程序之间的类型引用安全,然后依靠编译器来对程序的依赖关系和代码调用顺序进行管理和组织。而现在我们需要在不引入所有代码的情况下提前计算按需加载的部分代码,这就需要在代码组织上做出一些调整,使得加载器可以直接知道仅需要加载哪些代码。
所以我们需要将这种依赖关系,从语言机制中抽取出来,然后存至数据库中。但是这种依赖关系不是那么好识别的,并且我们不能对代码进行某种形式上的调整或重组,因为开发者可能对代码进行更新。所以好的思路是我们需要对代码的组织方式做出一些调整,以便于能够这种组织本身能够帮助构建这种依赖关系。
在RealityIS中,一个组件对其他组件的依赖关系,表现为它使用的参数,而这个参数并不是由开发者随便定义的(否则它可以定义在任何地方,系统根本无法对其进行提取,就像传统的编程语言那样):
- 它们来自于固定的位置,共享符号表对应的位置
- 以及它与其他程序之间都遵循相同的符号定义
上述两点就使得系统可以抽取出任何用户程序之间的依赖关系,这是RealityIS实现动态性的核心因素:
- 首先它将组件的方法与数据一一关联起来
- 然后建立共同遵循的符号定义,而不是自行任何定义
- 这就使得对象之间的依赖关系是可以推算出来的
将程序语言的依赖关系抽取出来之后,整个应用程序的组织结构发生了非常大的变化,从总体上看,它变成了一种复杂的关系表,其中的任意组合都可以推算出依赖关系。这是实现大型动态系统的关键。
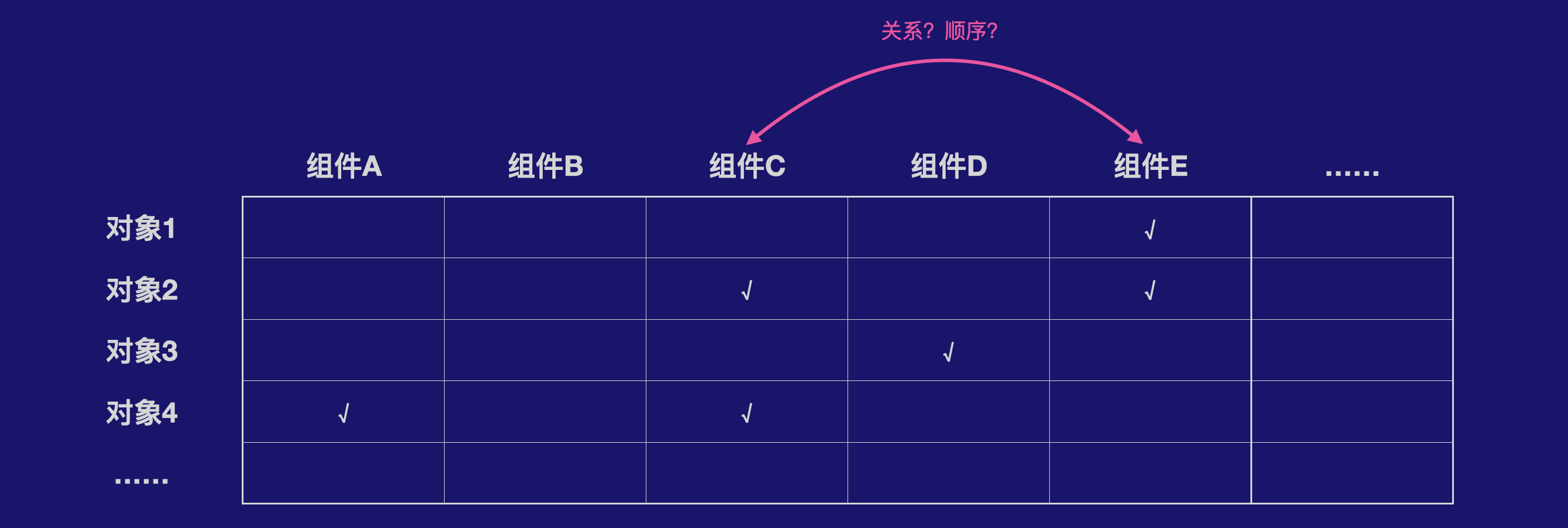
将数据和组件融合为一体是关键思想,传统的编程语言是没有这种机制的,甚至是不可理解的,但是不突破这一点就无法实现上述的功能,这种思路解决了两个问题:
- 可以自动推导依赖关系
- 解决了开发者或者对数据和组件之间关系的手动且容易出错或造成冗余的维护
这方面的内容参见面向数据编程。
2.7.19.5 动态性的阶段
要将整个程序完全按这样的方式组织,必然会导致性能问题,这些问题至少来自两个方面:1)动态查询数据库;2)动态编译、解释、链接等。
为了减少上述的问题带来的影响,我们尝试将一些操作过程提前计算出来。根据整个程序的组织过程,大概可以划分为三个阶段:
- 组件编译,这发生在开发者开发组件的时候
- 创作编辑,这发生在用户使用组件进行内容创作的时候
- 程序加载时,这发生在用户请求一个应用程序进行执行之前
由于用户编辑好对象之后,其相应使用的组件及其数据结构就固定下来了,而组件的代码实际上在开发者提交到代码库之前就已经编译好了,所以实际上应用程序启动时动态计算的内容就比较简单。仅涉及组件之间的依赖顺序等计算。
2.7.20 计算图
参见2.3.6节
组件之间由输入输出的关系决定执行顺序,这构成了一个有向无环图。
2.8 大型动态系统
在未来的开放Metaverse中,整个系统会非常庞大,使得不可能使用单独应用程序的思维和架构来管理这样的系统。在这样的系统中,系统内部的一些时时刻刻都在运行,也时时刻刻都在发生变化,无论是程序还是用户内容都是如此。
因此RealityIS应该是一个完全动态的系统,并且这些动态体现在多个层面。
2.8.1 动态编译
首先,程序是最核心的动态内容,而且由于整个世界代码量很大,因此必须完全动态解释。
起码要满足两个方面的需求:
- 每个文件独立编译,不能放到一次性编译
- 避免复杂的链接过程
对于链接过程,又必须做到两点:
- 程序之间不能有引用,因为引用就意味着要加载巨大的代码
- 只加载需要的组件及源代码,而不需要加载大量的不会被执行的代码
当然,参见2.7.6节的内容,为了避免这样大规模程序实时解释的,RealityIS使用了特殊的架构来保证整个程序在解释时的性能问题。
对于源代码的动态解释,它只发生在代码开发的时候,也就是开发者在Reality Create中编写代码的过程中,以及发布组件的时候。同时为了保证支持大规模的代码执行,这种编译只针对单个组件,不能对多个组件进行交叉编译。当然RealityIS也可以避免这样的问题。
除此之外,RealityIS在其他地方,并不需要编译。整个过程相对比较轻量,更多的是动态一些实体与组件关系的管理等工作。
同时,根据2.3.1.3节的内容,也许我们可以做到让动态的Creation Script具有类似静态语言的性能。
2.8.2 动态创建和修改
在Reality World这样完全开放的世界中,用户可以随时修改内容,而不是只能事先设置好固定的内容。例如用户可以一边玩一边修改场景,这种创建的过程本身也是一种玩法。
由于RealityIS中的所有组件都是编译好的,所以这种修改不涉及到代码的修改,因此动态操作是非常容易的。
当用户修改一个实体的时候,因为整个逻辑都是数据驱动的,因此运行时只涉及到数据的调整。然而,因为RealityIS的Runtime会承担一部分解释以及给指令分配正确内存地址的事情,所以用户的数据调整会导致Creation Table Engine对内存中的数据布局进行调整。当然这种调整直发生在修改的时候,所以总体应该不会影响性能。
2.8.3 动态加载场景
Reality World是一个非常巨大的世界,因此我们不能按照传统的方式一下子加载整个程序,而是只需要动态加载用户需要的数据。这里面可能要涉及很多跟地理位置相关的数据管理。
2.8.4 动态推送更新
当用户A修改了内容,其他与这个内容相关的用户当前的场景必须动态更新。
2.8.5 动态分配服务器
同时,由于整个内容的创建、加载、更新和推送等等,都是动态发生的,任务复杂而且计算量较大,所以需要动态的分配服务器,不能有一些太固定的规则,或者需要人工进行某些配置的工作,而且应该是可以自行伸缩的。
2.8.6 动态实体对象组件列表
传统的游戏机制中,角色Avator是一个比较复杂的类,他需要承载所有Avator所能操作的功能,其他物体对象的脚本通常则比较简单固定。avator几乎可以跟游戏世界中的一切物体进行交互,这就导致一个问题,即avator所携带的大部分组件功能,在某个时刻可能都不需要,因为它一次可能只跟少数组件进行交互,使用少数技能。
在一个开发的大世界,这样的问题就更加严重,因为所有avator能够执行的组件可能是无穷的,我们不可能把所有的组件都实现加载在avator身上,而必须实现根据需要动态加载。例如,玩家要进入一块冰雪之地,周围的环境会对它的体能消耗造成影响,这种只有在这个环境才能发挥作用的组件,可以设定一个区域,玩家进入这个区域的时候动态加载这个组件,然后离开的时候卸载该组件。
尽管不可能把所有的组件都实现这种动态加载的机制,但是还是有一些情况可以实现的:
- 例如这种跟地理位置相关的功能,可以设置一个Bounding box
- 让玩家主动选择,例如对于一个赛车广告,玩家默认肯定是不带这些组件的,这个时候可以设置一个特殊的组件,让玩家选择需要加载赛车组件;事实上这应该成为默认机制,即玩家看到某个物体,但是却不能与之进行交互的时候,玩家就可以选择这个物体,按一个特殊的键,就自动装上对应的组件,同样玩家可以卸载,玩家可以查看身上装了哪些组件;
- 对于长时间没有使用的组件,系统可以自行卸载掉,甚至设置一个最大组件数量。例如玩家自己很清楚需要玩哪一个游戏,它可能主动装载上与之相关的组件。
- 针对变化编程,即没有使用的组件不会发生计算和网络传输,但是这种情况仍然占据内存,并不是很可取的方案。
2.8.7 动态唤醒
即时唤醒:如果知道哪些组件对某个变量感兴趣,就可以不必让这些数据实时处于内存,而可以主动即时加载代码并执行,相当于代码或者组件数据存储到了硬盘,然后通过缓存机制动态加载,实际上缓存系统本来也是这样的架构,当内存数据过多时,那些不常用的数据就会被缓存到硬盘,但又可以即时被加载。
2.9 互操作性
Interoperability is a characteristic of a product or system to work with other products or systems.
广义上的互操作性,是指一个产品或者系统中的一些特性,可以跟两一个产品或者系统协调工作。这些产品或者系统可以是任何领域,比如金融、医疗等等。
With respect to software, the term interoperability is used to describe the capability of different programs to exchange data via a common set of exchange formats, to read and write the same file formats, and to use the same protocols. The lack of interoperability can be a consequence of a lack of attention to standardization during the design of a program.
对应于软件领域,互操作用于描述两个不同的程序之间通过一定的交换格式交换数据的能力,该两个程序能够通过相同的协议对数据进行读写。
在传统的软件领域,互操作性注重的是系统之间的标准,如果两个系统之间需要很好地协作,需要事先很好地定义一些标准,否则两个系统之间根本无法协同工作。
随着开放元宇宙和去中心化的需求,相对于传统的互操作性概念,RealityIS有一些不一样的定义,这些要求使得传统的计算架构很难去构建这样的能力。本节通过系统梳理互操作性的概念,进而更好地解释RealityIS的互操作性思路和方法,以及它解决的问题。
2.9.1 传统互操作性概念
大部分的互操作性都需要一定的编程语言机制来支持,所以传统的互操作性主要是指语言互操作性。
Language interoperability is the capability of two different programming languages to natively interact as part of the same system and operate on the same kind of data structures.
语言的互操作性是指两个不同编程语言之间,能够原生地进行交互,以及对相同数据结构进行操作的能力。其中两种比较重要的机制是:
- 通过标记语言
- 以及通过虚拟机
进行互操作。
There are many ways programming languages are interoperable with one another. HTML, CSS, and JavaScript are interoperable as they are used in tandem in webpages. Some object oriented languages are interoperable thanks to their shared hosting virtual machine (e.g. .NET CLI compliant languages in the Common Language Runtime and JVM compliant languages in the Java Virtual Machine).
其中对于标记语言,当HTML+CSS标记语言在浏览器中进行解释执行性,其中定义的元素能够被JavaScript语言进行解释;而对于基于虚拟机的互操作性,它们主要是借助虚拟机的相同中间语言及内存结构,不同语言编写的程序之间可以相互调用。
2.9.1.1 Object models
Object models are standardised models which allow objects to be represented in a language-agnostic way, such that the same objects may be used across programs and across languages. CORBA and the COM are the most popular object models.
2.9.1.2 Virtual machines
Different Languages compile into a shared runtime
A virtual machine (VM) is a specialised intermediate language that several different languages compile down to. Languages that use the same virtual machine can interoperate, as they will share a memory model and compiler and thus libraries from one language can be re-used for others on the same VM. VMs can incorporate type systems to ensure the correctness of participating languages and give languages a common ground for their type information. The use of an intermediate language during compilation or interpretation can provide more opportunities for optimisation.
2.9.1.3 Foreign function interfaces
Foreign function interfaces (FFI) allow programs written in one language to call functions written in another language. There are often considerations that preclude simply treating foreign functions as functions written in the host language, such as differences in types and execution model. Foreign function interfaces enable building wrapper libraries that provide functionality from a library from another language in the host language, often in a style that is more idiomatic for the language. Most languages have FFIs to C, which is the "lingua franca" of programming today.
2.9.1.4 Challenges
Object model differences
Object oriented languages attempt to pair containers of data with code, but how each language chooses how to do that may be slightly different. Those design decisions do not always map to other languages easily. For instance, classes using multiple inheritance from a language that permits it will not translate well to a language that does not permit multiple inheritance. A common approach to this issue is defining a subset of a language that is compatible with another language's features.[3] This approach does mean in order for the code using features outside the subset to interoperate it will need to wrap some of its interfaces into classes that can be understood by the subset.
Memory models
Differences in how programming languages handle de-allocation of memory is another issue when trying create interoperability. Languages with automatic de-allocation will not interoperate well with those with manual de-allocation, and those with deterministic destruction will be incompatible with those with nondeterministic destruction. Based on the constraints of the language there are many different strategies for bridging the different behaviors. For example: C++ programs, which normally use manual de-allocation, could interoperate with a Java style garbage collector by changing de-allocation behavior to delete the object, but not reclaim the memory. This requires that each object will have to manually be de-allocated, in order for the garbage collector to release the memory safely.
Mutability
Mutability becomes an issue when trying to create interoperability between pure functional and procedural languages. Languages like Haskell have no mutable types, whereas C++ does not provide such rigorous guarantees. Many functional types when bridged to object oriented languages can not guarantee that the underlying objects won't be modified.
2.9.2 区块链中的互操作性
In addition to the perspective of scalability, we also need to think from a practical perspective, why we need interoperability, or why we need cross-chain. Traditionally, blockchain can solve the problem of trust. If scalability can be solved, then the problem of performance will also be solved. Interoperability can actually solve the broader problem of trust when the above two issues are resolved.
At present, different application scenarios have different alliance chains and public chains. With these chains in place, we need to use interoperability to communicate useful data. This will involve different approaches to cross-chain or interoperability. In the future, we will see a blockchain system with extremely blurred boundaries, that is, private chains, alliance chains, and public chains are interconnected in some way.
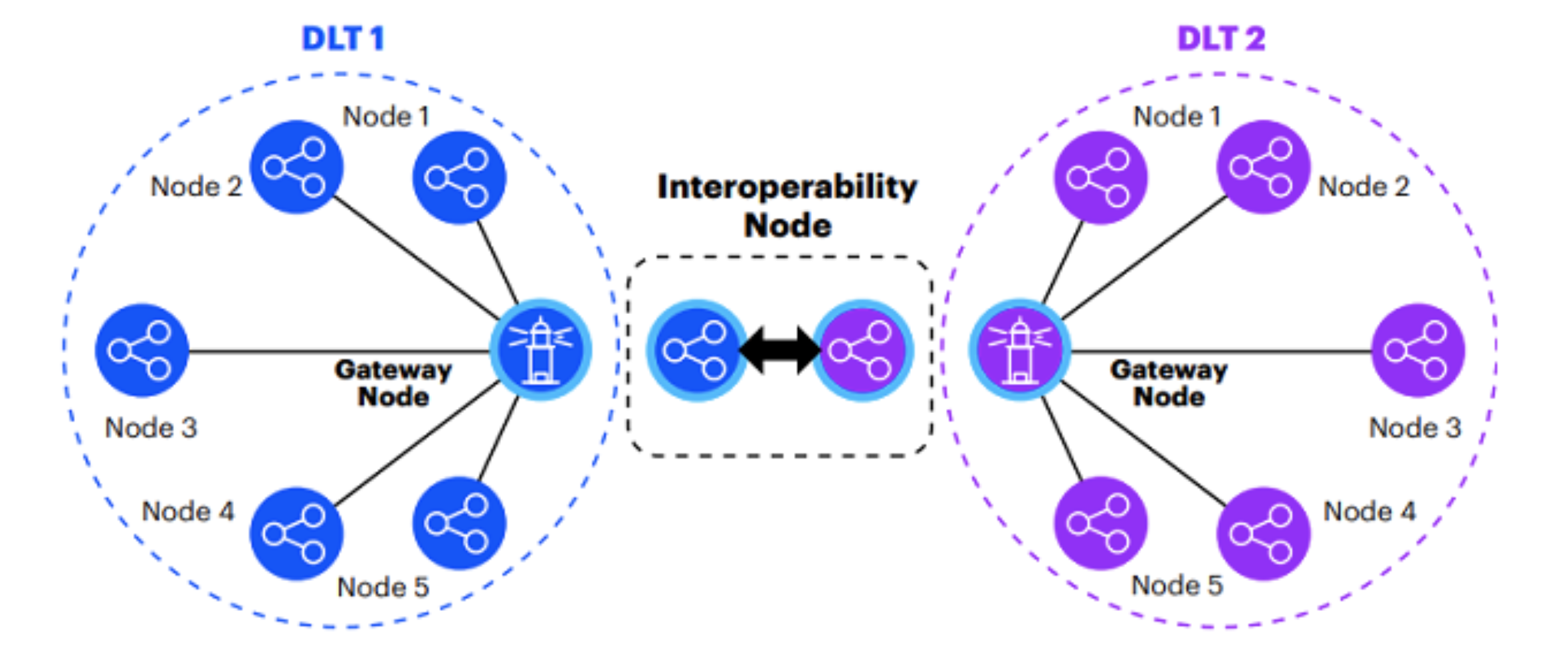
The interoperability in the blockchain field, why is it not explicitly mentioned in traditional Internet applications? Because the Internet infrastructure now provides these functions, such as various SDKs and APIs. If you make an application and want to call the data on WeChat, then you can get the data down through the SDK and interface on WeChat. If you want to make a payment, Alipay also has a corresponding payment channel. When you write the code, you can call the API to make the payment. At present, the reason why it cannot be done on the blockchain is that our data is still in an isolated state due to the different consensus and block structures of various blockchains. In order for the data on different islands to communicate, we must connect different blockchains through interoperability and cross-chain systems.
What are the specific ways of interoperability and cross-chain protocols? The first way is the notary model. There is a notary between different chains. The second way to relatively decentralize is the side chain pattern. Through the side chain method, on the chain B, it can be verified which transactions on the chain A are written into the block, then the chain B can verify the operations on A and perform corresponding operations on B such as transfer. The third method is hash time lock. This is a relatively complex protocol. It is a cross-chain operation that integrates decentralized and transparent transaction assets conversion. To put it simply, if I trade bitcoin for Ethereum, I put a lock on Bitcoin, and at the same time, the other party also puts a lock on Ethereum. I give him the key, and I can get the corresponding Ethereum with the same key, and at the same time he can get the corresponding Bitcoin based on the key. There is also a time lock, which guarantees that both parties can only unlock Ethereum and Bitcoin within a limited time, otherwise the agreement will automatically terminate and neither party will obtain the assets of the other.
2.9.3 元宇宙的互操作性
Understanding Metaverse Interoperability
Interoperability is the preeminent driving force behind the development of the metaverse. Let’s take a look at blockchain technology to decode how interoperability works in the metaverse.
In blockchain environments, we have both non-interoperable as well as interoperable platforms. However, interoperability is imperative if we are seeking to devise blockchain-powered high-utility services in the metaverse.
Interoperability equips the blockchain ecosystem to communicate, use one another’s features and services, share arbitrary data, and more. Similarly, interoperability enables a myriad of metaverse projects to function in a unified manner through sharing of services, data, features, and experiences. It also allows cross-platform trading as well as other activities that are nearly impossible to function in siloed spaces.
To understand the concept of metaverse interoperability in a different way, let us take a look at the internet. It is equipped with layered standards that enable diverse networks as well as subnetworks to seamlessly interact with each other.
In the real world, when we move between different locations, our identities also travel from one place to another without any trouble. Even our assets and possessions can be effectively transferred to different locations without undergoing any major changes. It signifies that there is a continuity in the real world that altogether keeps us as well as our assets intact during any transit.
This is the reason why metaverse – the integration of borderless virtual worlds – aims at furnishing a transparent platform for socio-cultural interaction, similar to the physical world. Such amalgamation would make all digital realms, irrespective of their canvas and size, an integral part of a larger existence or entity.
Domains of Interoperability
To illustrate various domains of interoperability in the metaverse, here is a representation for a quick reference:
- Connectivity: Networking, communications
- Persistence: Ownership, Identity, History, Accounting
- Presentation: Physical properties, graphic models
- Meaning: Semantics, metadata, ontologies
- Behavior: Economies, rules, consequence, power
2.9.4 RealityIS中的互操作性
由前面的内容可以看出,传统的互操作性主要聚焦在两个不同的系统之间进行信息交换,例如:
- 在HTML中执行JavaScript脚本
- 在JVM之间实现不同语言的相互调用
- C和Lua之间的函数调用
- 在两个独立的区块链中联通,已实现跨链的交易,并确保链之间的信息交换是可信的
- 在多个应用程序之间能够正确识别不同用户的身份、经济、物理外观等一些基本属性
尽管看起来很好的概念,但实际它们本质上并没有形成数字经济模式的革新。因为所有这些所谓的互操作:
- 要么通过传统语言的一些互操作性特性可以实现
- 要么是传统的互联网应用之间通过各自的API或者SDK早就已经实现
RealityIS对互操作性有全新的理解和目标,这些需求是未来计算架构和消费者数字经济模式的客观需求。为了更好地理解这些需求,我们先来看看传统的互操作性 有哪些不足。
2.9.4.1 传统互操作性的不足
传统的语言互操作主要强调两个方面:
- 数据共享:两个系统之间可以传递消息,当然这个消息通常不仅仅是单纯的字符串,而是包含两者都能够理解和解释的格式协议,它们通常是包含一定的数据结构,这个数据结构往往是两个系统之间形成的通信标准。
- 代码共享:其中一个语言或者系统编写的部分代码,可以在另一个系统中执行,例如JavaScript代码,或者在JVM上使用不同语言开发的库,例如Scala语言可以直接调用传统Java语言编写的代码库。
尽管是两个语言之间的互操作,但是总的来讲,在传统的互操作概念中两个语言通常并不对等,其中一个往往是另一个语言的辅助系统。其主要的反映出来的特征是整个程序运行在其中一个系统或语言中,我们可以暂且称为宿主语言,另一个语言没有自己的运行时,它的代码需要依附在宿主程序的运行时中运行,而宿主语言或系统之所以能够运行外来语言,是因为它们提供了一个虚拟机,该虚拟机能够执行这部分带来语言的代码,并可以借助虚拟机与宿主共享内存数据。
尽管看起来两个语言之间可以共享内存,但实际上这些内存中数据的所有者通常是宿主语言或系统,这些内存中的变量或者对象基本上都由宿主程序分配和管理。外来语言尽管可以用于声明或构造自己的变量,但这些变量通常是局部变量,外来语言的代码总的来说更像是一个函数,只不过这个函数可以在宿主程序中执行,并且通常由宿主程序进行调用。
之所以两个语言之间形成这种不对等,是因为一个语言对应的程序在运行时是需要花费大量的代码进行整个程序上下文的数据构造的,而作为一个简单消息传递过来的代码,根本不足于构造大量属于它自己的上下文数据。
尽管理论上可以编写复杂的代码传给宿主语言,或者在宿主语言中执行,但是这么多的代码与宿主程序的交互将是非常复杂的。所以大部分互操作主要是用来实现一些两个系统之间的少部分通信。
这种级别的互操作性不足于真正打破两个应用程序之间的割裂。
我们真正需求的,也是RealityIS定义的互操作性,是将两个语言或者系统看做对等的程序,它们不存在宿主和外来语言的概念,它们同时都拥有自己的全部数据,它们同时拥有各自完整的全部程序,它们之间随时可以进行任何代码与数据之间的相互调用和共享,只要用户用户它们有这样的权限。
2.9.4.2 多应用互操作性
传统的互操作性,其根基还是面向单应用,它解决的是单应用或者单个系统跟外界之间怎样通信的问题,这种通信通常很简单,比如对于微信、支付宝来说,调用它们提供的API其实就是一种和这些系统的互操作。这种互操作之间传递的信息用一些简单结构的字符串都可以。这些系统之间的协议或者标准通常也比较简单。
因此传统互操作性通常表现出一下几个特征:
- 通常是单向的,两个系统之间通常不对等,表现为众多小应用依附于一些大的平台,例如现在的小程序、微信平台等
- 通常通信的内容比较简单,扩展能力较差,例如如果需要扩展一些消息,就需要重新定义双方的解析格式,更不用说可以实现任意消息通信了
RealityIS跟这些机制的最大不同,在于它尝试解决两个更复杂的问题:
- 对等性,即互操作的两个程序或系统之间是对等的,不是依附的关系
- 扩展性,可以比较容易地实现任意通信,而不是局限于少数(也比较容易实现的)协定的格式
上述的要求对互操作性的计算架构提出了全新的挑战,传统的编程语言基本上很难支持这样的要求。
对等性对计算架构提出的主要挑战是内存和运行时共享,即所有子程序共处于一个内存和运行时环境,它们均有各自的完整的内存上下文:即所有数据和代码,抛开掉互操作性的需要,每个子程序都是一个独立真正的程序。因为共处于一个内存和运行时环境,它们之间随时都可以进行任意通信。
这是一个计算架构的根本变革,传统的计算架构都是针对单应用的,因此整个内存的数据都可以由该程序自由控制和处理,现在编程语言的执行过程和整个编译过程都是围绕整个目标设计的。
而让多个应用程序共处一个内存环境,这个首先带来的挑战就是数据安全:如果按照现有编程语言的机制,一个子程序的指针使可以访问任意地址的,这将使得程序不再是安全的,现代编程语言没有任何机制可以保护这个问题,它们只是简单地假设,只要你的代码在一个运行时环境中运行,那么整个内存环境都是你的,你可以任意破坏,实际上就是因为代码有任意破坏的能力,才需要各种语言机制(如类型检查)来约束开发者进行安全编程,而像C这样的语言就通常很容易编写出不安全的代码。
对于这个问题,由于目前我们无法从根本上突破这一缺陷,可预见的短期将来也不会有类似的计算架构来支撑这种需求,所以我们只能基于当前的编译架构来实现这样的功能。而当前编译体系下唯一能够实现这样功能的方式,可能是:
不让子程序在堆上分配任何内存,它们只能在自己的函数堆栈上实现变量的分配和使用。换句话说,子程序不能使用指针,不能构造对象,无法引用对象,它们能够使用的都是在栈上分配的值类型。
相对于现代任何编程语言来讲,上述这些约束都是极大的限制,这也必将大大限制程序的能力。然而RealityIS使用了一种特殊的机制来保证即使在这样的限制下,语言背后的运行时和机制能够保证开发者可以实现任何其他语言可以具备的能力。这些机制参见前面章节的内容,但这里总结它的核心理念和机制是:
函数式编程的思维证明多个独立纯函数可以复合构成成复杂函数,进而解决任何逻辑问题,而纯函数本身,除了它没有内部状态这一外在概念之外,从编译机制来讲,它的一个核心的约束是每个纯函数只能在栈上分配变量,因为这些变量会随着函数的调用结束而丢弃,所以它们不能存储状态;反之,如果允许一个函数能够构造或者访问一个对象或者引用类似,那么这个函数可能就会记住某些状态。
通过上述的机制分析,我们完全有可能构造一种多应用对等共享同一内存和运行时的机制,在此基础之上,只需要做大:
- 多个子函数组件可以由运行时来组合为复合函数
- 运行时来管理子程序自身所属数据(不是函数内部的局部数据,而是子程序的数据)
- 提供两个子程序函数相互调用的机制
- 以及在这个调用的过程中添加一个权限控制
RealityIS实现了上述所有机制。
当然,与传统的互操作性概念不太一样的是,传统互操作性更强调两种语言之间的互操作。而RealityIS目前只能支持单语言的互操作,尽管从JVM的角度看,支持多语言也不是不可能,但是由于CreationScript本身已经是一种极度简化的语言,这样的多语言支持没有太大的意义。传统的多语言互操作是因为不同语言之间往往存在着较大的特性差异,或者擅长处理的子系统具有不同的特征,这些问题在RealityIS中是不存在。
尽管如果,RealityIS本身是一种通用编程架构,理论上可以处理任意逻辑,并且RealityIS内部也是两个子程序之间的互操作,并且是对等的子程序。这样的互操作能力,要大于传统的互操作概念。
关于扩展性,这涉及另一个概念,即标准相关的问题,参见下一节的内容。
2.9.4.3 标准与供应关系
可扩展性实质是涉及标准的问题,应用之间的互操作必然通过标准来实现,因此可扩展性的问题是关于能够怎样简单高效地涉及一个标准,能够让希望进行互操作的子系统之间快速集成支持这样的标准。
我们先来看看传统的互操作之间标准的机制是怎样运作的。传统的大平台如微信和支付宝,它们有比较大的影响力,所以它们提供的标准大家都会去遵守,即便这种标准的规范特别差,开发者也只能去兼容和支持。
另一个问题是平台之间定义标准的方式差别很大,造成分化,小开发者需要针对不同的大平台适配不同的标准形式。比如一个游戏通常要针对不同的发行平台介入很多家SDK,但本质上它们的功能都差不多,这也导致一些提供统一服务接口的服务,例如AnySDK,例如Unity提供的ARFundation很大程度上都是在统一ARCore和ARKit的接口。
第三个问题是,所谓的互操作通常只有小应用去集成大平台或者大应用,而大应用不会去兼顾小应用的互操作性。所以这是一种附属应用,附属形态,而不是一种共生平等形态。但这种形态其显然的缺点是,这种生态它的总体功能就是围绕大应用或者大平台的范围去扩展的范围,这个范围的大小基本上是受大平台本身的性质所影响的,例如围绕YouTube的就是视频生态,围绕微信的社交生态,以及围绕支付宝的电商生态。
要想开发一个共生共享的开放平台,显然标准的形态需要变革。这至少需要思考两个方面的问题:
- 一是统一标准制定形式,怎样让大家制定更容易集成、更统一、更简单地规范形式
- 二是让影响力没那么大的组织或者系统制定的标准,能够有机会慢慢进化,进而有可能让影响力更大的系统来反向支持,实现系统之间的对等
以前是通过影响力带动标准,由它们来制定标准,所以整个互操作的生态核心还是大平台的地位。小应用没有机会去提升自己的影响力。
在RealityIS中,我们更希望它像真实社会,每个组织或个人都可以去发起自己的生意,只要它们的生意做得足够好,慢慢就会提升自己的影响力。而且,当其他的组织或者个人发现这个产品的时候,他们也能够很容易地与之建立供应关系。
供应关系,而非平台影响力的延伸,才能真正促进创新。而大平台会扼杀很多创新,并且会抢夺很多具有创造能力的个人或者组织的资源,而这靠的不是实力和产品,而单纯就是平台的垄断能力。
如果平台的影响力不再是主导的,那么标准本身就应该是一个很重要的因素,在平台给每个组织或个人提供公平机会使大家都有机会成长的时候,还需要一个能够使之与其他组织建立供应关系的简单机制。
所以我们将标准单独分离处理,分离之后,标准的地位提升,标准是公立组织,它不受其他实际开发产品的组织或个人的影响,当然它们可以形成建议,但总的来说,那些有影响力的大应用没有办法通过标准去扼杀小应用,因为标准本身具有一个巨大的能力:
- 标准是开放的
- 标准只是通信接口,它不是管道或其他东西,你没法控制
关于标准相关的内容参见4.11节,RealityIS的标准机制使得任何子程序之间可以就任何感兴趣部分进行通信。
2.9.4.4 为了可组合性
理解RealityIS的互操作的另一个维度是互操作性与可组合性的关系,RealityIS的互操作性不仅仅是为了应用之间的通信,这种通信的目的主要是为了实现自动组合,从而大大简化应用开发。
可组合性跟互操作性是高度关联的,实际上它们并不是独立的概念,组合是需要互操作辅助的,因为组件或者函数之间终归是有联系的,需要解决这个联系,现有的体系就是只考虑解耦而不去维护这个联系,所以到目前为止几乎找不到比较好的可组合性的架构,原因就是没有解决互操作的问题,但反之解决了互操作,可组合性更像是一个结果,所以其实核心是互操作,这涉及编程语言架构,这就是为什么我们一直当作最核心的问题。
如今的编程语言,虽然通过软件架构设计,程序可以做到一定的可组合性,但是这些组合性几乎都市针对开发者的,普通用户很难利用到这种能力,这是因为这些逻辑上的组合,本质上就是某种形式上的函数调用,这就不可避免的会涉及到函数的定义、地址、参数列表、数据类型等等这些程序的机制,而普通用户既无法学习和理解这些概念,也很难在运行时不通过代码的方式去拿到这一切信息。
通过RealityIS针对互操作性设计的一套标准运作机制,RealityIS的组件之间可以隐式地进行函数调用:函数之间不再需要显式指定调用函数的方法名称、函数地址、参数数量、参数的数据类型等等信息,而是它们仅仅需要针对一定的标准接口实现自己感兴趣的功能即可。正是这种机制,使得用户不需要去了解一些程序术语,这样组件就可以被当做一个语义上的功能看待,因此使得普通用户能够比较简单地去定义自己的程序或者逻辑。
因此,RealityIS的可组合性,其实是需要依赖于它的互操作性机制来实现的,否则我们用于无法破除传统编程语言的限制,这样即使有较好的互操作性,也只能主要针对专业开发者。RealityIS通过互操作性实现的可组合性,使得RealityIS平台的价值有了更大的空间。
相关内容参见2.7.10节。
2.9.5 交互模式
除了编程语言提供的机制本身,程序之间的通信或者互操作往往还涉及一个调用方向的问题,这个在游戏开发中尤其明显。
在传统的编程语言中,特别是面向对象编程语言,方法和数据往往都是封装在一个类或者一个相对相关的模块当前,这就导致函数的交互具有不同的模式,这些模式对整体架构和复杂度都有一定的影响。
以面向对象为例,设想有一个角色对象A,使用了一个道具砍伤了一个怪物对象B,对其造成5点伤害,根据其交互模式的不同,这里可能有一下三中逻辑组织方:
- 造成伤害的代码封装在A类中,因为我们认为是角色的动作导致的结果,所以A类中的某个方法需要取得对象B的引用,然后对对象B中的HP变量进行修改,因此这也要求B暴露该属性的访问权限。当然我们可以将对这个属性的修改改为方法的形式,让A对调用这个方法,但两者本质上是类似的,这里面的核心问题是A需要调用B。
- 为了解除两者之间的耦合,另一个方法是采用响应的模式,A不会直接修改B,而是发出一个消息到一个地方,然后B会去这个地方检测这个消息,如果发现具有某条消息,则执行一个掉血的计算,这个过程A和B不会耦合,这个具体的扣血操作主要是由B发起的。
- 当然还有一种非面向对象的方法,这种方法以方法为核心,它同时传入A和B两个对象,这种方法尽管A和B之间不会直接耦合,但是这样做的意义不大,除了要在额外不相关的地方去维护这种关系,而且一旦由任何结构的修改,几个地方也会受到影响。
选择第一还是第二种,一般的编程语言并没有限制,但是在大部分游戏程序中,选择一的可能会更多,这种方式更直接,而二会带来一些额外的结构以及维护,并且没有一那么容易调式。但是一实际上会带来很多问题,我们把一称为主动式,相应的把二称为响应式。
2.9.5.1 主动式的缺点
主动式编程直接引用另一个对象, 并通过调用另一个对象的方法或者属性访问来进行交互,这种方式几乎是任何编程语言原生支持的机制,它也是编写起来最直接和简单的机制,但是这种方式由很多缺点。
主动式编程的问题大概可以归为以下几类:
- 耦合
- 逻辑关系
- 扩展性
- 并发
首先对于耦合,很明显A直接调用了B,A和B之间存在直接耦合,如果A和B之间相关调用部分的结构发生变化,两者都必须响应调整。此外,耦合带来的更大的一个问题是,为了访问B的成员,类B不得不将这些变量或方法的访问权限公开,这就会导致任何代码理论上都可以访问,造成较大的安全问题。尽管现代编程语言会提供一些成员的权限范围,例如程序集内部,友元等机制,但这些权限控制的灵活性远远不够。
其次,主动式编程带来逻辑上的一些关系混乱,有时候A和B直接并没有必要的因果关系,但是其流程上也可以这样去执行。再比如有时候我们单纯从类B去考察它的功能,我们可能根本不知道它什么时候会被调用,被谁调用,我们无法预测程序的逻辑关系,尤其是在面向对象结构中再夹杂着状态的情况。此外,对于类B的一些影响,这种影响有时候可能并不仅仅来自A,还要考虑其他对象的影响,但是A作为调用方可能根本无法去感知这样的事情。实际上通过下一节的内容可知,响应式的逻辑组织方式才是大部分活动进行交互的逻辑。
对于可扩展性,这跟耦合实际上也是相关的,由于B执行什么样的逻辑以及什么时候执行由A来控制,这个时候,如果B对于某一类事件发生时,有其他的一些逻辑变化,或者说受其他一些新加入的因素的影响,它很难通过在不影响A的情况下进行自我进化或扩展。这种扩展不仅仅是要求A修改接口那么简单,有时候涉及会融合更多的逻辑,这样调整起来的代价就会很高,而我们后面会看到,如果采用响应式,A的影响就只是会抽象为一个因素,而B可以自行考虑各种因素之后做出真正的响应。即使响应的逻辑或者规则变了,但是只要A这个因素本身的逻辑没变,A就不需要进行任何修改。这样的方式就使得B很容易进行自我进化与扩展。
最后,主动式编程往往导致并发问题,对个对象对B的调用完全不会也不可能考虑到B的状态,例如是否正在被其他的进程访问。这中情况就很容易导致共享竞争,而且除了加锁几乎是无法避免的。而响应式编程,它们通常可以通过先收集各种影响因素,然后进行统一的消息处理,而避免任何并发的问题。因为内部的消息始终是串行的方式执行。
2.9.5.2 一切皆是响应
现代编程的一些机制往往是受硬件架构,以及编程语言编译过程的一些限制或影响,它们原生并不是为了模拟真实世界的交互方式。我们可以首先来观察一下真实世界的一些活动交互方式。
首先考虑人与人之间的人类活动,比如法律,国家会指定一些法律以约束人们的一些行为,从面向对象编程的角度来说,我们可能编写一个法律机构的对象A,然后用B来表示人类,A可以通过调用B的属性或者方法要求B不能违反某个法律。但是实际上,在人类活动中,人是思维的主体,人类的整个活动几乎都是由众多个人意志决定的结果。虽然从某种程度上说,在宏观的角度看,个人的意志是受一定的约束的,但是我们并不能由此就按照主动式的方式对整个人类活动进行编程。除了这种负面的事宜,即使是正面的活动也是如此,例如我们可以给别人很多忠告或者建议,但即使这些忠告或者建议真正是被证明有价值的,其他人仍然有可能因为某些因素而选择不去采纳。

实际上,这正是一种响应式的体现。响应式编程是以接受信息者为中心,它假设接受信息的对象拥有自我意志,它应该由自己来决定应该怎样基于外部的信息进行决策和响应。正是这种自我意志,从程序的角度不光使其更具有扩展性,从进化的角度,这样的系统能够产生出更加丰富而创新的成果。而如果是主动式编程,在很多规则几乎就是一定的情况下,一个系统很难具备有进化能力。
再来分析一些大自然活动,尽管它们看起来物理客观规律是固定的,理论上我们可以使用主动式编程来处理所有事情。但实际上任何事情都是受到各种复杂环境因素影响的,例如一个物体从空中掉下来,取决于地面是水、泥土、混泥土、火等各种情况,其结果会完全不一样。
所以我们看到,任何事情的影响,都无法有确定性的因素,如果一个物体的某个结果需要有外部某个对象来决定,这通常是不合适的。既不具备扩展性,同时也不能保证正确性。只有物体自身,它任何时刻都能够感知自己的环境,只有基于所有环境因素的综合性判断,才能更好地决定其结果。
所以我们看到任何事物时间的交互,几乎都可以归结为响应式。
2.9.5.3 响应式的缺点
当然从编程的角度,响应式编程也存在一定的问题,主要是以下两个方面:
- 性能问题
- 反馈机制
对于性能问题,例如有多个类型B的对象列表,原本A只需要遍历以下队列B,修改以下属性即可,但是现在可能需要给每个对象B添加一个方法,然后由B分别执行一下方法。尽管看起来会存在性能问题,但是对于相同的逻辑,两种方式调用的核心代码几乎是一样的,剩下就是不同机制在组织数据的差异,但是这种机制上的差异相对于核心代码来讲,几乎是可以忽略的。本质上两种方法的性能差异不大。
第二个问题属于响应式编程特有的一个问题,比如如果A需要扣掉B的某个数值变量,如果整个逻辑正常执行当然没问题。但是设想如果B的这个资源不够的时候,可能这个操作不应该执行。如果是采用主动式,由于A是可以访问B的成员的,所以他可以直接判断是否可以执行计算,这就简化了整个问题。当然其代价是B不得不暴露数据访问权限给外部,造成巨大的安全问题。
对于这种情况,我们希望所有涉及双方资源变化的计算放到一个组件中执行,每个组件可以涉及两个对象,两个对象都携带各自相关的属性数据,然后通过一些特殊的交易函数来获得权限。
2.9.5.4 响应消息属性
在了解响应机制的方式之前,我们要先了解响应式编程的另一个特性,即事件消息。
传统的响应式编程主要通过事件消息的机制来实现,这通常由两大类:
- 一是按类型建立全局的事件列表,然后响应事件的对象分别从这个列表去获取事件消息
- 另一种是类似Erlang的机制,系统会将这些事件消息分发到具体每个进程内部,形成一个进程的局部消息列表
不管上述哪种形式,它们的一个相同点都是,这个消息列表只是临时存在,一旦系统注册的所有响应者都处理完毕,消息就会被丢弃。
在RealityIS中,我们的消息通知机制不是按照上述两种中的任意一种组织的,而是按照普通的函数传递机制,并且这个函数传递是每帧都执行的,所以这就会导致一些问题,例如某个技能释放之后,发送一条扣除HP数量为3的消息,响应者在扣除3个HP之后,这个值可能会在下一帧被保存,除非开发者保证发出消息的组件每帧总是执行。但是RealityIS的Change-Driven机制使得有可能绕过这个状态。
所以我们通过对属性定义一个属性来实现,比如:
[Message]
float HP
如果是Message属性,运行时保证在每帧的所有组件执行完毕之后,将其清零。但这可能不一定是最好的形式,这一块还要进一步思考。
2.9.5.5 简化的响应机制
对于反馈的问题,传统的解决方案是往回发送确认消息,但这带来一定的复杂性。
其实分析一个程序,在大多数请下它们是可以正确执行的,只有在少数极端情况下程序会出现异常,例如硬件问题,但是实际上我们却要为了防止这种问题,而对所有消息处理使用一种反馈的机制。反馈涉及到异步,每个程序的通信都要维护这种异步的确认信息。
考虑到游戏的一些特征,游戏中大量内存当中需要记录和计算的一些对象不一定都需要需要存档的,如果把所有这些数据存档,会导致很大的问题,即程序在恢复的时候根本无法精确恢复到某些中间状态。
所以RealityIS改变了一种策略,它只对某些关键时间点进行存档,而在这些存档节点之间,一切数据都是可以丢弃的。所以当有异常发生时,我们简单地恢复到上一个存档节点即可。
2.9.6 为OSI构建全新的互操作层
2.9.6.1 第三方应用
2.10 GPU VM
2.11 Render VM
2.12 RealityIS Runtime
RealityIS Runtime可以给第三方使用,通过集成到第三方App形成独立分发的App形态。RealityIS Runtime包括两个部分:
- 端侧的运行时,负责渲染以及资源加载相关的逻辑
- 云侧的运行时,负责云端的分布式能力
基于此,其中的一些变化包括:
- 在端侧,开发者可以集成自己的C++库,可以扩展应用的能力,并与本地App其他模块进行通信
- 在云侧,开发者可以使用自己的服务器中心,也可以通过C++扩展能力
不变的部分:
- Creation的托管存储是不变的,这个只面向开发者,但是运行时的实际数据都是存储在自定义服务器中的
- RealityID是不变的,用户仍然需要注册RealityID,进行统一安全验证,但是开发者可以跟自己数据库的记录进行映射
从价值上看:
- 统一了应用开发的方式,简化了部署
- 开发者可以使用C++对系统进行扩展
- 开发者可以把RealityIS当做一种面向领域用户自定义的、统一、简单编程或者自定义的机制
2.13 性能因素
2.13.1 局部性丧失
过去很多函数内部的临时变量,其生命周期本来只包含函数内,等函数调用结束之后就会释放,但是由于需要在上下游函数之间传递参数,它有可能会升级为实体变量,这就导致其存储时间比较长,内存占用更多。
即局部性丧失
首先对于传统OOP中的私有变量和公共变量而言,这些变量本身就是持久存储的,所以这部分影响不大。
主要是大部分函数内部的局部变量的使用,这里分为两种情况:
- 如果在传统中单个函数可以独立完成的事情,在RealityIS中也是独立完成,那么两者是等效的
- 如果传统OOP中的一个复杂函数需要拆成多个函数,这种情况在传统OOP中尽管函数的执行时间边长,但是语言机制保证其存储时间最多也只在函数执行期间;对于函数式编程,不管嵌套结构如何,也能保证只存储于需要的嵌套期间,跟OOP基本上等价。
对于RealityIS来说,组件的顺序是被打乱的,无法保证相关的两个逻辑一定是按紧邻执行的,极端情况下可能中间隔了很多无关的组件,甚至可能后续都不会再被使用,例如后续的条件判断导致无法进行相应组件分支,因此很难预测其变量的存续时间。
但好处是它只分配一次,避免下次对该变量的重复构造。以存储换取计算(这里主要指对象的分配和初始化,销毁等操作)的一种形式。
当然这些变量跟垃圾回收中的变量还是不一样,至少这些变量的生命周期是跟实体对象一致的,它们会随着实体对象的销毁而自动回收。
一种优化方法是,这些没有标记永久存储的、临时的变量,在每帧结束之后全部销毁,这样至少下一帧还没有初始化 这个变量的时候内存占用是不需要的,但是这样解决不了根本问题,因为每帧结束的时候内存还是会很高,而这些形成一个阈值还是会限制单台服务器的能力,而且这种优化带来复杂性。
最好的指导是
如果一个对象的变量不涉及跟其他对象通信,则最好所有涉及的私有操作都集中到一个函数,直到输出全局属性未知,这样内部的变量都是临时变量,跟OOP一样的效果。如果对象之间需要通信,那么这相当于OOP中的对象私有变量,本身也是一直存储的,这也是等效的。
当然这有点违背组合的思路,但是我们所提倡的组合思想,也并不是说把所有函数拆成小函数,组合的是结构性的。
另一种是对于已经编辑好的对象,可以对组合进行合批操作,即将那些经过组合形成的多个函数,如果他们中间处理的都是私有变量,并且没有外部交互,可以合批成一个函数的效果,当然这可能需要在函数派发层做一点工作,不过这可能也会带来运行时性能。
但考虑到分布式的结果,单台机器不会成为性能瓶颈,而且现代计算机计算是瓶颈,而内存并不是大的瓶颈,除非那种数据结构特别大且不易于拆分的场景,总体来讲问题不大。
2.13.2 无效计算
传统的应用程序一般比游戏程序的性能高,是因为应用程序大多采用事件驱动的机制,主循环只有一个,当当前任务处理完毕时,它会在某个地方处于等待状态,或者就是告诉操作系统没有再需要执行的任务了。当系统检测到某个事件时,一般是用户输入事件,操作系统会触发代码的执行,为此,一般的方式是在main中维持一个小循环来专门检测系统事件,以便于接收到系统事件的时候可以正确触发执行逻辑的代码,因为其他应用程序的逻辑指令已经停止。
由于传统应用程序的逻辑结构是隐藏于代码中的,所以这很容易通过代码来控制整个流程,例如如果用户输入没有发生,那么条件判断逻辑会保证后续的逻辑都不需要执行计算。
但是当无序的计算指令被转换为有序列表之后,带来的一个代价是这种前后逻辑分支控制能力的丧失:后续的函数唯一的影响因素是输入参数,只能根据参数进行判断是否要进行计算,但因为数据全部是被放到block里面的,所以必须检测block中属性状态的改变,主要有一个发生变化就需要执行函数计算。
2.14 底座:链接和加载*
2.14.1 RealityIS核心基础
尽管上层系统有很多不同的机制、不同的软件架构思路,但RealityIS的核心基础其实是计算机程序链接和加载的机制和原理。
多年来,链接和加载的原理基本上都没有太大变化,而上层的编译原理和更下层的硬件指令和汇编都是有一些变化,这使得链接和加载的重要性没有被给予足够的重视。尽管它非常简单,但是它却对上层的编译过程甚至编程语言有较大的影响,多年来,这种影响不是体现在它促进了上层的发展和进化,相反,它束缚了上面的进化。
链接和加载有很多重要的特点,使得它既重要又足够简单,同时对上下游有较大的影响,更确切说较大的约束:
- 它非常简单
- 它是一种非常优雅的结构性抽象
- 它对编译过程和编程语言的设计产生了巨大的束缚
- 它是
正因为如此,RealityIS诞生最关键的进程是首先从符号表得到启示,而不是相反从游戏程序的结构着手。前者可以认为是自下向上的,而后者是自上向下的。没有对符号表的关键理解,游戏程序结构的管理只能用作开发商内部更好的程序结构组织,尽管也可以简化程序的开发,使用复用来提高工业化生产,但是它无法直接到达互操作性。对符号表的启示才导致了互操作性的一切机制。而符号表正是链接和加载的核心。
2.14.2 程序结构性
2.14.3 新型动态链接
2.14.3.1 将目标文件合并在一起
这种架构产生了较大的影响,其中最核心的是整个程序必须是一个整体,而这是因为:
- 性能,将每个函数都独立存储在内存中,会导致动态查询较大的性能开销,这是由于内存的寻址架构决定的,我们不可能针对每数据段和程序段都分配绝对地址,那样不管是编译和运行时的过程都有巨大影响,而相对寻址使得程序更容易合并为一个整体。针对这点,RealityIS将程序结构进行了简化处理,使得这个动态查询的开销变得很低。
- 二进制的安全性,动态组织存在较大的二进制版本问题,进而产生安全性问题。针对这点,RealityIS在更上层的脚步语言层面进行动态组织,减少对二进制文件的依赖。
2.14.3.2 二进制安全性
2.14.3.3 版本管理
2.14.3.4 性能:大量的符号解析和查找
传统的动态链接技术中包含较大的共享库符号表、程序对共享库符号的引用都需要动态查找符号表,因此引起较大的性能开支。
RealityIS通过两个方面来减少性能开支:
- 没有组件函数内的全局符号查找,函数都是静态指针,这得益于函数式编程的风格,每个组件都是纯函数,即使对于iOS系统,只能采取解释性的执行方式,这种情况函数使用的地址也是在一个很小的内存地址空间,此时的代码形成一种“隐式的符号表”,因为我们通代码获取符号在栈中的地址,这避免了大量的全局查找
- 即使对于RealityIS运行时,他需要查找全局符号表来获取地址,我们的符号表结构也更加巧妙。这种查找被转化为另一种形式:即在编译时建立了函数组件和符号之间的关系,然后这种关系在加载时被保存为内存中数据和代码的一个影视,这就是一个C++的指针就找到了对应的地址,所以这间接避免了运行时每次符号表全局查找,因为它只在加载时计算一次,而不是需要每次遇到符号动态且重复查找。组件和函数之间的确定关系带来了很多好处。
2.14.4 多任务系统安全性
将在2.16节专门讨论
2.15 复杂系统和细胞模型
2.15.1 复杂系统
2.15.2 细胞模型
But for Dr. Kay, he states that OOP to me means only messaging, local retention and protection and hiding of state-process, and extreme late-binding of all things. Why? Well, part of his background was cell biology and when he did the math on their computational power, he realized that while software routinely has trouble scaling, cells can easily coordinate and scale by a factor of over a trillion, creating some of the most fantastically complex things in existence, capable of correcting their own errors. By comparison, the most sophisticated computer software programs are slow, tiny, bugfests. Kay's conception of OOP starts with a single question: how can we get our software to match this scalability?
2.15.2.1 Isolation
First, let's discuss isolation. This is a shorter term than "local retention and protection and hiding of state-process".
The interior of a cell is messy and confusing, but the cell membrance wraps this up in a tidy package, hiding the internal details. It's estimated that around 50 to 70 billion cells die in your body every day. But you don't. Could your software keep running if you had millions of exceptions being thrown every minute? I doubt it.
You not dying when your cells die isn't encapsulation; it's isolation. Consider the following (awful) example:
class MyExample:
def reciprocal(self, num):
return 1.0/num
example = MyExample()
print example.reciprocal(4);
print example.reciprocal(0);
In the above code, we've encapsulated the reciprocal equation in the class, but then ...
0.25
Traceback (most recent call last):
File "class.py", line 7, in <module>
print example.reciprocal(0);
File "class.py", line 3, in reciprocal
return 1.0/num
ZeroDivisionError: float division by zero
The object dies, as does the code which contained it. This is the antithesis of what Dr. Kay is trying to get us to understand.
If you think of Web browsers and servers as objects, however, we see something closer to his vision. If your browser crashed every time a web server crashed or was otherwise unavailable, Microsoft IIS would never have reached 2.0.
Now that we sort of understand a core idea of Kay's, Lets take it further. Kay points out that from the early days of Arpanet in the 60s, to the time of his OOPSLA keynote in 1997, Arpanet had grown roughly 100 million times the size of what it was. And it didn't have to be repeatedly taken down for maintenance every time we wanted to extend it. The internet, today, is sometimes cited by Kay as the only working example of his OO model.
2.15.3 面向对象编程模型
2.15.3.1 Is Erlang object oriented?
Joe Armstrong: Smalltalk got a lot of the things right. So if your question is about what I think about object oriented programming, I sort of changed my mind over that. I wrote a an article, a blog thing, years ago - Why object oriented programming is silly. I mainly wanted to provoke people with it. They had a quite interesting response to that and I managed to annoy a lot of people, which was part of the intention actually. I started wondering about what object oriented programming was and I thought Erlang wasn't object oriented, it was a functional programming language.
Then, my thesis supervisor said "But you're wrong, Erlang is extremely object oriented". He said object oriented languages aren't object oriented. I might think, though I'm not quite sure if I believe this or not, but Erlang might be the only object oriented language because the 3 tenets of object oriented programming are that it's based on message passing, that you have isolation between objects and have polymorphism.
Alan Kay himself wrote this famous thing and said "The notion of object oriented programming is completely misunderstood. It's not about objects and classes, it's all about messages". He wrote that and he said that the initial reaction to object oriented programming was to overemphasize the classes and methods and under emphasize the messages and if we talk much more about messages then it would be a lot nicer. The original Smalltalk was always talking about objects and you sent messages to them and they responded by sending messages back.
But you don't really do that and you don't really have isolation which is one of the problems. Dan Ingalls said yesterday (I thought it was very nice) about messaging that once you got messaging, you don't have to care where the message came from. You don't really have to care, the runtime system has to organize the delivery of the message, we don't have to care about how it's processed. It sort of decouples the sender and the receiver in this kind of mutual way. That's why I love messaging.
The 3 things that object oriented programming has it's messaging, which is possibly the most important thing. The next thing is isolation and that's what I talked about earlier, that my program shouldn't crash your program, if the 2 things are isolated, then any mistakes I make in my program will not crash your program. This is certainly not true with Java. You cannot take 2 Java applications, bung them in the JVM and one of them still halts the machine and the other one will halt as well. You can crash somebody else's application, so they are not isolated.
The third thing you want is polymorphism. Polymorphism is especially regarding messaging, that's just there for the programmer's convenience. It's very nice to have for all objects or all processes or whatever you call them, to have a printMe method - "Go print yourself" and then they print themselves. That's because the programmers, if they all got different names, the programmer is never going to remember this, so it's a polymorphism. It just means "OK, all objects have a printMe method. All objects have a what's your size method or introspection method."
Erlang has got all these things. It's got isolation, it's got polymorphism and it's got pure messaging. From that point of view, we might say it's the only object oriented language and perhaps I was a bit premature in saying that object oriented languages are about. You can try it and see it for yourself.
2.15.3.2 消息与隔离
按照Alan Kay的定义,OOP的核心三要素是:
- message passing,
- that you have isolation between objects
- and have polymorphism.
大多数现代编程语言都支持多态,但是关于隔离的意义,大多数编程语言的理解是不太完整的。在面向对象编程语言中,人们说的更多的是封装而不是隔离,表面上看封装其实就是把各种细节隐藏在对象内部,从而实现了隔离。但这只是概念上的隔离,而不是真正运行时的对象隔离。
之所以提出isolation的概念,它的意义是为了保证大规模程序的健壮性,比如在1000个对象运行的程序中,如果有其中几个对象发生了错误,如果它的逻辑不会影响到其他对象,则整个程序应该不受到影响。所以它是从程序构造方面的意义,而封装并不能解决上述的健壮性问题,封装的概念更多的是面向程序员的理解而言的,让程序员把一组相关的方法和属性封装在一个对象上是易于理解和管理的。
所以从这个角度看,面向对象模型是面向软件构造的意义,即面向机器,而不是面向程序员理解的意义,而当今大多数关于面向对象的概念更多是围绕程序员的理解的角度。
那为什么对象封装解决不了隔离的问题,而Erlang解决了隔离的问题,核心原因在于Erlang为了保证健壮性,让每个线程独立运行,为了实现隔离,一个对象的Crash不能影响其他对象,所以Erlang把方法调用进行了切除。传统的编程语言,几乎除Erlang之外的所有编程语言,它们为了保证程序执行的序列,都是采用直接调用的方法,即当A对象调用B对象的方法时,A对象的指令会被挂起,程序会进入到B对象内部相应的方法进行执行,并且等执行完毕之后返回值给A对象,并将执行指令的指针返回到对象A调用方法后面的位置。
整个现代编译架构都是按照上述的流程构建的,比如在方法调用的时候,程序跳转到B对象相应的代码区域,并使用寄存器保存返回地址,然后方法执行完毕后跳转回到原来的返回地址。
可以看到,这样的流程对于编译器架构设计,以及程序员都是相对容易理解的:得到返回值后接着执行后面的语句,程序员的逻辑思路是连贯的。并且如前面关于响应式编程或者统筹编程相关的描述,程序员不需要额外保存计算结果,直接使用当前的值进行计算,这样的逻辑管理是最简单的。否则我们需要一套复杂的机制来管理逻辑,比如需要保存一些值在后面某个时候使用,而如果使用的时候代码在其他位置,还涉及怎么取得这些存储的计算结果。
然后这种耦合的逻辑破坏了隔离,
- 如果被调用方法Crash,比如会影响后面整个程序,所以我们只能让整个程序崩溃。还不说这种耦合导致了整个程序的单一性问题,即整个程序需要被一次性编译为一个整体。
- 其次,A对B的引用,形成了耦合,B不能动态更新,如果B有修改,也需要整个程序重新编译,即使动态语言,也会形成很深的依赖。
所以要实现真正的隔离,我们必须将方法调用切开,即A方法不需要等待B方法的返回继续执行,这可以有很多不同的实现机制,但不管怎样都会给系统架构和开发者带来一些不便,或者说不一样的体验。
We need to isolate all the code that runs in order to achieve a goal in such a way that we can detect if any errors occurred when trying to achieve a goal. Also, when we are trying to simultaneously achieve multiple goals we do not want a sodware error occurring in one part of the system to propagate to another part of the system.
The essential problem that must be solved in making a fault-tolerant sodware system is therefore that of fault-isolation. Dicerent programmers will write dicerent modules, some modules will be correct, others will have errors. We do not want the errors in one module to adversely acect the behaviour of a module which does not have any errors.
To provide fault-isolation we use the traditional operating system no- tion of a process. Processes provide protection domains, so that an error in one process cannot acect the operation of other processes. Dicerent pro- grammers write dicerent applications which are run in dicerent processes; errors in one application should not have a negative influence on the other applications running in the system.
-- from Joe Armstrong‘s Phd thesis
Erlang选择了让每个线程之间完全隔离,所以天生就解决了隔离性的问题,而且这种隔离性是非常彻底的。尽管在一个程序中可以创建另一个对象,但是它却不能直接调用,所有的对象之间的通信就自然变成了消息。这又天生符合面向对象编程的核心,即消息传递。
如果没有实现方法调用的切割,从理论上说就无法实现真正的隔离,也无法实现真正的消息传递。
Isolation implies that message passing is asynchronous. If process communication is synchronous then a sodware error in the receiver of a message could indefinitely block the sender of the message destroying the property of isolation.
在Smalltalk中,尽管语言开发者认为方法调用是消息传递,而不是传统编程意义上的方法调用,但本质上这种消息传递没能够实现真正的隔离,Smalltalk的消息传递更多是结合延迟绑定的动态特性使得响应者有一定的灵活性,例如对一个“方法调用”的消息产生完全不一样的响应,这得益于延迟绑定,例如可以通过运行时的一条情况执行不同的响应。但这种特性主要解决的是软件可扩展性的问题,而不是最重要的隔离问题。而可扩展性并不是Smalltalk唯一 的优势,很多动态语言都能够做到这样的。
当然对于健壮性,Smalltalk的思路是:1)首先保存快照;2)然后可以动态修改代码进行维护。
Erlang的消息传递模型带来了对象之间关系的非常不一样的编程体验,但它保证了面向对象编程模型的真正核心特性。这种不一样的特性是其他编程语言都不具备的,所以它可以说是唯一 真正的面向对象编程语言。
2.15.3.3 Erlang消息的限制
Each independent activity should be performed in a completely isolated process. Such processes should share no data, and only commu- nicate by message passing. This is to limit the consequences of a sodware error.
As soon as two processes share any common resource, for example, memory or a pointer to memory, or a mutex etc the possibility exists that a sodware error in one of the processes will corrupt the shared resource. Since eliminating all such sodware errors for large sodware systems is an unsolved problem I think that the only realistic way to build large reliable systems is by partitioning the system into independent parallel processes, and by providing mechanisms for monitoring and restarting these pro- cesses.
程序中的对象之间往往都包含着复杂的关系,对象数据的引用,方法调用,或者第三方共享数据,这些都是并发和隔离面对的问题。
在这方面Erlang并没有提供更好的方法,只是强行将对象完全隔离开,所以对象之间的所有通信就变成消息,这些消息可能是对另一个对象某个数据的读取,某个方法的调用等,这些都需要全部转化为消息;并且由于消息的异步性,程序的顺序被打乱,需要以一种非直接的方式进行操作。
虽然本质上所有的程序都可以这么去转化,但是它带来了很多复杂性,而Erlang并没有提供很好的机制去解决这种复杂的程序结构,这就使得Erlang基本上只适合于那种高并发但是线程相对独立的应用程序。
下一节将看到,RealityIS通过引入一种新的机制来解决这些问题。
2.15.4 CreateScript中的面向对象
组件只能修改自身属性,不能修改其他对象属性,只能给其他对象输入参数,由其他对象自行处理,这样的参数输入实际上就是消息
2.15.4.1 重新定义隔离
并不需要所有线程真正隔离,真正隔离带来很多编程上的不便。
原始隔离的定义是希望每个代码都不影响其他代码,但实际上这只是一个粒度的问题,比如严格的一点的是每个方法之间都隔离,每个方法之间彼此都不影响。
我们可以稍微放松一下这种隔离,你影响可以影响一定的范围,单只只要最终有一种机制能够识别这种影响,并将所有受影响的部分全部去除即可。
这就是RealityIS中的机制,它通过定义关键存档属性来解决这个问题,而不是向Smalltalk那样尝试将整个程序存档,使得程序可以从任意位置恢复。相反,RealityIS只能从一些关键节点进行恢复,应用程序或者组件需要对对象的数据字段进行恢复,这些字段根据上一个未受影响的关键存档属性进行推算。
这是一种介于Smalltalk和Erlang之间的隔离性概念,这使得我们可以保持程序的控制能力,使程序员可以像传统程序那样进行操作,同时又能保证隔离性。对象之间仍然以消息进行传递,但是这种消息更类似于方法调用,调用的方式更直接,而不是像Erlang一样每个调用都需要封装为消息。
隔离带来很多好处,包括:
- 隔离带来更好地并发处理,这是Erlang采用强隔离的一个主要原因
- 隔离带来健壮性,更好容错,一部分的error不会影响其他组件,这是Erlang采用强隔离的首要和核心原因
- 隔离带来更好的逻辑管理和组织
- 隔离带来安全性,尤其在多应用环境,这对RealityIS更重要,这部分在第2.16节专门讨论。
2.15.4.2 消息传递
介于Smalltalk和Erlang之间
Messages should not contain pointers to data structures contained within processes—they should only contain constants and/or Pids.
2.15.4.3 并发流程控制
In our system concurrency plays a central role, so much so that I have coined the term Concurrency Oriented Programming to distinguish this style of programming from other programming styles.
In Concurrency Oriented Programming the concurrent structure of the program should follow the concurrent structure of the application. It is particularly suited to programming applications which model or interact with the real world.
The word concurrency refers to sets of events which happen simulta- neously. The real world is concurrent, and consists of a large number of events many of which happen simultaneously. At an atomic level our bodies are made up of atoms, and molecules, in simultaneous motion. At a macroscopic level the universe is populated with galaxies of stars in simultaneous motion.
When we perform a simple action, like driving a car along a freeway, we are aware of the fact that there may be several hundreds of cars within our immediate environment, yet we are able to perform the complex task of driving a car, and avoiding all these potential hazards without even thinking about it.
In the real world sequential activities are a rarity. As we walk down the street we would be very surprised to find only one thing happening, we expect to encounter many simultaneous events.
If we did not have the ability to analyze and predict the outcome of many simultaneous events we would live in great danger, and tasks like driving a car would be impossible. The fact that we can do things which require processing massive amounts of parallel information suggests that we are equipped with perceptual mechanisms which allow us to intuitively understand concurrency without consciously thinking about it.
世界天然是并发的,我们的大脑的思考方式也天生适配这种真实世界的并发模型,用这种对真实世界的逻辑流程来开发程序是最好的,然而我们几乎从来没有这种编程模型。
相反,大部分编程语言或者编程模型都是顺序编程模型:
When it comes to computer programming things suddenly become inverted. Programming a sequential chain of activities is viewed the norm , and in some sense is thought of as being easy, whereas programming collections of concurrent activities is avoided as much as possible, and is generally perceived as being diecult.
I believe that this is due to the poor support which is provided for con- currency in virtually all conventional programming languages. The vast majority of programming languages are essentially sequential; any concur- rency in the language is provided by the underlying operating system, and not by the programming language.
In this thesis I present a view of the world where concurrency is pro- vided by the programming language, and not by the underlying operating system. Languages which have good support for concurrency I call Concur rency Oriented Languages, or COPLs for short.
响应式
2.15.4.4 对象及封装
2.15.4.5 类型及符号
2.15.4.6 多态
Concurrency Oriented Programming also provides the two major ad- vantages commonly associated with object-oriented programming. These are polymorphism and the use of defined protocols having the same mes- sage passing interface between instances of dicerent process types.
When we partition a problem into a number of concurrent processes we can arrange that all the processes respond to the same messages (ie they are polymorphic,) and that they all follow the same message passing interface.
在真实世界中,交互每个对象都可以响应不同的消息,真实世界天生是多态的,然而这会使得程序结构的控制变得困难,传统面向对象编程语言的多态性则相反,它希望尽可能少的多态性,因为更广泛的多态将使得程序结构变得复杂难以理解,并且动态的计算地址将会导致更大的性能问题。
2.15.4.7 对象关系
In order to write COPLs we will need mechanisms for finding out the names of the processes involved. Remember, if we know the name of a process, we can send a message to that process.
System security is intimately connected with the idea of knowing the name of a process. If we do not know the name of a process we cannot interact with it in any way, thus the system is secure. Once the names of processes become widely know the system becomes less secure. We call the process of revealing names to other processes in a controlled manner the name distribution problem— the key to security lies in the name distribu- tion problem. When we reveal a Pid to another process we will say that we have published the name of the process. If a name is never published there are no security problems.
Thus knowing the name of a process is the key element of security. Since names are unforgeable the system is secure only if we can limit the knowledge of the names of the processes to trusted processes.
为了保证线程之间的安全,Erlang使用Name来表征权限,你拥有某个线程的name,你就有权限与之进行消息通信。就像现实世界,你几乎总是与你认识的人进行交互,我们几乎不会跟陌生人进行交互。
然而,现实世界中,或者一个更开放的程序世界,除了这种基于name的交互关系,还有大量的逻不是基于name的,例如一个广播的消息肯定不会去按一个一个的name进行传递,而且按照name的设计初衷,它也不会轻易让一个进程掌握所进程的name,否则name的设计就会失去意义。
所以我们还需要一些其他权限,大概可以分为三种:
- 系统权限,可以向所有人发送消息
- 好友权限,基于组件类型进行检索,但是附带好友权限筛选
- 应用内权限,理论上一个应用内部的组件在应用内部拥有所有权限,就像一个应用应用,除非用户禁止某个数据的方法
所以我们每个object需要携带很多信息,例如appid,usderid等待。
2.15.4.8 容错机制
2.16 隔离与安全机制
The inability to isolate sodware components from each other is the main reason why many popular programming languages cannot be used for making robust system sodware.
It is essential for security to be able to isolate mistrusting pro- grams from one another, and to protect the host platform from such programs. Isolation is diecult in object-oriented systems because objects can easily become aliased.4—Bryce [21]
Bryce goes on to say that object aliasing is diecult if not impossible to detect in practice, and recommends the use of protection domains (akin to OS processes) to solve this problem.
In a paper on Java Czajkowski, and Dayn`es, from Sun Microsystems, write:
The only safe way to execute multiple applications, written in the Java programming language, on the same computer is to use a separate JVM for each of them, and to execute each JVM in a separate OS process. This introduces various ineeciencies in resource utilization, which downgrades perfor- mance, scalability, and application startup time. The benefits the language can ocer are thus reduced mainly to portability and improved programmer productivity. Granted these are important, but the full potential of language-provided safety is not realized. Instead there exists a curious distinction between “language safety,” and “real safety”. — [28]
In this paper they introduce the MVM (an extension to the JVM) where their goal is:
... to turn the JVM into an execution environment akin to an OS. In particular, the abstraction of a process, ocered by modern OSes, is the role model in terms of features; isolation from other computations, resources accountability and control, and ease of termination and resource reclamation.
To achieve this they conclude that:
... tasks cannot directly share objects, and that the only way for tasks to communicate is to use standard, copying commu- nication mechanisms, ...
These conclusions are not new. Very similar conclusions were arrived at some two decades earlier by Jim Gray who described the architecture of the Tandem Computer in his highly readable paper Why do computers stop and what can be done about it. He says:
As with hardware, the key to sodware fault-tolerance is to hier- archically decompose large systems into modules, each mod- ule being a unit of service and a unit of failure. A failure of a module does not propagate beyond the module.
...
The process achieves fault containment by sharing no state with other processes; its only contact with other processes is via messages carried by a kernel message system. — [38]
Language which support this style of programming (parallel processes, no shared data, pure message passing) are what Andrews and Schneider [4] refer to as a “Message oriented languages.” The language with the delightful name PLITS5 (1978) [35] is probably the first example of such a programming language:
The fundamental design decision in the implementation of RIG6 was to allow a strict message discipline with no shared data structures. All communication between user and server messages is through messages which are routed by the Aleph kernel. This message discipline has proved to be very flexible and reliable. — [35]
RealityIS通过在组件之间以复制的方式传递基本类型的数据,并且不包含任何指针和引用来保证组件之间的安全性。
Messages should not contain pointers to data structures contained within processes—they should only contain constants and/or Pids.
2.16.1 链接的安全性
2.16.1.1 java class loader & security
Today's computer users cannot realistically trust that the programs they run are bug or virus free. It is cruicial then that the host be able to run a non-trusted program in isolation from its services. This means that client programs not be able to communicate with services, or that they can only do so under the control of a security policy that decides whether each method call from a program to the servers is permitted.
In comparison, the ability to isolate programs in this fashion is awkward in Java using loader spaces. In Java, each program is allocated its own class loader, which is responsible for loading versions of the classes for the program. An object instantiated from a class loaded by one loader is considered as possesing a distinct type to objects of the same class loaded by another loader. This means that the assignment of an object reference in one domain to a variable in another domain consititues a type error. This model is inconvenient for client-sever comunication, since parameter objects must be serialized (transferred by value).
Java的class loader不安全,所有具有外部符号的虚拟机加载方式,在multitasking 情况下都是这样?
在OOP中,类似之间包含继承关系,不同的类型之间也可能包含引用关系,这使得object往往不是独立的对象,由于对象的类型信息包含在类似Class这样的对象中,而这样的对象被所有该类型的对象引用,所以就导致对象不能具有独立、完全隔离的domain space,因为那样将失去类型信息,除非对类型信息进行复制,但这会占据大量的存储空间。
而在同一个domain space,如果对象之间完全不存在相互引用,那样语言是可以保证安全的,但是一旦对象之间存在引用,获得引用的对象就可以调用所有该对象的公共方法。虽然我们可以通过设置公共属性来控制访问权限,但这往往只是针对类型本身的特性,而不能控制应用程序逻辑不小心将对象引用传递给非法的对象。例如在复杂的程序逻辑中,为了方便,有时候只是为了获取数据,而简便地把一个整个对象引用传递过去,这就带来了风险,因为获得这个引用的程序不但可以获取变量的值,它还可以非法方法所有的公共方法。当整个程序都属于一个开发商时,这没问题,但是在multitasking的环境下,就存在安全问题。不同Domain的object可以通过全局变量等方式获取到一些不属于 自己Domain的对象,例如通过一个公共的事件管理器,任何task可能都可以获得整个事件队列。
保证所有的object之间的通过都通过传递值,或者复制对象的方式能够保证安全,但是这样又会给编程带来不便。
2.16.1.2 Java applets
Java有一些高级的security model,其中包括protection domian,其设计目标是对applets进行隔离。class loader只是java的基本隔离机制。Java中的每个applet拥有自己独立的class loader,每个独立的class loader会在自己的protection domain加载独立和私有版本的class。Java会保证同一个class在不同的protection domain中有不同的的类型(distinct type),因此类型是隔离机制的基础,因为将一个loader space的对象引用赋值给另一个loader space中相同名称的class会导致类型错误。这是一种动态类型(dynamic typing)检查系统,因为这些新的类型机制由运行时提供而不是编译时可以检查。
这个机制的问题是,所有系统级别的类型(例如java.lang等等)是共享的,因此还是会导致aliasing。例如对于一个继承自PasswordID的Password类,两个class loader分别创建自己space加载Password类,但是没有加载PasswordID类,这个时候使用到的PasswordID类会由system loader进行加载,此时如果两个space的引用通过PasswordID类型进行赋值传递,则就会造成aliasing。
2.16.1.3 MVM
Improved scalability results from an aggressive application of the main design principle of MVM: share as much of the runtime as possible among applications and replicate everything else.
Java class loader只能做到类型安全,所以应用需要保证Java文件的来源是可靠的。
The existing application isolation mechanisms, such as class loaders [16], do not guarantee that two arbitrary applications executing in the same instance of the JVM will not interfere with one another. Such interference can occur in many places. For instance, mutable parts of classes can leak object references and can allow one application to prevent the others from invoking certain methods. The internalized strings introduce shared, easy to capture monitors. Sharing event and finalization queues and their associated handling threads can block or hinder the execution of some application. Monopolizing of computational resources, such as heap memory, by one application can starve the others.
因此唯一的安全方式是保证每个app只运行于一个独立的JVM环境,但这会导致资源的利用率低,性能、可伸缩性和启动时间的问题。
Their existence perpetuates the current situation, where the only safe way to execute multiple applications, written in the Java programming language, on the same computer is to use a separate JVM for each of them, and execute each JVM in a separate OS process.
针对多应用的情况,有两种级别的安全:
- language safety
- real safety
前者普遍缺乏,已有的方案都或多或少限制语言或者导致性能问题,后者则大多数依赖于hardware-assisted, OS-style的方法。
Three goals dictate our design choices: (i) no form of interference among executing applications should be allowed, (ii) an illusion of having the JVM (with all core APIs and standard mechanisms) to itself should be provided for each task, and (iii) MVM should perform and scale well. The motivation is to make the system attractive from the practical point of view.
The key design principle of MVM is: examine each component of the JVM and determine whether sharing it among tasks can lead to any interference among them. In some cases this approach yields a clear verdict that the given component can be shared without jeopardizing the safety of the tasks. Other components are either replicated on a per-task basis or made task re-entrant, that is, usable by many tasks without causing any inter-task interference. This builds on the ideas described in [6]. The technique presented in that work – replicating static fields and class monitors – has been generalized in MVM to classify all components of the JVM as ‘shareable’ or ‘non-shareable’.
A simple way of explaining the model is to first think of a straightforward approach to multitasking in the JavaTM application environment: all applications share all classes. The essential observation at this point is that a safe language already has some built-in support for isolating applications: data references cannot be forged, unsafe casting is not allowed, and jumping to an arbitrary code location is impossible. Consequently, the only data exchange mechanism (barring explicit inter-application communication) is through static fields. This can only occur either by explicit manipulation of static fields or by invoking methods which access these fields. It can lead to unexpected and incorrect behavior depending on how applications use the same class with static fields.
The above observation suggests an approach for achieving isolation among applications: to maintain a separate copy of the static fields for each class, one copy per application that uses the given class. However, only one copy of the code of any class should exist in the system, regardless of how many applications use it, since methods cannot transfer data from one application to another once the static fields communication channel is removed. (Dealing with covert communication channels is beyond the scope of this paper). Our proposal effectively gives each application the illusion that it has exclusive access to static fields while in reality each application has a separate copy of these fields.
2.16.2 Program Security Mechanisms
有许多工作用于对程序集成access control,例如:
- 在方法调用之间添加一个security policy checker,例如Java的系统类包含一个对SecurityManager对象的调用用于检查线程之间的权限
- 另一些安全策略则由编程语言本身支持,编程语言带有 一定的访问权限的notion,程序可以控制一些对象对另一些对象的访问权限
- 如今更多的语言设计者则更多倾向于将安全与类型等价,这可以使用一些静态或者动态检查技术
2.16.2.1 CFI
Current software attacks often build on exploits that subvert ma- chine-code execution. The enforcement of a basic safety property, Control-Flow Integrity (CFI), can prevent such attacks from arbi- trarily controlling program behavior. CFI enforcement is simple, and its guarantees can be established formally, even with respect to powerful adversaries. Moreover, CFI enforcement is practical: it is compatible with existing software and can be done efficiently using software rewriting in commodity systems. Finally, CFI pro- vides a useful foundation for enforcing further security policies, as we demonstrate with efficient software implementations of a pro- tected shadow call stack and of access control for memory regions.
2.16.2.2 SFI
内存安全是最大易受严重攻击的来源,大约70%,一些怀有恶意的攻击者例如一些内存安全的bug来攻击软件,Software sandboxing或者software-based fault isolation (SFI) 是用于构建包含未信任组件的安全系统的一种轻量级方法,能够用于减少由于这些内存安全bug导致的攻击,SFI通过严格将第三方未信任软件限制在自己的沙盒内存区域,来隔离这种bug导致的破坏。用例包括:
- 浏览器使用SFI来扩展第三方组件,例如经典的Native Client SFI syetem(NaCI)使用SFI来扩展第三方c库,使得浏览器可以使用如第三方的字体,音频,XML解析等库
- 在边缘计算节点与第三方未信任客户环境进行联合计算
- 其他的一些例子,如OS kernels,databases, browsers , language runtime, and serverless clouds.
SFI强制将未信任的代码隔离到自己的沙盒环境,并保证每次内存访问都被动态检查。例如NaCI和Wasm都有措施保证未信任的组件的内存 访问都处于自己的沙盒区域,并且添加运行时的动态检查以保证所有的control flow都被限定在自己的沙盒路基内部。
安全和性能问题:
- 较大的运行时检查的性能问题,因为这些运行时代码还得保证这种检查本身是安全和正确的,所以通常机制就比较复杂,因为任何一个漏掉的检查都可能导致攻击。
- 除了运行时检查的安全性和正确性,上下文切换的正确性和计算量也是影响安全和性能的重要来源
在一些沙盒应用架构比较重的应用中,上下文切换可能占据了较大的性能开销,例如Firefox可能因为沙盒字体渲染影响了较大的性能而不得不弃掉沙盒字体渲染。
2.16.2.2.1 上下文切换的重要性
考虑如下代码,在浏览器中执行一个第三方未信任的字体渲染库:
void onPageLoad(int* text) {
...
int* screen = ...; // stored in r12
int* temp_buf = ...;
gr_get_pixel_buffer(text, temp_buf);
memcpy(screen, temp_buf, 100);
...
}
这段代码调用libgraphite库的gr_get_pixel_buffer方法将文本渲染到一个临时的buffer中,然后将这个临时buffer的内容拷贝到屏幕变量中用于渲染。使用SFI将库的内存隔离起来,即内存隔离机制使得gr_get_pixel_buffer不能够获取任何onPageLoad或其他部分的浏览器堆和栈内存。然而不信的事,单纯的内存隔离是不够的,如果整个切换仅仅是一个方法调用,则攻击者可能违背方法调用的约定以打破隔离,几种libgraphite可以使用的机制:
- Clobbering Callee-Save Registers:假设上述的screen变量编译到寄存器r12中,在System V调用约定(calling convention)中,r12是一个callee-saved register,所以如果gr_get_pixel_buffer劫持r12,它可以在调用返回之前获取该寄存器指向的实际内存的值,还可以将该寄存器设置为一个该沙盒中的内存地址,这样在后面的memcpy指令中进行复制,这就可以给攻击者一种方法使它可以劫持浏览器的control flow。为了阻止这种形式的攻击,我们需要保证callee-save register integrity,即保证沙盒代码在返回之前将 callee-save register重置为原来的值。
- Leaking Scratch Registers:同样的,其他scratch registers也可能会泄露敏感信息给沙盒,例如浏览器保存了一个密钥在scratch register中,仅仅是内存隔离并不能保证受攻击者控制的libgraphite不会读取和使用这些寄存器,为了阻止这种泄露,我们需要保证scratch register confidentiality
- Reading and corrupting stack frames:最后,如果宿主和沙盒应用程序共享一个栈,攻击者就可能读取或者 破坏栈中的数据或者指针,为了阻止这种攻击,需要stack frame encapsulation,即保证沙盒代码不能访问调用栈。
2.16.2.2.2 Heavyweight Transitions
传统的SFI都使用比较重的上下文切换技术,例如NaCI以及Wasm编译器Lucet,这种技术将所有的调用和返回值都封装起来以应对前面提到的这些问题,这样的切换都是安全的,他们提供:
- Callee-save register integrity:在调用的时候,使用一段称为Springboard的代码来包装calls,即将寄存器保存在受保护的应用内存内存中的一个独立的栈中;当由库返回到应用程序时,使用一段称为trampoline的代码包装returns,并重置寄存器。
- Scratch register confidentiality:由于任何Scratch register 都可能包含敏感信息,所以Springboard在切换到沙盒之前会清除所有的Scratch register。
- Stack frame encapsulaton:大部分的SFI会对宿主程序和沙盒代码设置独立的调用栈,以保证沙盒代码无法访问受信任的调用栈。该机制同样由Springboard和trampoline来实现:首先,追踪所有栈指针,然后Springboard会将这些栈上的参数全部复制到沙盒代码的调用栈中,最后trampoline会追踪实际的返回地址,并将其保存在受保护的内存中,这样沙盒代码库将无法破坏它。
由上面的过程可以看到,这种机制可以保存切换的安全,但是具有两个比较严重的缺点:
- 首先,它们给SFI带来较大的负担,相比于单纯的方法调用计算量要大得多,这种保守地切换会带来大量的不必要的状态保存和清除,几乎相当于重新实现OS进程的很多基础功能。
- 其次,Springboard和trampoline必须针对不同的平台定制,因为每个平台有不同的calling convention,任何实现错误就可能导致沙盒能够逃离这种攻击。
2.16.2.3 object space model
2.16.2.4 lua Environment
2.16.2.5 Erlang 隔离机制
2.16.3 Webassembly Security
2.16.3.1 Module & CFI
2.16.3.2 Memory safety
2.16.3.3 Isolation without Taxation
传统的Heavyweight Transitions是保守的,因为它们对沙盒代码的运行的结构做了比较少的假设。但NaCI和Wasm通过Springboard和trampoline的机制确实也给沙盒代码库强制增加了一定的结构。
这篇论文指出通过进一步对沙盒代码增加适当的结构,可以避免掉几乎所有前面提到的由Heavyweight Transitions带来的额外工作,使得整个上下文切换更简单、计算更快,同时易于移植。它更像一个更高层次抽象、可组合的编程语言。首先提出能够 实现zero-cost切换的条件。
2.16.3.3.1 Zero-cost conditions
假设沙盒库代码是有一些函数及其期望的参数组成,这篇论文提出了一些条件,满足这些条件(即包含这种结构)的第三方Wasm代码可以被形式化的验证,从而保证第三方组件的安全。这些条件包括:
- Calee-save register restoration:
- Well-bracketed control-flow:
- Type-directed forward-edge CFI:
- Local state encapsulation:
- Confidentiality:
这种方法的价值在于它能够以一种形式化的结构来描述能够保证内存安全的第三方组件代码,使得只要第三方组件遵循这样的结构去构造组件,则其生成的Wasm代码可以是被形式化验证的。这些添加的额外结构不仅能够用于形式化验证,还能够保证内存安全。
当然,为了避免额外的上下文切换的计算量,这些条件所约束的实际上是希望能够使第三方组件遵循正常的隔离原则,即不要去访问超出自己范围的内存和代码,不要去通过寄存器和返回地址等去破坏宿主程序的control flow。
即如果我们能够以某种方式保证第三方组件是安全的,那么我们就可以不必为了隔离去做一些额外的保存或者清除工作。当然这种方式需要管理员保证不引入没有经过验证的第三方组件。
2.16.4 全新的多任务隔离机制
多应用环境下应用程序的隔离大概可以分为两类:
- 纯脚本语言,这种语言不允许第三方组件包含任何形式的能够包含二进制形式的代码,所以组件能够调用的全部二进制代码均来自于宿主程序,这个时候只需要简单的保证第三方组件:1)不能访问全局共享变量,2)不能共享调用栈,基本上就可以解决多应用安全性问题。这种语言的代表是Erlang,开发者编写的所有代码都是Erlang脚本,被Erlang解释执行。
- 非脚本语言,非脚本语言即能够以某种方式使第三方组件包含二进制代码的语言,包括浏览器中的NaCI这种直接调用二进制代码库的系统,也包括像Wasm这种虽然以中间IR形式存储,但是这些中间IR是包含操作寄存器的指令的,所以在被动态编译之后是可以破坏宿主程序内存的,第三种是像Python这种,第三方Python库本身是可以调用C库代码的组件。
总而言之,除了编程语言本身的内存隔离机制,还要避免第三方组件访问寄存器,只要第三方组件能够以某种形式包含寄存器,则可以绕开内存隔离。CreateScript本身属于纯脚本型语言,但是集成到第三方app中则会引入第三方包含操作寄存器的代码。所以后期在处理这部分的时候还是需要考虑传统的SFI技术。
2.16.4.1 对象隔离
没有全局变量,全部都是实例
环境变量都是只读的,如果有app相关的,创建特定app的环境object
每个对象由多个组件组成,对象由用户创建,
- 对象内部的通信,在隔离范围之内,所以采用基本的类型安全就行
- 对象之间的通信,加安全策略,因为对象之间的通信可能是跨应用的(尽管大部分可能是app内部的),这是实现互操作性的基础
所以总体是基于对象的安全控制,背后的控制策略是对象所属的appId和userId之间的权限关系,当然这个关系只需要验证一次,这些关系可以以加密的方式预存储,在服务端统一计算。
计算顺序:
- 首先计算对象的内部组件
- 最后计算需要跨对象通信的组件
其背后的逻辑是,对象内部首先发生内部变化,然后这种变化影响到外部。这样能避免一些传统编程语言中任意顺序的相互调用导致的混乱组织结构和逻辑
2.16.4.2 app spaces
an approach to safe object sharing
The crux of the problem is that once a reference is obtained, it can be used to name an object and to invoke methods of that object. We believe that naming and invocation must be sepatated, thus introducing access control into the language.
access control
每个对象都属于一个app space,这个app space用于控制权限,app space以用户为基础,每个实例用户拥有独立的app space
app space影响并行性
放到一起并行计算的对象必须是同一个app space,尽管多个不同space的对象可能拥有相同的组件,它们会被独立计算,以及独立存储。
为了方便并行计算,不是将一个对象的所有属性存储到一起,而是会按照组件类型分开存储;但是对于每个相同类型对应的属性 ,它们应该看起来就像一个对象,它们形成一个group,每个group既属于一个对象,也属于一个space。就像 把一个对象分成多段,每个段跟作为一个对象整体拥有相同的行为
2.16.4.3 对象通信
对象通信只能发生在2个对象之间,即,如果外部参数包含多个参数,必须是来自一个包含所有这些属性的对象,不能是来自多个对象的组合所以开发者应该避免使用无关的多个参数输入,最佳方法是使用全局符号,因为那是代表着交互的逻辑变量。如果使用2个以上符号,这些符号应该从逻辑上应该在一起,或者开发者保证他们应该在一起
2.16.4.4 避免上下文切换
传统的沙盒机制都是采用类似CPU时间片的方式,因为:
- 整个执行是无序的,所以你无法按某种顺序执行整个软件,只能在不同的线程之间进行切换;虽然Erlang在线程之间分配优先级,但是仍然是需要切换,因为线程数量可能很多,并且系统不知道每个线程需要多长时间才能执行完全部计算,即使它可能还差几个指令就执行完了,也可能会发生切换
- 单一一个计算可能比较大,所以无法直接将一个方法计算完再进行下一个计算,你必须要保存状态
由于上述的原因,所以必须要在线程之间不停地切换上下文,这就导致较大的开销,需要花很多时间处理内存数据的换进换出。因为线程内部可能保存着复杂的状态。
在RealityIS中,由于整个执行的有序的,即所有组件都需要在一帧之内被执行,所以这就可以避免掉上下文切换,因为不必为了考虑两一个 线程被拖延时间而暂时停止当前线程的计算并切换到其他线程。这避免额大量的上下文切换导致的内存换进换出等额外的计算。
当然代价是开发者需要保证所有计算在每一帧都可以被计算完,比如就不能出现那种单一组件需要数帧才能计算完毕的计算,这种计算通常需要异步处理,不影响当前循环。但游戏本身就是这样的机制的。
2.17 互操作架构
2.17.1 LLVM
2.17.2 USD
2.17.3 MLIR
2.17.4 Lua C API
直接获取内存地址,而不是从字符串解析。
2.17.5 基于符号表的互操作架构
互操作必然基于某种标准,某种预定的格式。
传统的互操作架构基本上是:1)首先设计好某种标准格式,其中的格式几包括数据属性的定义、属性组织的数据结构、也可能包含处理这些数据的约定接口,当然接口约定并没有那么大的意义,处理数据的程序理论上可以按照任何方式对数据进行处理;2)发生数据一方按照数据格式生成数据;3)借助平台提供的某种机制发生数据给接收方,其中传输的通常是序列化之后的字符串或者对应的二进制数据;4)接收方接受到数据首先进行反序列化,然后按照格式标准进行数据处理。
上述的流程存在三个问题:
- 性能问题,存在序列化和反序列化
- 接口问题,双方只需要遵循格式标准,但是发送和解析的程序及其接口都是完全由双方自己决定的,当有大量的数据需要进行互操作时,这种大量的协作就会带来巨大的成本。由于双方理论上说甚至可能采用不同的编程语言,所以在关于怎么处理数据(包括发送和接收)上没有机制能够达成共识。
- 更新问题,当标准需要更新时,完全没有有效的机制可以保证双方可以及时更新,导致程序不可用或者很难更新到最新功能。尽管在现实世界中这没有问题,但是在数字世界,我们理应有方法可能更好地管理这种更新。
按权重看,接口的问题是最大的,其本质的问题在于仅仅有数据格式,没有建立起更上一层关于数据格式的处理标准。这里面包含两个问题:
- 处理数据的属性名称的问题,这表现在,尽管双方都知道格式中关于数据属性的定义,但是实际上每个程序在内部真正处理的算法中,它使用的名字和数据结构并不一定是标准格式中定义的名字和数据结构,这就导致双方必然要做一些名称和数据结构转化之类的工作。这些工作不光是繁琐的,而且因为每个程序定义不一样 ,这种人工的一些工作导致很难进行自动化,比如涉及第三个标准更新的问题。
- 对数据进行读写操作的问题,跟上面的问题有关,没有比较标准的对数据进行直接读写的方法
上面第一个问题可以使用符号表进行解决,符号表因为定义的就是变量的定义,所以如果标准定义的不仅仅是格式本身,而是涉及编程语言运行时符号的解析,这天生就将处理双方的数据名称和格式进行统一。
针对第二个问题,它的思想来源于USD和MLIR,即标准系统不仅要解决中间交换格式的问题,还需要提供关于对交换数据进行解析的功能,这避免了双方各自写一些独立的重复代码,又使得对数据的读写修改变得简单。
从这个意义上说:
- CreateScript中定义的符号(及属性及其数据结构)就相当于USD或者MLIR中定义的格式标准
- 而Create的整个运行时保证两个组件之间能够获取到数据进行处理的机制,就像USD/MLIR中提供的对自定义数据格式的解析,只不过USD或者MLIR中是按模板生成的对应的解析代码,而CreateScript是一种运行时的语言机制,这种语言机制保证可以直接从内存中进行数据读取,而不是从一个数据文件中进行解析
2.18 从单应用到多应用架构
尽管从语言机制或者语法特性上看,CreateScript设计了很多不一样的思路,但对于它们中的大多数,都不单纯只是一种不一样的语法形式,其根本原因是由底层整个编译、解释和链接的系统发生了很大的变化,或者说跟这些变化的底层过程高度相关的。
我们可以将所有的原因和因素分为三大类:
- 最底层的因素,这涉及编译、解释和链接的过程
- 中间层的因素,比如互操作的机制,符号表的管理
- 上层更偏向于语言的语法形式
本节我们讨论一些最底层的机制和问题,然后可以从中推导出我们为什么必须要这么设计,也能够更好地理解整个CreateScript系统。
从根本上说,RealityIS为什么必须重新开发一整套底层的软件构造方法,是因为当今所有软件构造方法的每一个部分,都是在围绕单个应用程序的架构而设计的,这从根本上就使得多应用的建构很难被构建,这导致一些问题比如:
- 基于现有的软件构造方法构建多应用环境很难保证安全性
- 很难实现互操作性
- 一个应用的运行时很难被外部开发者进行扩展,当然这里指的是扩展一个应用,而不是一个软件。所谓应用是指经过扩展或者修改之后,所有的用户都可以即使获得经过扩展或者修改之后的版本,而软件是指只能被某个用户自己使用的软件拷贝,例如某个开发者可以基于Unreal Engine开发或者购买一些扩展插件,来形成一个自己独特的版本,这个版本的软件虽然是经过扩展或者修改的,但是这个扩展或者修改之后的软件只能被该开发者一个人使用
一下我们详细描述这些问题,这些机制通常都是与具体编程语言无关的,而是设计更底层的一些机制或者约定,例如方法调用约定(Calling convention)。
2.18.1 方法调用机制
方法调用是编译过程要处理的一个重要的部分,同一个方法的代码通常编译到相邻的指令序列中,在内存中处于连续的位置,因此CPU总是能够按顺序正确执行一个方法。即使对于跳转语句,跳转到任意一个位置,则意味着后续的执行都将从新的位置重新按顺序执行,所以只需要设置一个特殊的跳转指令用于将当前指令的位置改为指向新的地址即可。
然而方法调用的流程则不是一个简单的跳转流程,当一个函数A中的某个语句调用函数B时,系统需要将指令执行跳转到函数B的开始位置,同时等函数B执行完毕时,系统还需要能够正确返回到函数A中后续的指令位置。为了能够正确处理上述的流程,在传统的编译流程中,对于方法的调用,大多数是使用一种相互协作的机制,即会在函数A和函数B中分别新增加一段代码:
- 在函数A中的调用代码处设置一个跳转指令,使之可以跳转至函数B的位置,同时将下一条语句的地址传递给函数B,使函数B执行完毕之后系统可以返回到正确的位置
- 函数B中则会增加一段代码,该代码首先会保存返回地址,并在函数执行完毕之后执行一个跳转指令使之跳转回函数A中的下一条语句
当然由于返回地址是变化的,所以函数B并不会保存在指令中,而是将返回地址存储在栈中,这个栈的地址可以同时被A和B访问。在这个过程中,函数B可能不遵循相关的约定,例如它可以修改这个返回函数地址,使之指向不合法的位置,这就会导致程序的控制流被破坏,可能引起程序崩溃。在一些缓存溢出的攻击中,破坏者还利用缓存溢出注入的函数代码,使程序流指向这些代码从而可以执行一些非法代码。
2.18.2 链接机制
2.18.3 内存隔离机制
2.19 并行编程语言
3. Reality Create
设计原则
第一目标是全部程序动态化,任何整个Creation 都可以动态下载,所以不用编写C++代码,也就意味着底层必须高度优化,脚本的转换部份也要高度优化,可以去除一些不必要的面向对象属性
3.1 Creation ID
3.2 Creation Simulation
3.3 UI组件
将UI元素集于Creation Script构建成组件,然后整个编辑器可以集于Creation Script来创建,即整个编辑器当作一个Creation。
UI组件的做法其实可以按照3D Renerer的做法类似,唯一的区别就是Camera不一致,3D的渲染部分肯定也是需要继承到原生C++代码中,UI渲染完全也是类似的思路。
在传统的编辑器中,编辑相关的功能只是存在于编辑器中,不会包含在运行时,这块仍然需要处理,但是至少整个编辑器的构建可以使用统一的架构。
另外有一部分功能是编辑器特有的,包括代码的提示,调试等等功能,这部分在Runtime部分还是需要从虚拟机中拿掉。
3.3.1 Bevy UI
A custom ECS-driven UI framework built specifically for Bevy
- Built directly on top of Bevy's ECS, Renderer, and Scene plugins
- Compose UIs dynamically in code or declaratively using the Bevy Scene format
- Use a familiar "flex box" model to layout your UIs
3.3.2 统一编辑态和运行态
4. Reality World 
核心产品,就是以现实世界的地面平面特征为底板
创作元素、模板、行为组件分类中以建筑类、城市装扮类为核心或者优先,以小世界合成大城市的方式,重新定义我们的世界
- 除了建筑之外,还有许多城市元素,例如广告,交通
- 城市主题结构将不仅仅是建筑,可能非常多奇观创造,非常多元
- 游览城市将是一种很独特的体验
- 要有机制在城市中构造文化
同时整个基础仍然是可以局部独立物体可分享的方式
第一期产品整体会有三种体验
- 大的现实世界
- 独立分享
- 以Code的形式创造平行世界
所有的建筑内容不会是静态的,它会为创作者带来收益,成长或者升级,类似模拟经营的体验,但是这里主要是靠创造的艺术性、文化性等,通过创造的独立性吸引流量,从而形成区域等级中心区等等,较热门的区域会带来更高的收益,形成城市文化(创作本身蕴含着文化),这可能也会形成区域协作,共同定义一些文化,可以类似Everdale机制协作共建
可以有不同的做法,融入建造和模拟经营,全面建设城市:
- 一种可以通过限制资源类型,鼓励交易,鼓励合作,便游戏一点
- 一种只融入少量游戏元素,以创造为极限,不限制资源
前者早期发展更快,后者早期参与较弱,可以两者结合
http://creation.id/=qwe&app=appid&cam=6dof
坐标的概念使得大家可以在RealityWorld 之外大量宣传一个地点,就在现实世界一样,甚至大家回去找这样的攻略和列表,而不是通过里面的游览
默认打开当前位置,所以去哪里都可以看看
4.1 Reality ID
用户中心
4.1.1 (用户)组件管理
组件版本升级,等等,保证组件是最新的。
这里编译之后列出所有问题,用户也可以直接发送信息给开发者,要求更新组件以支持某些新的标准。
这里是用户对象编译发生的地方,因为这里设置的东西基本上不会再修改,当然也应该支持在运行时动态编译,这种是少数情况
4.1.2 (用户实体)权限管理
4.2 The Reality World app
4.2.1 真实世界作为底图

尽管对于元宇宙来讲,我们可以构造一个任意的虚拟世界,但是一个纯虚拟世界至少有以下缺陷:
- 它将根现实世界完全脱节,这种割裂感会非常大,因为虚拟世界里面的内容很难跟现实世界有一个联系,要想让未来的3D成为人们日常生活的一部分,这个虚拟世界一定是和现实世界有关联的,否则它就摆脱不了类似游戏的概念,人们把它当做一个专门的娱乐方式,偶尔进去体验一下,而不是时时跟它保持联系和连接。
- 无法促进地理上靠近的人之间进行互动,在一个纯虚拟世界中,真实的地理位置在其中无法产生较好的关联,因此它们的互动通常只是现实世界的好友之间的互动,或者说通过某些游戏内容的机制促进的具有类似爱好和兴趣的陌生人之间的互动。但是城市作为一个重要的文化载体和符号,它本身也是具有丰富的信息在里面的,而且人与城市之间的关系是现代文明中人类不可忽视的重要体验,所以怎样利用好这种真实世界的地理关系,也是未来元宇宙成为人们日常生成一部分的重要部分之一。
- 元宇宙作为现实世界的延展,其实前面两部分都说明了,真实世界与虚拟世界的关联和关系,会成为未来元宇宙重要的核心机制,否则它不仅会对我们的生活造成割裂,并且它无法成为人们日常生活的一部分,就像今天的泛娱乐类应用如抖音、微信等。并且作为未来科技生活重要的一面,我们希望它要能够用来提升人们的生活品质,这包括两个层面:使人们感到更加快乐,以及帮助人们提供更加丰富的数字化服务。
所以Reality World将以现实世界真实地图为底板进行打造,以围绕现实世界与虚拟世界的紧密联系为核心设计原则,开发能够通过元宇宙的丰富数字化机制来提升人们生活品质的开放虚拟世界。
4.2.1.1 跟现实世界关联
Reality World世界的底座是真实世界的平面地图,并且保留城市主要的道路信息等。这样做有几个好处:
首先虚拟世界跟真实世界是有关联的,这种关联不仅是指地理上的位置关联,而是我们有机会去表达跟一个城市相关的信息,例如当前城市的某些指数,城市的一些文化风貌,可以抽象成某种游戏机制,这样同一个城市中的市民都可以感受到类似的与该座城市独有的体验。这些体验往往都是关于现实的信息,它包含人与城市和周围环境和人之间的关系,所以这种机制形成了对现实的增强。
最重要的是关系,地理位置是一种重要的关系,它不仅仅是位置的关系,它是一种把大家拉在一起,这里的人都有共同的一些认知的关系。所以地理位置实际上隐藏着很多信息,是非常重要的概念。
当然,与真实世界不一样,真实世界的外观和细节在虚拟世界中不是最重要的,人们希望一个不一样的世界,人们希望能够改变现实世界,通过这种机制,人们有可能创造出一个不一样的虚拟世界,这个世界代表着人们期望、向往和想象中的一个世界。也代表着人们对现实世界以及人与人之间关系的思考。
不过,与虚拟世界中的建筑物等外观不一样类似,尽管地面的道路位置是保留的,但是道路的名称是可以更改的。这是世界的道路结构及其视觉位置能够帮助人们在虚拟世界更好地导航,所以即便这些道路的名字被修改了,人们仍然能够很好地关联它们。但是如果这是一个纯虚拟而巨大的虚拟世界,人们则很难记住那么多的地址名称。
这样的元宇宙世界将能够提升人们现实生活的生活品质。
4.2.1.2 真实地理的意义
地理不仅仅是地图上的位置,它蕴藏着很多意义,几乎可以说跟我们大部分的日常生活,以及日常生活之外更重要的人与社会的关系层面,这些信息更加重要,它关乎人的情感、情绪、对生活的体验和品质等。
真实世界是关于大家通过一定相邻的地理位置彼此聚在一起,然后因此而共同关心和关注某些相同的事情,进而形成某些相关联的关系、信用、世界观、文化等等。
尽管有时候我们跟周围的人并不直接认识,但是我们跟他们之间仍然潜藏这某些联系,这些联系并不一定是显式可见的,但是它们却是客观存在的。然而对于远在一个我们并不知道的地方,所有这些联系都不存在,或者说很弱。比如说对于所有中国人,我们之间仍然存在一些联系和关系,但是对于大部分人,这种关系很弱。
因此,从某种程度上说,地理信息甚至是比亲情更重要的意义,亲情之间的联系反而是比较简单的,我们大部分的情感和精力也许会更多花在这种基于地理位置信息上。当然我们把同事等关系也归结到地理信息相关,例如我们跟另一个城市的同事往往没有本地同事之间关系那么紧密。同样的,本地同学之间通常也要比其他城市的同学之间关系紧密,因为他们之间更有可能会有更多的联系。
元宇宙怎样表达这些意义呢?
地理信息,或者说人与社会的关系,是一种抽象的信息,参见第4.10.1节的内容,我们很难用传统结构化的方式进行表达,有时候甚至也很难使用电影或者小说这种叙事的方式进行表达。由第4.10.3节可以看到,这种信息类型最好的表达的方式是能够模拟复杂系统机制的游戏程序。
因此,在Reality World中,只要我们提供足够好的平台技术,让普通大众能够表达自己的机制,就能够释放这种能力,因为大众不同的人能够抽象提炼出这种关系。从而形成关于这些关系的表达。
4.2.1.3 作为巨大虚拟世界的地图
参见4.2.3节传送门
4.2.2 传送门
由于地图的限制,以及复杂度的控制,定义一些标准的传送门机制,点击可以进入私有的Creation
- 不管是Reality World中的内容
- 还是个人独立的Creation
这样Reality World更像是一个多重虚拟世界的入口,他可以去到很多不同的虚拟世界,每个独立虚拟世界具有更不一样的体验,比如在安全方面没有更多的限制,比如可以使用暴力,有坏人,容易遭到攻击等等。这些虚拟世界可以是一个广告产品的体验,一个独立的游戏,一个其他互动内容等等。

由于Reality World主要是基于现实地板,因此形成一种虚拟与现实结合的体验。
4.2.3 Point and Click
为了简化操控,可以使用Point and Click模式为默认主模式。
4.3 源动力
4.3.1 用户:创作和体验自由度
相比其他大世界,固定的模式,模板,用户完全可以自定义自己所属的任何东西。
- 自己创作的建筑可以有完全不同的行为
- 自己的Avatar也可以设置不同的行为
总之,这种自由性产生了两个结果:
- 控制,而不是仅仅体验,自己设计创作
- 这个世界的体验会更加丰富,而不是可预期的
- 每个用户展示给其他玩家的内容也是丰富,而不是固定的模板
4.3.2 开发者:更活跃的经济市场
平台提供一个更接近真实社会的经济系统和机制,使得Reality World里面的经济生产能够根据市场行为,使优秀的内容更加获益,从而使得整个经济系统更加活跃和繁荣,来为不同的用户创造价值。
4.3.2.1 持续经济
相比于传统的数字经济市场,构建持续消费的经济体制来是开发者获益更多,并且可以持续获益。参见1.4.5节内容。
4.3.2.2 广告内容
通过提供独特的机制,使得广告语产品融为一体,提升广告的效果,从而提高销售数量。见1.4.2节内容。
4.3.3 标准作者:高级抽象能力的巨大收益
标准作者是Reality World里面最具价值的用户:
- TA具有对现实世界最高的抽象和设计能力
- 这种抽象能力使得Reality World的体验能够进化得越来越好,并且覆盖的范围会越来越丰富
- 为了维持这种利益,标准作者还会很好地维护标准社区组件的开发
所以,平台需要给标准作者最高的经济利益,只有TA们才会使整个平台越来越健康。
4.4 安全和所有权
USD的好处在于,可以把每个用户自己创作的Creation保存为独立的文件,这样方便独立的编辑、更新甚至删除;然后又可以把所有用户的内容合成到一个场景,只需要记录它们的相对坐标位置等信息。
在这样一个大世界中,权限有两种:
- 是对于单个用户自己的Creation,其中的组件可能来自多个开发者,这些不同的组件之间可能需要通信
- 第二种是当将所有用户的Creation合成到一个场景中,它们可能使用相同的组件,这时候会导致一些非法的访问
从某种程度上来说,我们真正应该关心的是后者。即是说,对于前者来讲,尽管用户使用了多个开发者编写的代码,但是对于用户来讲,最终的Creation都是他编写的代码,所以对于用户而言,他应该保证的是所有组件组合在一起是否能够正常工作,而不是去分配组件之间的访问权限:一是本质上组件访问的都是他自己的数据,二是这样的关心涉及到了代码的组织和开发逻辑,这不是用户应该关心的。但在这种情况下,确实会存在有些恶意组件破话数据的问题,这种应该小心审核组件,并且依靠举报等方式监管。这本质上是一个监管的问题,对于用户而言,他应该认为他使用的组件应该都是安全的。
如果某个组件对某个属性的修改超出了用户的预期,例如用户可能只希望只读,但是该组件确实读和写。这样的情况也应该是正常的,因为组件对变量的访问权限本身是包含在组件的逻辑之中的。如果用户认为这种权限越界了,用户应该选择使用其他组件,或者修改组件。因为直接修改属性不让其访问,这可能破坏了组件本身的意图,使得其组件的功能完全不生效。
所以readonly或readwrite权限标志应该是用来处理Reality World这种多Creation共享的场景,即我们的数据能够被不认识的人怎么访问。但这种机制会存在一下的问题:
- 直接对单个变量进行声明会显得非常复杂,所有实体的所有变量可能会多达几百个
- 直接对Creation既进行设置又会导致大部分共享交互的机制建立不起来,因为用户倾向于把所有数据设为私有,这使得基本上无法与外界交互
- 诸如RenderComponent这种数据,用户是不可以设置权限的,不过这种情况由系统决定就好了,例如系统不让编辑这部分属性,例如物理和可视相关的属性基本上都属于这种属性
用户还是应该对每个实体的每个变量管理这种权限,由编辑器或者系统动态将所有公共的符号变量总结到一起,并按类别形成一个如iOS系统中Setting的列表,由用户统一设置,这样在打包的时候直接修改这些权限设置,这样这些权限设置到实体级别是不可见的。
但这种Setting表只对Reality World有效,如果不发布至Reality World,则这个功能根本不可见。也即不会允许第三方开发类似Reality World的应用--开放世界。
这里由于符号表的概念,也简化了整个权限设置的复杂度,即同一个符号即使有多个实例,它的全系均设置一次,避免了对所有属性实例分别设置,因为符号本身也是包含了意义在里面,而不仅仅是一个随便定义的变量名字。
4.4.1 RealityIDComponent
每个Entity都应该具有RealityID这个字段,用于区分System的访问权限,知道所属关系
4.4.2 readonly
对于不同用户之间的权限问题,它们只能是readonly,即用户之间只能读取数据,不同写或者修改数据。
在这种情况下,将System强制与一个Component关联是有意义的,这样System是有所有权的,它属于某一个特定的Entity,而每个Entity拥有特定的RealityID,因此可以便于控制。如果System是系统独立方法,就只能拿到Entity之后才能决定其数据是否可用,这种情况下如果权限不够,则会造成浪费。
所以系统应该避免读取没有权限的数据,由于System与实体关联,就可以比较权限,即对于RealityID不等于自己的数据,不能进行修改操作,并且是否可读也取决于用户的设置。
这样对于程序而言,有三种权限:其中readonly和readwrite应该是Creation内部的事情;这里的readonly还有应该拆分成RealityID内部和RealityID之间,比如使用share
- readonly
- readwrite
- share
4.4.3 重新加载
由于用户可以随时修改权限,因此当某个用户修改之后,其他正在Reality World的在线用户应该对其进行重新加载。
4.5 稳定性
需要确保每个Creation在提交之前,运行时是稳定的,否则程序中只要包含这个Creation就可能导致崩溃。在Reality World这种完全开发的世界中,这个问题更是严重。
这里,核心问题其实归结为一个,即程序的稳定性,所以对所有的组件要进行审核,以减轻对后面用户Creation稳定性的检查。
所有需要提交到Reality World的必须是经过Reality World验证过的组件,否则无法发布至Reality World,但是用户自己的Creation则可以使用未经验证的组件,因为这影响的用户范围很小,用户一旦发现问题自己去解决。
4.5.1 Reality Verified Components
对组件进行审核与测试,合法的组件才能被用户使用。
未经审核的组件自能用于小范围测试。
4.5.2 提前预测过期组件
对于那些合法但是比较旧的组件,可能导致跟标准不再兼容等导致程序无法运行,对于这种过期行为要进行判断。从两个层面来保证稳定性:
- 提醒用户及时更新
- 对于未经更新的代码,系统能够在加载时动态判断,然后丢弃与标准不兼容的代码
通过以上的机制,能够保证整个Reality World的稳定性。这对于一个大的动态更新的世界至关重要。因为:
- 一方面又不能限制开发者自由提交代码,这样就不具备开放性,但是这就容易导致不稳定性
- 另一方面必须保证整个系统的更新机制,因为维护太多过期的组件,对于这种系统来说成本非常高,必须促进系统快速更新
4.6 经济与交易
由于安全性的原因,所有两个用户之间的交易,都需要调用一些特殊的系统API,这些API不应该特定于Reality World,而是所有Creation中涉及消费的都可以,因为本质上交易就是两个Reality ID之间发生的事情。
4.6.1 及时购买
3D的东西没法像传统商品一样通过图片的方式浏览就可以获得很好的了解,因为它是一种体验,视觉只是其中很小的元素,甚至视频也不是最好的了解方式
比如传统的广告,我们通常不能获得太多体验上的信息,更多是其他一些非产品因素
所以需要一种新的购买模式:当你在体验一个互动内容的时候直接一键购买
比如你在试驾一辆车,获得不错的体验之后一键购买
比如你跟好友一起玩游戏,看到好友使用的某个交互内容
4.6.2 智能购买
在用户试体验某个内容或者看到某个内容时可以理解购买,就像在商场的购买体验。
4.6.3 直接发布而不是广告
You can play the game with. And that was incredibly interesting to see. Um, I think this is going to be the future of this shared 3d entertainment, medium. Um, it's not about Facebook pages, it's not about advertising. It's about actually delivering meaningful experiences that people can interact with. And that become part of this much larger world, right? So the programming model for the metaverse must incorporate, uh, the assumption that everybody's on objects, they build should be able to interact sensibly and fit and safely with everybody else's objects, your car, you know, built by Ford should be able to interact with your motorcycle built by Dati.
If an architect to be is a major work of architecture in the metaverse, you know, that should work with all the different player models have been introduced into the game and everything should work together. So I think the center, the focus of any programming model, uh, for the metaverse needs to be open world compatibility over time, open interfaces, um, which can evolve and be extended over time.
4.6.3.1 现在的可能做法

对于这样的需求,现有可能的做法是:
- 对于每个广告产品,广告商自己开发一个应用程序并发布,由于开发者具有所有的源代码,所以可以任意交互
- 如果要实现自定义复杂交互,每个广告商需要把源代码交给平台,由平台统一部署发布,并要求用户更新
- 广告可以使用有限的交互,按照一定的标准开发,这样就可以不经过开发商自定发布
显然这些都不是最好的方法,所以RealityIS可以创作全新的商业模式,这里任意广告商可以完全按照自己的设计定义功能丰富的产品,然后在Reality World中自由发布。
4.6.4 市场经济
实际价值由人们主动参与经济的行为决定,而不是单纯的投票或者其他机制决定,确保虚拟货币的数量是由经济行为决定,虚拟货币的价值需要与这种行为产生直接关联。
所以对于Reality World的经济来说,有两点是至关重要的:
- 确保经济的主要推动者是人们的主动经济参与行为
- 确保虚拟经济的货币与人们实际感受到的价值相关联
Reality World通过构建高度开放的世界,避免中央式的干预来实现这样的经济运作。同时标准的发布、反馈以及人们实际使用相关联,通过人们的主动选择来实现价值的筛选与传递。
世界的经济规律是相对确定人,人们不管是在真实世界还是虚拟世界中都需要有类似公平的机制来保证人们的经济活动参与是有意义的,而真实世界的经济规则是人类数年来积累的成果,它也是人们熟悉的思维,只不过虚拟世界可以通过数字技术更少中央集权式的干预。
那既然是跟真实社会一样的经济体验,还有什么意义需要构建一个虚拟世界呢?尽管两者的经济体制相似,但是在虚拟世界中可以创作和体验在真实世界无法实现的事情和体验,这就是虚拟世界的价值,而且这种价值通过经济的机制而得人们觉得也是有意义的。反之,没有任何经济意义的事情可能就是无意义的,人们会把很多事情当成经济活动的一部分,即使是精神上的体验也可以是经济活动的一部分。
经济思维是人们觉得所有参与与付出会有意义的一种心理基础。
4.6.4.1 单次购买不具备任何价值
当然,尽管用户的经济购买行为为整个经济系统产生价值,但是这种价值是一种总体行为,而不是由单词购买决定的。
4.6.5 区块链
区块链解决了两件事情:
- 它通过技术手段定义了物权,并且一旦你拥有物权,别人没法篡改,因为整个任何对该物权的转换都会被记录,而这种转换只有在所有者同意之后才能被执行。
- 它的账本机制,实际上意味着物品可以被任意转换或者说交易,这就为商品的自由交易创造了可能。反观传统的中央式的数字经济,一件物品的交易通常只发生一次,一般平台不会提供这种无限转卖的机制,即使提供这种机制,通常也是认为不可靠的,因为这些交易账本可能被篡改。
但本质上,区块链只解决关于物品交易的过程,这个过程对于经济活动只是辅助性的,但是它并不是经济活动的全部。例如:
- 它没有解决能否保证虚拟货币与真实价值的映射是否安全可靠的问题,这可能导致上当受骗;
- 它没有解决物品在交易过程中,怎样更公平地决定物品价值的机制;例如在真实世界中,人们的经济交易除了产生物品交换,这种行为还有很多其他经济价值,比如最核心的是决定物品的价值。这些机制跟区块链的理念都差很远。
除此之外,它约游戏互动内容需要大家分享和共同玩游戏才能产生价值的理念是相违背的,区块链更鼓励封闭和秘密的行为。
4.6.5.1 价值关联
区块链不解决价值关联的问题,一定数量的虚拟货币到底关联多少实际物品的价值,以及怎样关联,这不是区块链会考虑的。如果这个问题不解决,也许从源头上就不可控了,后面的物权保障也就没有意义。
4.6.5.2 价值的决定
在交易过程中,物品的价值到底怎样变动,没有更好的机制。
在真实世界中,一个物品的价值肯定不是由投票来决定的,它是由人们的经济行为来决定的。投票是可以被操作的,或者也可能是虚假的。但是真实的经济行为是不会说谎的,即使某些个体存在偏差,但总体而言是客观的,这就是真实世界物品价值决定的机制。
所以,在Reality World,我们从技术上把人们这种经济行为融入到商品价值体系,包括:
- 私人网络之间的口碑,例如如果你决定某个东西好,你会分享给朋友,这样的推荐更靠谱,你用朋友之间的关系来保障你的口碑,而不是随便一句不负责任的话。而为什么你会分享给朋友,是因为虚拟世界的互动大都多是需要和朋友一起进行的。
- 竞争,对于相似的功能,可以有多个不同的组件实现,这些组件之间会相互竞争,因此竞争也会指导定价,对标准也是一样。
因此,Reality World是更接近真实世界的运作方式,它保证物品的价值是与你需要付出的代码匹配的。
4.6.5.3 转卖没有创造价值
在传统的NFT系统中,物品被反复和大量转卖,而不是像游戏一样被大量玩家真正的体验。在这些转换过程中,甚至大部分买家和卖家根本就没有去体验它真正的内容,当然也不可能有机会去改进它,或者去增加它的价值。这样的经济活动毫无意义,它对整个经济系统都毫无贡献。
4.6.6 Royalty
对于经济活动中的生产者,有两种激励方式:
- 一次性费用
- 版税
在现实生活中,一次性费用通常发生在商品交易的终端,即商品转移到最终消费者的过程中。但是对于一些比较强势和技术竞争力强的生产者,他们也会使用版税的形式,例如徕卡跟华为的合作,是按照手机销量进行分成。当然这些都会随着一些话语权等因素可以调整。
对于Reality World中的标准和组件开发者而言,有两种不同的影响:
- 版税可能更加容易鼓励开发者提升单个产品的能力
- 而一次性费用可能更容易鼓励开发者开发更多的内容,但也许它没有精力去提升单个产品的竞争力,因为无法转化存量用户的价值,永远只有新用户才能产生收入。
当然开发者也可以开发更多的标准和组件,但是因为版税的收益主要是取决于影响力和知名度,不同的影响力和名气其版税收入的差距非常大,所以开发者更愿意花心思提升单个标准或组件的品质,因为只要有好的影响力,这套机制以保证ta赚取足够的收入。就好比苹果手机,TA需要维持自己的品牌,然后销售就会很高,而其他一些手机厂商则会尝试开发多种不同定位的产品和开发细分市场。
我们显然是需要鼓励开发者制作更好的标准和组件,而不是开发数量更多的标准和组件。所有对这两类开发者使用版税的形式。
4.6.6.1 标准税
即组件开发者,在每销售一件组件时,标准的制定者可以收取一定的版税。
如果组件开发者只是基于标准开发组件,而没有形成任何销售收入,是不需要向标准作者支付费用的。这样降低组件开发者的门槛。
同样,标准作者在没有任何标准税收入之前,也不需要向平台支付费用。
4.6.6.2 组件税
即普通用户使用某个组件开发的内容,在产生收入的时候会收取一定的版税。
当然,对于组件税来说要更复杂一些,因为用户的收入可能来自多个组件的结果,很难清晰判定某单个组件的贡献。这块后续在梳理一下思路。
4.6.9 完整的生态
既要有消费者,生成者,工具制作,供应链,才能全域激活
4.7 Social
4.7.1 私人化社交

互动内容需要和朋友一起玩,会给朋友推荐自己觉得还玩的东西,形成良性经济系统,间接也会导致社区更文明
大多数类Roblox 平台都是类似的模式,它们看起来像一个应用市场
只有私人化才能促进大众创作,就像Snapchat
甚至抖音视频大部分都是围绕自己的
一个应用市场型的应用,是不会激发普通用户的,就像你要求普通用户创作严肃的大片,他们做不到,所以必须私人化
跟微信的模式,借助私人小圈子的强烈分享和创作需求
4.7.1.1 淘宝和微信
淘宝的模式类似于传统经济的数字化,只是一个销售平台,社交性几乎不存在。表现在一些方面:
- 例如你买了一个东西,几乎没有什么渠道把这家店或者这件商品分享给好友,甚至有时候还需要通过微信去分享。
- 一家淘宝店的品牌效应相对比较弱,一方面是多家店可能销售同一种商品,一方面是没有维系店家和消费者之间关系的一些方式或工具。所以淘宝商店的声誉或名声主要靠流量,或者销量这一单一属性,但是因为受流量这种平台控制力量的影响,销量本身又是受流量影响的,导致小品牌不易于成长。
- 即使你看到朋友的某个东西较好,这种社交导致的推荐有时候并不能直接转化到这家店,一是分享不方便,我还要去订单里搜索然后转发,这是一个麻烦的操作,但是对比微信 ,我想分享的东西都在朋友圈,大家随时可以自己去看。当然对于淘宝,更有可能的情况是大家说个品牌名字,大家自己去搜索购买,这个时候,品牌的效应的更大的。
所以总结起来可能是两个方面:
- 淘宝并不是一个创作平台,所以多个商店之间同质化很严重,导致几乎没有品牌竞争力;而反观游戏市场,一个游戏是靠创造的独特性来建立品牌声誉的。
- 淘宝没有社交,因为单纯围绕商品购买构建社交是没有太大吸引力的。社交更多源于生活,在商品之外,还有更多的活动,商品购买活动甚至可能只占人类活动很小的一部分,比如很多其他更具价值的服务是通过淘宝购买不到的。何况一个纯商品推荐的社交会引起人们方案,这就是为什么淘宝构建不起社交能力。
但是反观微信,微信完全是社交驱动。你的每一个会话,每一个好友,每一次参加群聊,都是因为你的文字所涉及的某件事是与其他某个人相关的。这些大量的沟通交流目的,其实背后的价值很大部分也可能归类为价值,哪怕是交到一个单纯的好朋友,其实日后也会产生某些价值。
因此可以说社交是构建价值的重要过程和手段,而最后的交易反而只是一个很简单的过程或者机制。
但是微信没有价值交易的方式,或者说这种构建价值和价值交易分离的架构是一种比较好的架构,或者说构架价值的过程与价值交易本身不需要那么多的耦合。
总结:
- 价值交易平台,但是打通淘宝的实物或者纯商品化的形式,使之泛华到所有价值服务,比如游戏体验,软件功能
- 创作平台,创作不光生产商品,而且结合销售平台,使得销售商品同质化较低,因为它不是一个单纯的销售平台。
- 社交,游戏天生具有社交性,但是现在的游戏主要只是一个好友列表,排名。缺乏微信那种,为了某个目标或关系,主动发起社交的方式,例如你发现一个好玩的游戏,是否可以更好地邀请朋友加入进来。传统的方式要去微信中分享,每次进入都需要重新分享,有一种割裂。而我们会保存一个最近列表,如果你们经常玩一个游戏,打个招呼直接就进入了。微信不会为一些专用的社交目的进行服务。
关于社交交易:
- 更好的推荐,如上面第三部分。
- 直接交易
4.7.2 关注现实
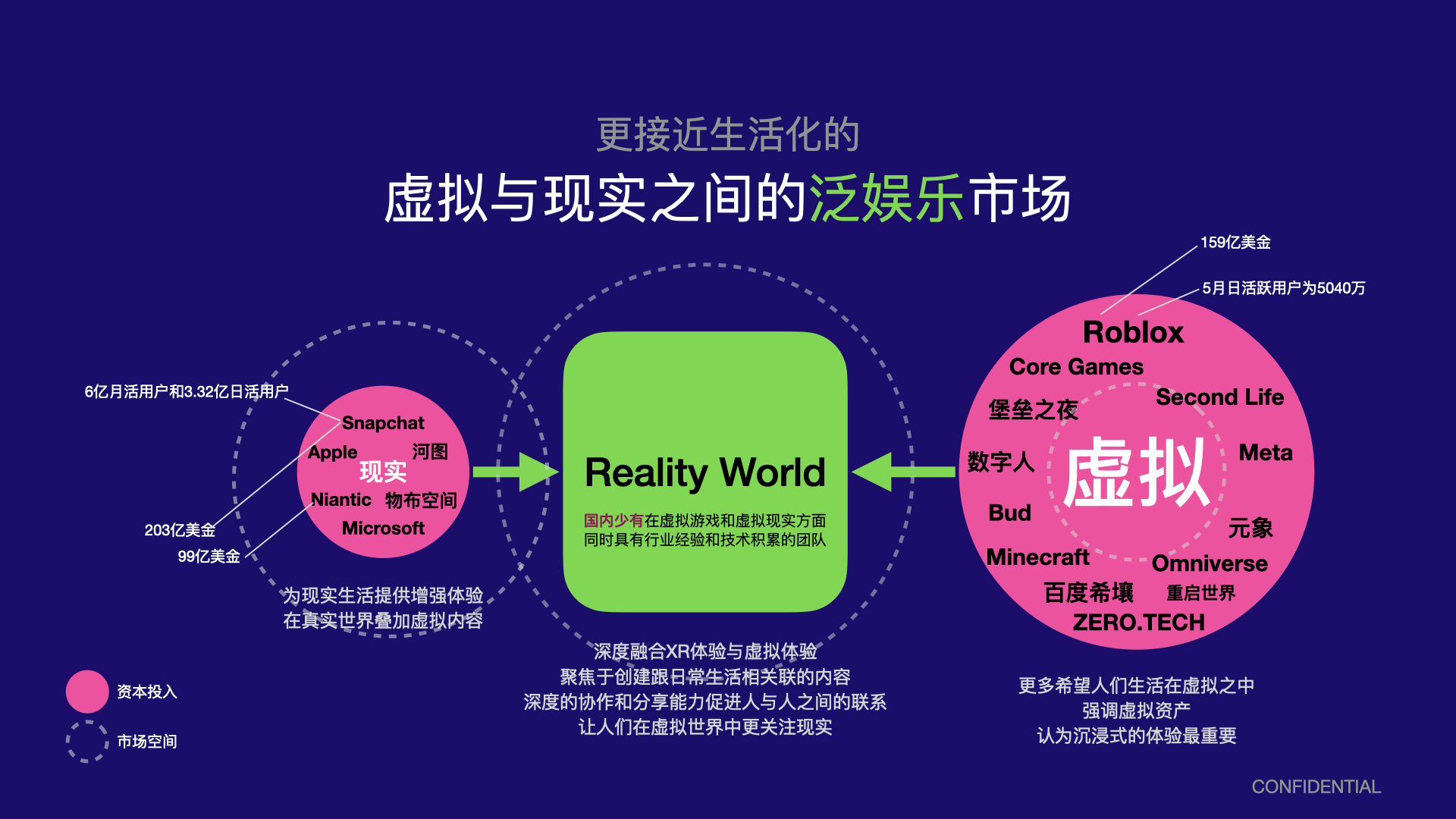
4.8 创造性和开放世界
在游戏和电影等3D载体的娱乐体验中,有三种主要的相对比较独特的类别:
- 游戏性
- 故事性
- 创作性
游戏性主要对应于游戏,它是游戏中的灵魂,有游戏设计师根据自己的经验和创造力设计出的,让玩家产生心流的瞬间体验
故事性主要对应于电影
创作性的最大不同和魅力在于,创作不仅仅是一种被动的体验,它是需要思考、构思、自己个人对生活各方面的理解、感悟和想象力的,因此这种要求更高,它的结果对应的不仅仅是一种游戏态的心流,它对应于成就了,甚至某种精神物质,创作的东西才更对应于价值,才更容易产生交易
如果一个导演或者一个艺术工作者,他持续创作优秀作品的动力主要来源于创作的体验,那么将这种能力释放到普通大众当中,也一定会是不错的体验
过去的科技我们聚焦于改善一些实用产品的体验,它体现在去流程、便捷性、效率等;互联网时代除了提升人们之间的交流效率,他很大的体验改善在于释放了观察世界的能力,就是视频和照片,本质上照片和视频所反应的是每个人感知和观察世界的能力,比如:
- 使用不同视角镜头观察同一世界不同的美感
- 捕捉不同感兴趣的画面表达自己的个性、理解、主张等
- 拍摄感兴趣的视频故事反应自己的兴趣、主张等
- 转载不同的视频和图片信息表达自己的观点、价值观等
- 对已有带有各种历史、技术、文化等信息的图片和视频添加自己的理解,抒发自己的主张、认知、观点:价值等
但所有这些,他都是在观察或者学习了解这个世界,它的工具通常只是镜头,除此之外它几乎没有其他工具,他的表达能力很受限于我们眼睛所能看到的事物
而反观我们的世界为什么多姿多彩,是因为我们用各种工具如创造了建筑、车子、衣服、草地、公园、艺术作品等等整个世界,这些创造的价值是因为他们融入了人们的理解、思考、想象、甚至梦想和期望等等
创造伴随着整个文明,因为人们创造的东西改善了这个世界,提升了人们的认知、理解、生活效率、生活质量等等,所以它促进了文明进程
但是现实世界的创造性是否足够了,受限于很多物理约束,很多创造肯定是受限的
但是创造虚拟的内容相较于物质物品是否具有价值,只要创造的结果提升了人们对世界的认知和理解、提升了生活质量、精神世界,从而也就促进了文明的进程,那么他就和物理世界的创造是等价的,从这个角度说,它甚至可以不需要跟物理世界发生关联,就像一些科幻电影或者一些玄幻小说讲述的故事那样
所以,科技的下一个具有社会价值的使命是释放创造力和表达能力
当前在创造力和表达能力方面最容易实施的是写作:可以基于自己的理解创造新的理解;其次是电影和游戏,但是他们仅面向少数开发者或者电影工作者
4.8.1 分工的重要性
同现实世界一样,虚拟的创造也必然需要分工,不可能所有东西都需要每个创作者从零开始搭建
分工意味着劳动力复用,节省时间,分工也意味着价值的交易
商店数字资产、组件等其实就是分工的产物
现实世界的分工由人类自身驱动,例如行业标准由行业内部讨论决定
开发出能够易于分工协作的架构,是释放创造力和表达能力的重要基础
4.8.2 共同创造拉近距离
现实生活中的人们之间的距离:
- 亲情
- 友情
- 在一起工作或学习
围绕着做一件共同的事情,或者说为了一些共同的目标或者商业目的,合作做一件共同的事情,这是生活中最多的拉近人们距离的方式,这也是我们日常社交圈子扩展的主要来源
因此,创造性不仅仅针对个人,还需要围绕共同目标,共同创造和协同,才能促进人们之间的交流和了解
4.8.3 创造游戏性与一般创造
游戏性有玩法,目标,策略,延续性较大。
一般创造更多只是看一下,即使有交互,交互的目的性也很弱,所以需要把单个一般创作内容的体验,转化为持续,有目标和吸引力的一种体验很重要
一般游戏中很多时间的操作在于探索,探索中一方面是了解环境,一方面是收集资源,所以这些一般的3D内容中要有类似的机制,例如每个内容都可以获得一定的经验,但是经验跟设计交互有关,但经验是共享的
4.8.4 时间创造价值
如果只是玩别人设计的游戏,或者看电影,这通常只是个人视觉上的体验、个人理解的升华、心流,这种心理感觉往往很难传递给其他人,例如当别人给你讲述某个游戏体验时,如果你要获得类似的体验,你必须自己亲自玩一下,他没发通过口述传递给你
即,如果认为这种游戏体验是一种价值,那么只有游戏开发者创造了价值,而大部分玩家也是获得价值,并且这种价值不可转化
但如果我们希望这个世界会衍生价值和创造价值,则我们希望普通的用户能够创建可以交易的价值
时间可以创造这种价值
如果没有创造,仅仅是体验,这其实又回到了传统游戏行业:
只有少数人可以创造游戏
如果要创造出好玩的体验,需要巨大的时间
玩家都在玩同样一些游戏
只有少数游戏正在被广泛体验,少数人受益
丰富性不够
缺乏游戏之外的很多体验
只有创造和游戏体验结合,才能均分和消耗更多的时间,让用户能够持续投入,而传统游戏的活跃度往往跟一些新游戏或者经典游戏相关
4.8.5 创造的方式
- 终端用户不会直接建模,除非是程序化生成,不需要用户雕琢精细网格,这部分还是要回归传统DCC,那里可以进行更精致微调,在3维空间做不到(这样也就避免将传统DCC的工具引入进来,客户端只需要做跟位置相关的交互,大大简化,现实世界人们加工某个东西也是基于现有物体,而不是从零开始)
- 程序化生成,一些不需要精致网格,并且有自由度的物体,如地面,山脉等等,大部分跟环境有关
最后的交互是一个非常简便符合视觉直观常识的交互集合,用户基本是环境靠基于手势的程序化生成,个性物体靠模板,谢谢模版通过DCC生成,大部分脚本和逻辑也是针对个性物体
粘性,由于创造花费了巨大的时间,因此粘性更高
4.8.6 大世界合成能力
单次创造是局部的,单个局部场景可以合成到一个大场景,如果把这种能力开发,例如基于一块固定类型的地或者环境,组成自己的小世界,就容易让一些志同道合的人一起去构建一个他们喜欢的世界,可以是科幻,武侠等等风格
- 鼓励合作与协作,是非常好的协作例子
- 也给其他人的游览带来更大的吸引力,宏大的,形成众多具有更复杂表达和文化的世界,这种文化的感觉需要复杂性来表现,局部较小的场景往往无法表达一种文化,甚至一个文明
- 文明本身自带故事了
大地图在PC Create上创建,或者提供一些模版,像Minecraft Editor 一样
4.8.7 虚拟世界巨大的探索成本
虽然沉浸式、宏大的虚拟世界具有很好的体验,但是相对于影视来说,其探索成本更高,例如看完一部魔戒需要三个小时,但是探索一个中土世界可能总共会花费很多天时间:
- 这对于普通用户来讲可能是不可行的
- 普通用户可能仅仅随便看看,无法深入体验故事
- 玩家对虚拟世界的探索本质上源于未知的体验,这种未知并不是单单一个一个宏大的虚拟世界,而是故事或者玩法,因此需要花大量精力设计,而一旦玩家探索玩所有未知,那么这个世界便不再新奇,除非它像真实世界一样不断会有新奇故事发生,那必须是一个开放世界,用户能够高度自定义或者甚至自我演进
所以,开放世界架构及其重要
4.9 Third party apps
4.10 社会价值
4.10.1 更好的信息传播媒介即信息表达方法
按照信息的组织特征,其可以分为三类:
- 一种是非常简单,能够用结构化的方式简单描述的信息,例如一个公式,一间事情的方法,菜谱,一条朋友圈,一段视频等。这种信息所表示的含义通常是明确的。
- 一种是描述人与人、或者人与事情之间的关系,这种通常比较抽象,它不能有一个很确定的、简单的方式进行描述,比如一个故事,一间艺术品,对他的传播涉及一些解释,甚至一些相关的视觉符号,文化等。
- 第三种是机制,这种机制往往是复杂系统,它既不能像第一种信息那样能够简单描述和传播,也不像电影等艺术品那样可以直接解读,由于机制内子系统构造复杂的相互关系,因此它需要新的媒介进行传播。
电影更多是对人与人或者人与社会之间的关系进行描述,理解和表达,这种关系往往是非结构化的,它很难使用一定的规则、模型、定律、公式等等进行描述,所以这种非常适合于文学、电影、美术、戏剧等等形式。
与围绕人的关系情感不同的另一个维度是理解社会运作的机制,比如交通,旅游路线,城市不同的分区,工作与公司的分类等等,这些反应的是社会机制,他们是可以量化和结构化的。

很大的一个特点是:
- 人与人之间的关系往往是容易用比较简单的信息进行表达,尽管这些简短的信息是需要非凡的人对其进行高度理解和抽象提炼,比如一部电影通常就足以讲述一个深刻的道理
- 但是机制却是更复杂的,因为机制本身是一个复杂系统,它由许多相互相关的子系统构成,而这种关系往往不是人易于理解的方式,比如人很容易理解一个公式,但是复杂系统无法表述成一个单一的公式,它是一个多维线性函数,它的理解蕴藏在所有那些关系当中,不同子系统的数据会导致差异很大的关系,有多种因素的影响,而不是一个清晰的逻辑,所以他比如不太能够用一部电影来表述,或者说电影业务能够做一些科普,但是真正的理解你必须去使用那个系统,这种“使用”从数字化的角度来讲就是模拟,而游戏就是这样模拟的核心方式之一
所以,大部分这样的社会机制都可以借助3D来进行学习和理解,甚至参与影响
另一方面,人其实是深度跟社会高度耦合的,很多人与人之间的关系也来源于社会机制的影响,所以社会机制本质上也是另一种帮助理解人与人之间关系的一种方式
4.10.2 释放实时模拟程序机制的潜能
如上一节的信息分类,传统的应用程序模型只适合处理结构化的计算,这种计算通常是确定的,其应用结构通常也是不会的,例如微信、淘宝、抖音、支付宝、大众点评等等这样的应用程序。在这些程序当中,通常是由用户发出一个操作指示,然后应用程序按照固定的逻辑执行某个结构基本上不变的计算。

然而,现实当中还有大量的类似复杂系统的机制,这类信息对人们理解这个世界和社会可能更加至关重要,并且这类信息通常不能使用传统的应用程序架构进行表达。游戏程序架构是非常适合处理这类信息的,但是游戏程序目前还没有被广泛使用,不管是在开发工具、开发流程还是开发成本上它都存在着很多问题,还不具备这样的潜能。
所以,RealityIS有机会去释放这样的潜能,使得游戏类实时互动内容的开发变得更加简单,例如跟开发一个应用程序差不多。也许在这样的情况下,这种实时模拟的程序架构也许可以成为整个数字化的常态。这样数字化能够在人类文明进程中进一步发生更大的推动作用,因为人与人之间有一种更高效、更具表达力的信息表达方式。
4.10.3 复杂系统的模拟
复杂系统由许多部分组成,这些部分单个看一般都很容易理解,但把它们组合在一起后形成的复杂系统大都能表现出无法预测的惊人特性,很难通过单独拆分分析每个组成部分来解释这种现象。可以通过引入正/负反馈循环来影响整个系统。
复杂系统其实能够用来表达是真实生活中大量的信息,他对于我们理解人与人之间、人与社会之间等等的关系至关重要。通常这些知识要比我们一般能够从书中看到的信息要多得多。
例如关于管理,其实它也是一个复杂系统,它有很多影响因素,如果我们把这些因素用一个复杂系统来表达,这样学习者可以通过交互的方式,对某些子系统施加影响,来实时看到它们对整个管理体系影响的效果,这样的方式我们不仅可以用来学习这样的一些系统机制,也可以用来对一些机制其进行模拟和预测。
这种能力是很难通过其他应用程序来实现的,所以这样的系统将给人类的文明带来巨大的影响和推进。
4.11 标准
基于全局和公共符号表构建沟通方式和标准。
4.11.1 传统做法的缺点
Epic CEO在其演讲《Fundamental Principles and Technologis for the Metaverse》中指出,为了实现一个Open Metaverse,像我们今天的各种互操作系统如Web等一样,需要定义非常多的标准用来实现Metaverse内部各个实体、对象等之间的通信,例如关于用户的身份、资产所有权、社交图谱等等。他进一步指出可以参见现在的一些标准如Html+JavaScript等进行设计。
然而实际上但我们再深入去思考这种方式的时候,会发现也许我们并不能使用同样的方式去设计Metaverse的标准,例如其中两个最重要的原因包括:
- 实时性:现在的标准指定都是通过文本的形式,然后各个子系统对文本进行解析,这种大量实时的文本解析和字符串处理在游戏程序中可能会导致性能问题。
- 互操作性:即使可以解决性能问题,它本质上只是一个虚拟机,我们将别人的代码放在我们的环境中初始化和分配变量,因此可以获得直接的变量地址,但是拿到地址之后要进行正确的通信还是需要了解关于函数的定义等等,否则我们只能约定一些固定的调用行为。
以上这套机制假说能够很好的工作,它也只是针对双方约定的接口进行通信,这就限制了自由度。传统的一些互操作系统本质上它们之间的通信非常简单,基本上可以使用一些固定的规则进行描述,且标准之间变更的频率非常低。
而Metaverse是一个更加活跃的大世界,它就像真实世界一样运作,因此它本质上不能使用这种限制比较大的方式,例如我们生活中跟其他实体之间的交互是非常自然的,我们有很大的自由度,没有被严格限制每件事情一定要按怎样的方式做,当然它也存在一部分固定的规则,例如我们要遵循交通规则,法律规则等等。
4.11.2 开放的标准架构
如果Metaverse是要尽可能模拟真实世界,或者说它的整个系统更符合人类的认知,它的标准必须支持两种方式:
- 既要能够像传统的标准那样制定固定、需要公众共同遵守、不太容易变化的标准,如交通规则
- 又要能够支持局部群体之间定义自己的小标准,并且对于这些小标准,群体之外的参与者只要愿意遵循该小标准对应的协定,TA们就可以很轻松地参与到这个小群体中来。
上述的机制很像现实世界的运作方式,它让人们即有很大的灵活度和自由,同时也受一定的社会约束。
RealityIS的符号表就提供了这样的机制,符号表本身提供了一种定义标准的机制:只要两个独立的程序包含(类比于遵循)这样的符号数据定义,它们自然就遵循了相同的标准。所以,对于全局符号表,这就是对应一些公共标准,而对于一些局部的开发者,它们可以创建自己的局部符号表,从而构建局部小标准,这样理论上来说就是一种完全的自由度,比如你甚至可以定义别人完全不知道的标准,这种自由度是存在的,只是那样你没有办法跟别人进行交互。
所以,你需要去推广你的标准,但是这种推广也不是把你的东西放到一个组件市场或者去做广告,你可以通过两种方式去推广你的标准:
- 用户层面:你只需要将你的作品放置到这个世界中,当有其他人体验到它时,他可以直接就复制你的组件。虽然这种方式并没有引入新的开发者来遵循你的标准,但是它引入和增加了使用它的用户。实际上我们建立的标准,当被其他开发者支持之后,我们最终的目的还是希望通过更多的支持程序来获得使用的用户,从这个层面来讲,它的结果是一样的。
- 开发者层面:每个开发者定义的标准都可以发布到一个共享标准库,其实就是共享符号表。其他开发者可以搜索共享库,并通过对其引用以支持这个标准。这样,定义的比较好的标准就容易被更多的开发者引用和支持,因此被更广泛的使用。
符号表形成的标准系统是一套自我自进化的标准架构,在这样的架构下,任何标准不仅能够被其他独立开发者任意支持,以形成标准的推广;并且通过及时购买等方式,标准能够被更直接的通过用户进行普及,从而能够推动那些更好的标准被更多的人群使用。
通过上述两种机制,最终整个系统或者说世界,向着优秀进化的能力使标准实现自我进化,并且带动着整个世界进行自我进化。
4.11.3 标准管理
标准即是整体系统进行自进化的机制,也是实现用户实体功能的机制。它的整个管理和更新必须非常高效。
标准管理借鉴了现代应用程序市场的推送、源代码包管理、Github多版本管理等思想。但它同时也包含一些RealityIS独特的机制。它实现的功能不仅包括开发者向用户的推送,也包括用户向开发者甚至标准作者的反向建议,以及标准作者建议开发者针对新的符号进行开发的建议,总结:
- 标准更改:向组件开发者推送
- 组件更改:向用户推送
- 新增标准建议:标准作者增加新的功能,建议组件开发者支持
- 组件增强:用户对组件的建议
- 标准建议:用户或者开发者对标准作者的建议
- 特性建议:用户可以针对标准作者或者开发者提出新的相反的组件开发建议
整个RealityIS的自我进化功能都是围绕标准的一些列机制来实现的。
同时标准管理的另外一个大的目标是使用户的组件始终保持最新,减少维护旧组件带来的复杂兼容机制。
标准的管理有两条线:
- 一个是自上而下的更新通知
- 一个是自下而上的反馈建议
4.11.3.1 标准更新通知
如果标准本身有更改,会通知到所有支持该标准的开发者,提醒他们升级版本。开发者在收到通知之后,可以发布支持新标准的新版本组件。当然组件开发者需要实现兼容性。包括:
- 新增符号
- 符号重命名
- 删除符号
标准更新机制使得标准能够快速进化,而不会由于信息的滞后甚至不知道标准的改进而导致一个标准迟迟无法快速进化。相比于传统的方法,有两项改进:
- 它以标准为中心,标准的修改可以直接通知到所有关注者;中间没有任何时延。传统的方法通常需要开发者主动去关注某个标准,以开发者为中心去推动一项标准。传统的方法是一个大家共同来制定标准的过程,这种效率极低,而RealityIS反过来,先定义标准。可以这样做的一个原因是RealityIS简化了标准的定义:它仅关注一个逻辑结构中需要相互通信的参数。
- 它直接告知需要修改的地方,由于标准中的符号跟组件的变量引用关联,所以系统可以计算出哪些组件需要修改,什么变量需要修改。而传统的方法通常是通过文本的方式,如邮件,告知修改的内容,然后开发者再对照修改。这使得开发者能够快速进行修改。
4.11.3.2 组件更新通知
如果组件开发者更新了组件,也会自动通知到所有使用该组件的用户。用户可以选择一键升级,或者用户可以开启自动升级。
同样,由于组件都是结构化的、数据驱动的方式,而不是写死在代码中,所以系统可以较为容易地将所以这些组件信息抽取出来形成列表。用户的所有实体对象都可以很方便低罗列出来,所以就更方便用户对这些组件进行管理。
同时,这也意味着很方便地对实体对象进行管理。
4.11.3.3 标准反馈机制
有以下多种反馈机制:
- (向开发者)反馈组件功能:用户基于组件的功能理解和需求,用户可以给组件开发者提供反馈意见,以完善或增强某个组件。
- (向标准作者)反馈标准结构:可以向标准组织提出建议,例如修改、删除或者重命名符号。这里的反馈中可以是用户或者开发者。
- (向标准社区)征询新功能开发:可以在标准社区发布新的功能需求,开发者可以按照相关需求进行组件开发。
4.11.3.4 始终保持最新(版本管理机制)
为了减少对旧组件的兼容性维护成本,所有组件最好都是保持最新。
这里其中一条可选的做法就是用于只保存最新的标准,这样旧的组件就必须升级。但这可能导致有时候在组件没有更新之前无法工作。
另外就是标准作者可以设定一些旧标准存续的时间,给开发者和用户一段时间进行更新升级。
或者系统默认就是两个版本,其中每一个 新版本发布之后,旧版本最多存续固定的时间,如三个月,三个月之后自动删除。这种方式看起来是两者的一个权衡。
4.11.4 跨越标准
从逻辑上讲,组件关注的只有符号,而不是标准,标准只是组件开发者在开发组件的思考过程中的一种参考,他对标准本身没有直接的所属或者依赖关系。
因此,一个组件是可以跨域标准的。
如果我们把每个标准理解为一个子系统,那么这种跨越标准的组件就可以实现标准之间的通信,从而实现标准之间的联系或者关系。
例如整个天气系统包括云层子系统,海洋子系统,天空子系统,陆地子系统等等,然后这些子系统之间是存在一定比较简单的关系,从而形成整个天气复杂系统的。
4.11.4.1 与相关标准的属性
如果把每个标准看做一个更大复杂系统的子系统,那么每个子系统中必然有部分属性是与其他子系统的属性相关的。
因此,每个标准通常会包含少部分与相关标准有关的符号,对于这些符号,它们的属性值通常由内部的机制计算,然后这些值会影响到其他相关标准中与之相关的属性。
但是对于哪些是相关属性,我们不需要去约束它。这只是开发者脑中知道的一个概念。从理论上来说,标准的任何属性也许都可能与其他子系统有某种关系,因此我们不需要限制他,这只是对开发者的一种指导。
4.12 自我进化的Metaverse
一个不能自我进化的Metaverse就是一个游戏,这显然不是Metaverse的形态。此外,即便我们解决了多程序交互的问题,它只是增加了一个游戏内的系统会更加丰富。然而对于一个好的世界,这种丰富不仅仅是指数量上越来越多,而且需要在丰富上形成层次,甚至对于社会的运行机制,后者是更重要的,因为用户关注和需要的是有层次的信息,而不是更多海量可能存在大量无意义无价值的信息。然而,仅仅向其中增加程序的能力不能保证这种丰富形成层次。
当一个开发者向其中添加了一个新的程序,怎么能够判断这个程序的价值?并且是要通过用户的视角去评判这个程序的价值?
在真实世界中,社会进化的机制来源于两股力量:
- 少数优秀的人能够创造一些好的东西,这些东西不仅仅是指一个具体的实物,更可能包含一些结构、关系以及社会运作的一些逻辑,这些东西在Reality World就对应标准,标准的数据结构及其数据组合背后反映的是一定深层次的结构、关系和逻辑。
- 这些好的东西会被其他少部分人接触到,不管是地理位置上较近,还是熟人之间介绍等等,这部分机制在现实社会中往往通过广告 进行加强。当这一少部分人使用之后觉得真正有价值的东西,他们会形成推广的力量,通过人与人之间的关系把这个有价值的东西推向更大的人群,如此,那些最有价值的东西被逐步挖掘出来。
上述这两种机制导致的结果:
- 人们会觉得创造东西会有价值,你有机会被更多人使用,从而为更多人创造价值,你的创作也有机会被更多人认可
- 人们会觉得社会越来越进步,幸福感更强,因为你感觉这个社会在进步,你越来越能使用到更好的东西
这种进化最根本的力量来自于社会个人,而不是少数中央机构。所以要实现这样的自我进化,我们一定要有类似的机制来释放个人的这种力量,而不是依靠平台,平台没法做这件事情。
4.12.1 标准的价值
符号表是实现多程序/多应用之间进行互操作的核心机制,标准则构建于符号表之上,它是一组语义上相关的符合集合的概念。符号总是存在于一个标准之中,即符号按标准的形式进行组织。
相比于单个符号,标准是对现实世界某些关系或逻辑的抽象。标准中的符号是围绕某一类关系或者某一类事物的核心的数据属性,其中通过这些数据要能够描述该类关系或数据的特征以及各个层面,这些属性应该是便于人类理解的。
所以标准是Reality World的一个核心指标,它也是代表用户创作的最高抽象能力,我们对于现实世界的一些关系的深刻抽象理解都蕴藏在标准的定义及其结构中。
Reality World中的所有组件都是围绕标准来开发的,这保证组件不会太混乱,因为它们是按照很严格的逻辑来逻辑的,这种逻辑由标准来定义。同时他也保证组件之间的交互变得有意义,相关性比较高,因为相对于同一标准的不同组件,它们彼此知道应该怎样协作,因为这些标准中的符号不仅包含一些的相关性,也包括对逻辑开发的指导。
标准的这种定义形式也使得标准易于定义:我们只需要找出描述某类关系的数据,而不是需要去实现或定义对这些数据进行操作的方法,这样就是的标准的定义根本不需要很复杂的组织结构,比如类似USD类多层级的结构。
标准也应该是可以自我进化的,标准的作者可以对标准中的符号进行新增、修改、重命名或者删除等,通过这种机制来实现标准的进化,形成更好的抽象,更好的标准。而动态编译的机制,以及标准更新通知机制,使得使用这些标准的用户或者组件可以得到通知,使得组件在程序中可以正常运行。最终真个系统或者说世界,向着优秀进化的能力是标准的自我进化,好的标准代表着优秀的事情,他会被更多的人使用,它是一个重要的指标
标准本身也是一个类型查找的依据,标准的设计应该围绕某一类主题,而不是泛泛的涉及多个无关内容的标准。这些也是普通用户进行创作时的组件筛选机制之一。
4.12.2 基于标准的商业模式
针对符号表的版权,类比指定标准,符号表标准本身比实现的组件是更高价值的东西
4.12.3 自我进化的标准
4.12.3.1 自我进化的核心机制
4.12.4 标准的自我进化
前者是指一个好的标准,有一定的机制被更多人发现,从而促进了标准的推广,这是一种维度的进化,因为这样好的东西会越来越被更多使用,从用户来看,这个世界变得越来越美好。
后者是指,促进标准本身的进化。即对于一个被广泛使用的标准,这个标准并不是100%完美的,它本身还有改进空间,它本身也可以延后
4.12.4.1 符号表的版本兼容性
4.12.4.2 以标准为中心的社区
订阅的机制
4.12.4.3 推动组件更新
参见4.11.3.4节,标准的更新机制(保持最新两个版本)使得标准能够快速进化以及牵引用户更新。
标准的这种版本机制还促进了组件更新,当标准更新了,可能不久之前,比如一个月或者半年的组件将有可能过时,这时候为了持续被其他新用户使用,它必须更细组件,否则新用户无法购买,这样就促进组件开发者快速更新。
如果是已经购买的用户,它可以反馈要求组件更新,这里面就有类似的机制刺激开发者:
- 组件购买是一次性的,所以开发者不用对过期负责
- 但是用户需要升级组件时,这是一次重新购买行为,对开发者来讲有 二次收入,当如开发者可以设置老用户优惠,甚至老用户免费升级,所以开发者有足够大的动力去做这件事情。
另外,从实际来讲,真实社会也是这个样子的:
- 你买的东西是容易过时的,你可能会重新购买相同产品的新品,比如手机
此外,对于软件来讲,更新很快,你不可能开发一个组件就用几年,这种陈年的老代码后面一定有兼容性问题,而且它不更新也代表着用户体验的还是很久之前的东西,当然这些东西也有可能经得起时间考验。但对于这种情况,有两种思路:
- 对于这种比较稳定的产品,其代码也趋向于稳定,开发者每次可能并不需要花费很多时间就可以更新升级一下组件
- 标准也趋向于稳定,每个标准都是一个进化的过程,到一定的阶段它也会趋于稳定
- 此外,标准开发者为了避免开发者流失,TA也要尽可能保证稳定,否则频繁变化的标准有可能会流失开发者
另外,对于传统的App来讲,比如有时候看到很多非常久的app没有更新升级也能运行,但是因为它是独立程序,只要OS保持一定的兼容时间即可,但是对于在一个应用程序内的开放大世界来讲,这个事情会复杂得多,所以前期使用更简单的方式处理。
4.13 用户创作
4.13.1 以组件为最小粒度
4.13.2 以标准为整体思维
4.13.3 反馈和评价
4.13.4 实体和组件管理
4.14 基于自然语言的交互
4.14.1 面向技术人员
ChatGPT早期的流量大部分来自技术人员,跟区块链一样,先由技术人员到非技术人员,借助现在的社交网络,现在的信息传播会更快
4.14.2 去中心化的AI
以ChatGPT为代表的大模型,是更加中心化的方式,过去分散在多个软件中的信息和功能,现在被集成到一个更加中心化的模型和公司中,使得单一公司对更广泛的能力拥有更强控制权, 因此信息安全会更加复杂。因为不管一个模型是否能够动态学习新知识的能力,还是说它的数据均来自分散的互联网,但最终面向用户的整个流程是通过大模型中的算子和程序进行计算的,这些输入信息不管是否真实准确,大模型的计算过程都可以对其进行修改,它掌握着信息的流动和分配,因此它可以控制信息的流动和分配。
因此,未来的AI应该是去中心化的,应该以某种用户可控的形式,更分散的形式,例如像RealityIS中,平台提供的是基础模块而不是模型,用户去选择模块。
未来的AI或许应该将自然语言的理解和问题的结果区分,当今的ChatGPT的成功在于它将自然语言的理解和信息的结果进行关联,这种关联一方面方便中心化的大模型进行学习处理,但也同时带来了风险。所以我们应该将获取结果部分的控制权交给用户,由用户来控制,可以有许多方式,例如RealityIS的方式。
4.14.2.1 信息的直接传递
从另一个角度,chatGPT影响了信息的传递,权威信息比如新闻、技术文章,最核心的原则肯定是直接传递,比如各大网站需要推出自己的官方网站或者信息源供用户直接消费。直接传递是保持信息真实性的唯一途径。
但是一旦信息的传播方式变得不是直接传递,这将会大大影响信息的传播,因为这些渠道可能会修改信息内容。即使是转摘,也很难辨别转发者做了哪些信息修改,除非你去看原文。
所以我们总是力求信息的直接传递,传递的媒介是报纸,报纸有出版社权威印刷厂经过权威渠道直接到达用户手中,一般很难篡改。而互联网底座的互联模型,也是尽可能保证这些底层机制不会篡改传输信息,并以标准的形式开放。
但是显然大公司的大模型作为一个信息传播渠道和方式,它无法有这样的保证。
5. RealityCoin
将过去传统游戏市场中,只有开发商、发行商和玩家参与的经济,扩展为其他人可以参与投资,通过投资来驱动游戏体验或应用程序功能获得更广泛的使用。
对于以太坊类似的去中心化平台,由于以太坊发行的代币跟实际运行的产业之间缺乏关联,本质上以太坊只保证交易的执行和合约的执行,但是这些交易和合约背后的实体及其实体的信用体系,仍然需要依赖于第三方机构,这些第三方机构大都是中心化的机构,比如:
- 交易对应的物体能不能按时送达
- 交易对应的真实世界的物权是否真实,甚至是否真有其权
- 交易背后的团队是否有能力执行代币的承诺,甚至谁来验证这个团队及其执行
由于RealityCoin只服务于Reality World平台上的应用,所以可以在代币和平台之间加入一些信用约定,用以保证代币的风险可控。并且,通过保证代币对应的产品确有其物,甚至可以避免一些证券监管问题。
这种代币经济和开发平台的现象,正开始为我们展示一个全新的、去中心化的未来经济。初创企业正主张计算机存储平台、拼车应用、太阳能发电、以及在线广告合约等在内的产业都会被去中心化并以代币的方式进行管理。
实际上,这些数字资产甚至可能会成为人类创造及交易价值的主要方式。
5.1 代币经济
5.1.1 促进前期产品成长
除了Reality World内部类似实体或者个体经济,这在前期没有产品知名度的时候,传统的做法就是靠运营,其实就是投放流量,或者就单纯需要靠产品的口碑。前者成本较高,而后者成功率较低。
区块链的逻辑,它不仅是一个安全的价值交易中介,它的架构体系中天生融入了投资的逻辑,比如它首先是发币,此时实物还没有生产出来或者产品处于前期运营期,产品知名度还没有那么高。此时就基于投资者对未来产品理念或者故事的预期,进行投资,例如代币就是这样;即使没有投资,实现分发的虚拟货币,也会让持币者为了使得所持货币增值,而会无形中参与帮助平台的推广。
因此,这一套逻辑背后,能够让早入局的人在以后获得更大的回报,基于对平台或者产品未来的预期或想象空间。因为如果基于投资者的预期,日后这些自己所持的虚拟货币或者代币,会获得较大的价值增值空间。因此带来的结果是在产品还没有知名度的时候,就可以吸引那些早期参与者,这帮助了前期的产品推广。并且越早参与的人获得的增值空间会越大,所以早期可以快速成长。
当然随着用户量增多,或者产品市场越成熟,这种增值空间就逐渐变小,但是产品的市场却已经稳定了,此时:
- 价值投资者会慢慢退出
- 但是产品开发者还是可以持续获得较大的收入
5.1.2 让玩家可以获得收入
传统的游戏玩家主要是付费获得体验,属于消费者。代币经济及系统可以让玩家可以很简单地参与对游戏的投资,还可以从中获得回报。
例如玩家在玩了某个游戏之后,觉得设计很好,就可以购买其成长代币,日后等游戏大热之后就可以回报增值回报。
当然由于玩家本身也付费,所以理论上玩家是不会赚钱的,这种模式是早期的玩家赚取后来加入玩家的钱,这也使得那些愿意投资的玩家更愿意去发现一些好的游戏,并且是处于早期的游戏,越是早期它们可能赚取的增值空间越大。
这就对整个新游戏的发展形成正向反馈。这些本身也是驱动整个系统自我进化的一个逻辑,因为那些不好玩的游戏,肯定投资的人就会更少。
这种把个体经济和代币经济结合起来,通过实际体验来获得对产品的感受,然后基于感受进行投资,这有点像风险投资过程中的产品尽调的过程。
5.2 验证和结算
区块链平台主要提供验证,可以在中心化平台提供结算,有平台信用保证对于结算物权的映射。实际上用户关心的是数据和自主的权利,这种映射本身也无法通过区块链保证,因为不能将整个应用内置于区块链内。
5.2.1 结算性能
怎样保证实时结算的性能
IOTA
5.3 智能合约
怎样让用户定义代币,以及代币交易的规则
5.4 数字化的物物交换与未来经济
所有代币之间都可以进行交易
Lykke
5.4.1 可编程货币
5.4.2 流动性
我们可以看到,几乎每一种新出现的加密数字币都和某个经济项目结合在一起,尽管很多项目经不起推敲,而借此项目发行的加密数字币被人们挖苦为 “空气币”,也就是骗钱的工具,但是这个经济模型的出发点是正面的,即每一个发币的区块链项目,都尝试以其所发行的通证(tioken)作为激励工具,促进参与各方积极协作。参与者对这个经济项目的贡献超大,得到的币越多。而随着项目发展成熟,得到市场越来越多的认可,币的价值也将水涨船高。 这就是一个理想的 token经济系統。换成现在时髦的术语-是一个token 经济生态圈。
换言之,如果加密数定而和裝和要为型地毛页的经滋行为结合在一起,其社会经济价值会更大,也更容易被接受,在经济脱虚向实的大环境下。更有助益。这类经济活动并不是没有,正如第3章讨论的知识贡献与分享的例子,类似应用场景还有很多。
区块链的一个根本能力是能够实现南流到华、快速交易、快速流转、登全可種的功能。我们可以设想一下,把各种权益证明比如门票、积分、合同、证书、点卡、证券、权限、资质等全部进个 通证化 (tokenization ),在区块链上流转,放到市场上交易,让市场自动确定其价格,同时在现实经济生活中可以消费、可以验证,这些都是紧贴实体经济的良性应用。 token 经济具有一个特点,就是各个经济生态圈的 token 都具有特定维度上的价值,在各自的圈子内是不可或缺的。作为一个开放的经济系统,圈内成员的进出会带来 token 的流动和交换,这就会导致出现类似不同货币之问兑换的情况。各种token 可以用法币标价,但都禁止法币直按替代各种币在所在的 token 经济生态圈内使用。 这种切断了法币进入token 经济生态圈,而将token 作为所在经济生态圈的“图币”的经济现象是值得探讨的。 试想一个这样的社会,法币不再是所有经济活动的货币媒介,社会经济生活被分成了多样化的很名公开放的圈子,每个圈子都有自己的经济活动,在特定范围内, 使用白己的“圈币”。但也有人 在这些经济活动之外,处于平常生 活 子,使用的是法币作为交
易媒介。每个人每时每刻都在不同的圈子间流动,在不同的圈子遊 循透明的规则,使用不同的 “圈币” ,相应也留下了可追溯和不可 篡改的活动记录(图 4.3)。 权益证明 合网 泟书 图 4.3 权益证明通证化 这或许是一个更加有序的社会形态。有了token,参与者、项 且建设者、产品,这此要素在特定经济生态國内有机地济动起来。进人園子的人越多,生广话动越昌盛,token就越有价街。大炎社会生活会出现白组织经济生态,token 可以方便、低成本地实现關 内的投票和表決。到目前为止,还从未有一个国家经历过这样一个 存在多种价值符号和多种价值尺度的社会,在这个社会中社会治理、国家管理、宏观经济等方面,都会出现前所未有的考验,很多经济和社会规则都会逐渐发生深刻的变化。
5.5 平台信用
平台信用主要是指两个层面:
- 区块链物权到平台资产的映射信用保证,例如组件,标准和作品
- 在投资者和创作用户之间建立一些类似公约的协议机制,保证投资者权益,以及建立一些节约无控制人管理和法律之间的,类似法律的约束
区块链本质上只能保证存入区块链的数据的不可篡改性,所以这里面就存在漏洞:
- 没有在区块链中的数据是无法保证信用的
而这样的数据是很多的,而且几乎不可能绝对保证所有数据都在区块链上,因为区块链的核心的分布式存储和计算,就导致人类信息几乎不可能将所有信息迁移至区块链,比如:
- 区块链上交易的数值虽然是绝对不可篡改的,但是其数值对应实物的映射关系则是需要第三方信用机构担保的,否则这些数据也是可能存在欺骗的,而实际上传统的商业欺诈中,数据账本本身作假可能反而是谨慎的,因为这部分比较容易被查出来,尤其现在本身数字化也比较多了,但是作假的往往都在于这些资产所标注的数字跟实际价值之间的映射关系,这却是最难管理的。
- 几乎大部分需要占用大量存储的数据很难存储在区块链,例如把你网盘的照片数据放到区块链,你承担得起这个成本吗
- 另外,计算程序也是一个信用问题的来源,如果你的计算不是在区块链上的,理论上说这也是容易出问题的,但是计算放在区块链几乎也是不现实的,比如你得把所有代码转化文区块链虚拟机的代码,另外是面临源代码开源的问题,以及同样的大规模计算性能的问题。
所以,绝对信用安全的区块链是:
- 所有数据都在区块链节点
- 所有逻辑计算都在区块链节点
- 资产原生就是数字资产,所以不涉及任何链外的关联和操作
RealityIS平台中的所有资源原生是数字资产,只要保证好区块链信息到数字资产的映射,就能更安全。
5.5.1 用户社区协议
5.5.2 代币协议
5.6 现实应用
通过模拟和跟踪真实世界的某些规律,来解决现实问题
5.7 社区治理与行为代币
5.7.1 玩家道德
发行代币,如果长时间没有被举报有不良社区行为的问题,就可以获得代币,通过利益来促进社会的风气。
5.7.2 社区共同开发
5.8 玩家参与的经济奖励
5.8.1 社交分享
由于社交分享是重要的一部分,可以让朋友之间的互动转换为RealityCoin奖励
5.8.2 参与内测
提交bug或者建议,获得开发商接受的可以获得代币奖励。
5.9 数字货币对平台的影响
传统的游戏中,游戏代币本身不会影响到游戏本身。
但是当代币形成一种更大范围的东西,他可能对游戏本身造成一定的影响,例如代币可能会贬值或者升值,这在传统游戏内是不会发生的。
这时候代币经济的一些根本性缺陷如:
- 价值不稳
- 公信力不强
- 可接受范围有限
- 容易产生较大的负外部性
它很难通过公众和市场的检验,从这个角度看,不管采用的技术有多先进,采用这类加密数字币作为“货币”,仍是走回头路,是回归一种落后的货币形态。
因此,为了避免这些缺点,需要:
- 像传统游戏一样,将货币属性控制在游戏或者平台内部
- 严格控制投机行为带来的影响
上述的理念实际上使我们在使用以区块链为很的去中心化的数字经济方面提出两个原则:
- 去中心化,是用来保证数据安全和个人隐式,是用户的客观需求
- 但货币的行为,更多是少数投机者的需求,而不是广大用户的需求,当然代币经济有一定的优势,所以我们将这部分控制在RealityIS平台内部,而不会像其他数字货币一样目标为通用的价值交换方式。
5.10 架构缺陷
5.10.1 不合理的激励体系
区块链公链,为了保证数据和计算安全,对节点给予了超额的激励,这包括:
- 挖矿产生的原始代币,并且这是代币的原生和唯一的发行方式
- 交易的手续费
由于节点数量庞大,以及节点需要持续维持下去,因此区块链节点的成本是极度高昂的,它远远超出了计算资源本身作为云计算基础设施的成本,它还在另外两个层面控制着这种高昂的激励:
- 节点是需要永久维持下去的,因此它是一个持续高昂成本
并且,节点虽然赚取了大量的激励,但是它们确实整个体系里最没有创造性的劳动付出,相对于那些比如:
- 维护平台迭代开发升级的开发者
- 以及那些真正创造劳动价值的生成者
这都是既不科学的,极不合理的,那些传统行业真正从事创造劳动和价值生成的从业者,它们本质上没有从区块链获得太多好处(除了哪些自带操作属性的NFT之类的创作)。
对于那些真正生成商品的生成者,TA的物品交易被迫使用数字货币进行结算,这就迫使他们去购买区块链原生数字货币,这在导致数字货币流通的同时,迫使这些人面临着数字货币的风险:
- 首先是他们的购买数字货币的本身就承担了早期以及数字货币增值造成的溢价成本
- 另外是,由于这种溢价的风险,他们掌握的数字货币面临着贬值的风险
而这种风险几乎是绝对存在的,因为数字货币总体上并不是跟经济生成挂钩的,比如:
- 很多交易的额度很低,但是它们几乎占据一样的计算资源
- 很多交易存在大量的投机行为
这些投机行为与真实经济行为混在一起,使得整个经济生态极不合理,导致极不稳定,风险极大。
大家都在将区块链的好处,很少有人会去揭示这些风险,也很少有参与者真正了解这些风险。
5.10.2 高风险高回报
当然对于矿工和ICO的早期参与者,因为他们的投入是可能没有任何回报的,因此早期面临着极大的风险,肯定是需要比正常更大一些的经济回报作为代价,否则他们就不会冒这个风险。
这也是一种激励类似创业的机制。他们的早期行为从某种程度上说类似参与创业。
6. Applications
每个产品要思考3D带来的价值增益,而不是简单把东西搬到3D或XR
1、生日墙
好友A用AR手机或眼镜找一块墙面进行创作,其中可以把背景图色,纯色或某种pattern,然后在墙上设置装饰和定制祝福,其中某些元素包含一些交互;最后将结果发给好友B,好友B找一个立面或者纯虚拟的方式就可以3D查看,如果是立面,也根据语义识别,将背景墙换色
可以点击交互有生日相关的流程,例如点蜡烛,出现特效,唱生日歌,现实特定的信息,好友一起围观等等
2、二维墙面涂鸦类创作
随便找一块空地地面,从地面拉一个垂直面,就可以进行墙面艺术创作
有交互的涂鸦
3、3D脱口秀
4,移动的灵感氛围


可能包含移动拼图,包含拨一定的顺序点亮按钮,所以需要包含一些特定玩法类型的数据结构
6、知识讲解类会很多
一个模型,有些交互点击展示,普通人可以制作,不只是官方制作少量
7、虚拟房间
比如现在的虚拟聊天类场景,一般都是官方提供的少数固定场景,或者允许一定的定制性,但是通常定制能力有限,比如几何是固定的,只允许改材质,或者只允许增减部件,或者移动位置
在RealityWorld 里用户也可以创建更加丰富多样的聊天环境,然后邀请用户进来聊天
8、个人收藏馆
有一个自己的房间或者特定的场景,可以是自己设计的,有自己的收藏,可以加入一些自己的玩法,好友参观可以赠送Creation, Part
9、去一个浪漫的Creation 中约会
creation.id/=qwe&session=sessionid
10, 基于现实的创作
现实提供粗略的几何与参考材质,在此基础上进行创作
11、

12、连续剧,整个开发周期均可发布
把游戏关卡或者故事一点一点更新,每次玩家玩一小段,像连续剧一样,甚至世界都是一点一点构建;或者有点观看创作过程,过去整个游戏需要一次性做完再走发布流程,这种可以实时把中间创作过程共享出来,可以反馈,主要解决的是中间任何状态都可以发布,而不是要留到最后只做完了再去处理发布相关的事情,这些事情导致不能提前发布,这实际上是一种流程上的创新,带来全新的模式
13、story telling

*Like a well-executed joke, the pleasure is in the experience more than it is in the retelling. You have to be there.
Super Brothers 开创了一种叙事+交互的非常优秀的体验,相对于单纯游戏,他的故事线让整个世界观呈现更完整,相对于电影,他的交互可以让故事的体验更真实
创作部分涉及的内容基本上均可以实现
故事的元素:
- 环境,物理环境通常是静态的,但一些重要物品通常是动态的
- 信息,需要探索不同的地方了解信息
- 交互,对信息的探索是一种交互,其他比如解密,开动机关等等
- 世界状态
14、互动小说/故事
在传统小说的基础上,2D+3D,先文字介绍基本剧情和背景,然后进去3D场景,具有沉浸感,而且因为前面的文字剧情,对场景的探索会更融入,然后条件是需要在3D场景中完成一定的任务才能进入下一章,把游戏的机制融入进来,游戏结合文字剧情,弥补了纯游戏探索需要话费大量时间,并且剧情比较零碎的感觉
7. 核心参考架构
本文介绍对Reality World有影响或者可以参考的技术架构,通过分析他们的技术原理,识别其背后的技术架构,以及其特定技术架构蕴藏着的对开发者或者用户生态的影响。对于每一个技术方案,也会分析其优缺点,以及Reality World应该怎样吸收这些优点,最重要的,我们应该从这些架构中得到什么更深层次的、有价值的信息以帮助Reality World构建更好的技术架构和技术方案。
每个参考架构按如下的格式进行描述:
- 新思想:相对传统技术方案,该技术方案该来什么新思想或新思路
- 技术方案:对相关的核心技术架构进行表述
- 不足及原因:在Reality World的方向上,该技术方案没有解决什么问题,或者无法解决什么问题;其中的原因是因为技术方案的不足,还是产品定位和方向的问题
- 对比:Reality World与其对比存在哪些差异,或者说Reality World通过什么样的技术方案来解决这些问题
7.1 数据格式
7.1.1 USD

Universal Scene Description (USD) is the first publicly available software that addresses the need to robustly and scalably interchange and augment arbitrary 3D scenes that may be** composed **from many elemental assets.
7.1.1.1 新思想
- 协作:USD是一个为了大规模协作的高性能可扩展软件平台
- 交换:USD提供了在多个DCC工具之间进行交换的格式,这通过内置的一些schema实现,包括geometry,shading,lighting和physics等
- 合成:USD独特的合成特性提供了强大的收益,比如能够将丰富多样的individual asset合成到一个大场景,这允许多人同步协作(而不会导致冲突)
USD的合成引擎对任何特定的domain是无感知的(agnostic),所以它可以被扩展来编码(encode)与合成其他domain。
7.1.1.2 技术方案
Schema
Schema用于从UsdObject编辑、查询和定义结构化的数据(structured data),大部分核心库中的Schema是prim schemas,这又分为两类:1)IsA Schemas;2)API Schemas;3)另外还有一些Schema称为property schemas。
一个prim可以订阅多个API Schema,但是只能订阅一个IsA Schema,USD提供了工具用于生成Schema的代码。
IsA Schema
IsA Schema用于定义一个prim在Stage中的角色或者目的,它继承自UsdTyped类,并可以指定typeName metadata,例如:
UsdPrim::IsA<SomeSchemaClass>()
IsA Schema可以是实的或者虚的,例如UsdGeomImageeable是虚的IsA Schema,而UsdGeomMesh是实的IsA Schema,因为它包含一个Define()方面可以定义typeName。
API Schema
API Schema是prim的Schema,它们用于提供接口(API)对prim相关的数据进行定义、编辑和提取。它继承自UsdAPISchemaBase类而不是UsdTyped,因此相对于“is a”可以称为“has a”。API Schema有三类:
- Non-applied API Schemas
- Single and Multiple Apply Schemas
- Multiple-apply schemas
Model, component and Assembly
Kind是一个prim-level的类型系统,它相对于schema type抽象层级更高,对应于Model Hierarchy:
- model,kind的抽象基类
- group
- assembly
- component
- subcomponenet
相对于更细碎的asset或者prim,model提供一种将场景结构进行细分的架构;model结构也提供了更好的方式管理和引用资源,否则对更对referenced assets引用和推理会变得复杂。
def Xform "TreeSpruce" (
kind = "component"
)
{
# Geometry and shading prims that define a Spruce tree...
def "Cone_1" (
kind = "subcomponent"
references = @Cones/PineConeA.usd@
)
{
}
}
Asset AssetInfo and Asset Resolution
Asset是能够使用一个字符串标志符(via asset resolution)被识别和定位的资源,asset可以是一个文件,或者多个文件组合引用形成的单个文件,它一般有版本控制,为了方便一些如asset dependency analysis等操作,USD定义了一个特殊的字符串类型,asset(represents a resolvable path to another asset),这样所有的metadata和attributes都能被很快地定位和识别。
尽管USD的composition arcs能够用来合成场景,但是他们并不方便在内存中对资源进行定位和识别,AssetInfo是composition arcs的补充:
def Xform "Forest_set" (
assetInfo = {
asset identifier = @Forest_set/usd/Forest_set.usd@
string name = "Forest_set"
}
kind = "assembly"
)
{
# Possibly deep namespace hierarchy of prims, with references to other assets
}
Asset Resolution是将一个asset path转换为可以定位一个资源的location的过程,默认按照文件路径进行搜索,但是开发者可以自定义定位逻辑,甚至资源不一定需要存储在磁盘中。
Prim, Property and Attribute
USD的命名空间主要由:Prim和Property组成,其中Prim提供对合成场景的组织和索引,它是USD的主要容器,prim可以包含另一个prim,形成一个namespace hierarchy Stage;
Prim,连同它的indices,是Stage中唯一被持久化存储在内存中的数据;对prim进行操作的接口由UsdPrim类提供;prim可以拥有一个schema typename,也可以提供如scene-level instancing, load/unload behavior, and deactivation等操作。
而Property提供real data。有两种类型的Property:
- Attribute
- Relationship
Property可以被组成新的层级且不需要引入新的Prim,这可以提升内存的局部性:
#usda 1.0
over MyMesh
{
rel material:binding = </ModelRoot/Materials/MetalMaterial>
color3f[] primvars:displayColor = [ (.4, .2, .6) ]
}
Attribute:
def Sphere "BigBall"
{
double radius = 100
double radius.timeSamples = {
1: 100,
24: 500,
}
}
7.1.1.3 USDZ
USD的核心是方便对众多分散的资源进行合成,其中资源已分散的碎片形式分布,这种机制是为了编辑态设计的,此时整个场景还没有编辑完成,需要继续维持这种分散的状态;然而当我们的内容全部编辑完成时,分散的文件却不便于管理,此时的核心需求是分发,它要求一下特征:
- A single object, from marshaling and transmission perspectives
- Potentially streamable
- Usable without unpacking to a filesystem
USDZ通过USD提供的FileFormat plugin机制实现:UsdUsdzFileFormat
7.1.1.4 不足与原因
USD主要聚焦于怎样对合成的场景进行编辑和提取,因此它偏向于“low-memory footprint, higher-latency data access” 而不是 “high-memory footprint, low-latency access to data”,因为在内存中缓存更多数据,会影响对基于合成结构场景的编辑和提取,带来复杂性,因为在编辑阶段会有更多的数据修改,而运行时阶段则基本上保持数据不变。所以USD不太适合运行时。但是USD提供了一些便利和工具(facilities),使得客户端可以对UsdStage构建一些扩展性的缓存,以提供对USD数据的低延时访问。
USDZ从分发的角度对USD进行了增强。
另一方面,USD主要是为了在DCC之间进行数据交换和协同,这全是编辑时的需求,有很多功能本身对运行时没有任何用处,例如由大量的碎片组合形成的大型场景虽然适合编辑时,但是却不利于运行时加载,所以需要在运行时对USD进行一定的定制,例如是否从Core中删除一些模块,或者去掉一些功能。
数字内容的生命周期:
- 编辑(USD
- 分发(USDZ
- 运行时(USDX)
需要在USDZ基础上进行运行时改造,使其分发得是适合运行态得格式,所以可以隐藏分发态,只需要编辑和运行时两个形态;
同时为了保证继续编辑,需要将编辑态和运行态区分,但是
7.1.1.5 对比
- USD太过复杂,有很多额外的属性都是为了合成场景的目的,而合成场景并不是运行时需要的,或者说一旦到了运行时,有些合成属性已经固定了,我们便不再需要那么复杂的属性,例如至少不再需要单一场景(一个微型app)内部所有合成属性,那么该微型场景就应该转化为固定格式场景,而整个合成能力保持在微型场景层面就可以
- 且对运行时不太友好,有很多属性,跟上面一样,有很多不必要的合成细节在运行时执行,这部分要去掉
针对上述特性,有必要开发一个中间格式:
- 它在开发者保存场景至RW时执行预处理,其计算过程主要是提前计算一些合成方面的计算
- 最终运行时直接加载该格式
- DSL针对该格式就行优化
- 针对每个微型场景,开发者本地会保存原始USD文件,下次他仍然对原始文件进行编辑,然后提交时进行预处理,再保存中间格式至云端内容服务器
兼容第三方,在第三方做插件,转化为RW支持的格式,然后在RW做场景和交互编辑
然而怎么实时多人协同修改,另外用户开发微型场景大部分都是在端侧运行时进行
具有对用户可读的表述形式,和对程序高效加载的二进制形式
7.1.2 Alembic formats
7.1.3 Unity Prefabs
7.1.4 代码生成
USD中的Schema和LLVM中的TableGen,都是按照一种文本格式,定义一种格式,然后生成对应的C++代码。
def Toy_Dialect : Dialect {
let summary = "Toy IR Dialect"; let description = [{
This is a much longer description of the
Toy dialect.
...
}];
// The namespace of our dialect.
let name = "toy";
// The C++ namespace that the dialect class // definition resides in.
let cppNamespace = "toy";
}
生成的C++代码:
class ToyDialect : public mlir::Dialect {
public:
ToyDialect(mlir::MLIRContext *context)
: mlir::Dialect("toy", context,
mlir::TypeID::get<ToyDialect>()) {
initialize();
}
static llvm::StringRef getDialectNamespace() {
return "toy";
}
void initialize()
7.2 数据驱动架构
7.2.1 Unity DOTS/ECS
传统的DOTS或者ECS还是仅关注性能层面,但是数据驱动的好处是它让开发者把逻辑区分了出来,所以在这些逻辑的组织层面再加上一层管理,就可以向上层用户层进一步简化逻辑开发
SRP Batcher把材质数据从原来的raw data里面抽取出来,这样就能:
- 让GameObject rendering的性能随着scriptable pupeline得到提升
- GPU中可以缓存材质数据,而不需要每次都切换shader,因为draw call提交的频率远高于材质数据切换和提交的频率
System 对component 的引用比较复杂,Unity为了简化以及不改变原来的代码,让开发者实现一个原来的Component 类,然后自动拆分,这样也许会使得用户不易于彻底使用数据驱动的思想,另一种是通过一个特殊的语法糖包装引用,然后编译器自动将引用转化为通过Component 复制,而不是对象引用
用户不应该关注并行计算:
Unity的EntityQuery似乎可以按上述的思路去优化,甚至并行计算的显示调用都是隐藏的,用户不应该关注并行,用户对单个System 的执行自动转变为并行,包括实际的查询和并行执行,只需要每个system必须在头部引用Components 即可(声明包括是否只读的使用说明):
- 这个引用声明跟传统的编程类似
- 编译器可以根据这个引用建立archetype
- 编译器根据这个执行自动查询
- 编译器根据这个执行自动并行计算
- 可以通过设定逻辑类型和几何或者外观类型之间的约束和对应关系来控制新类型的创建,但是这些仅发生在编译期间
太极的Megakernel programming 有这样的思想,将传统element-wise的编程,多个计算阶段合并为一个single kernel ,编程理解更自然
一开始就要教会用户,怎样基于逻辑或者功能组合来创建,这些都是基本规律和逻辑,设计的时候要考虑高度通用性、抽象性、逻辑性,这样用户理解成本最低,而在设计的时候构思的成本也最低,以及逻辑之间的关系,这其实是本质:
- 构建子逻辑及其类型
- 以及逻辑之间的关系
- 几何与外观的类型
- 几何外观及其类型与逻辑之间的关系
- 然后有一套框架来支撑这个体系
Unity的DOTS做的还不够彻底,它还是为了兼容原来的Component,依赖于编辑器属性把Component和System分离出来,数据和逻辑之间的关联、关系和区别都没有那么明显,不利于深入贯彻数据驱动这一理念
在RW中,所有逻辑和数据必须分开,它们没有办法混到一起,但你可以选择不将组件发布,变成private的,但软件架构一样,并且遵循同样的包管理,中心化的组件管理和加载,版本管理,只是组件不对外公开而已
其中一种让多个开发者遵循公共协定的方法,是由平台来定义数据,平台定义的是一些业务数据,这些数据成为公共接口,多个组件之间就可以相互独立工作;如果平台缺乏某些类型公共接口,开发者也可以自行定义,但是开发者需要选择哪些属性是公共接口,然后其他开发者可以基于这些公共接口开发,这些公共数据接口跟与特定方法相关的数据接口分开
数据驱动的重要性:
- 代码可以重用,所以有机会将一部开发者写的代码共享给其他人
- 将代码从数据剥离出来,才可以做到普通用户能够构建丰富的功能
原则:
Composition over inheritance
虽然ECS相较传统面向对象概念没那么直观,但是OOP及其继承的方式带来的逻辑上的复杂性和可维护性,ECS其实更简化了,它简化的原因是两个:
- 问题分而治之
- 逻辑层次更扁平,组织复杂性降低
开源ECS实现:Flecs
ECS是实现in-game editor的核心
数据驱动也要支持网络服务相关的功能
协议由官方来定义,开发者实现功能,但这种机制会开放给开发者,使得开发者可以在内部实现协议定义,然后通过私仓或者代码文件分享给别人,前者最好,然后优秀的协议专为公共的
7.2.2 ECS
缺点:
- 共享组件:包含关系和处理顺序,这些概念促进耦合
- 跨系统通信:两个独立的组件间需要通信
ECS game engine design
用户感知的应该只有Component ,他不需要知道有个System,Component 的设计原则应该是一个功能节点,Node,像Houdini 中的节点一样:
- 这个节点告诉用户该节点为目标物体添加了什么功能
- 这个功能应该用一个语义上的名字描述,一定要起一个很好的名字,官方要保留一些常见功能的名字列表,有一个总的名字列表,不能开发者随意起名字,除非是他内部私有的节点
- 需要构建一个全局的功能节点列表可以在文档中红用户选择和查询,普通用户真正使用的是公共列表中的功能节点,官方约定和维护其中名字和数据结构定义
- 开发者可以提交新的节点可以,但需要提交经过官方审核,审核数据规范,跟其他节点之间的兼容性,例如某些类型的节点不适合于某些类型的物体
- 理论上一个节点定义只能有一个System ,但是System 之间的实现差异很大,尤其性能差异,可以通过一些性能测试方法选择其中最优的版本为默认版本,最好不要让用户选择版本,哪怕是随机选择一个版本也要,例如提交的时候,可以要求开发者提供性能测试结果,所以节点的实现要定义一套好的仿真测试工具和框架
- 一定不要通过用户去查看其中的数据才能理解节点的含义
- 当需要修改参数的时候才会去打开节点的参数
这其实和苹果的USDZ的思想类似,只不过苹果只定义了少量节点,我们可以通过定义几百种节点实现很丰富的功能
- Houdini 有几百种
- Fornite 也有100多种
通用引擎不会这么做,只有in-house或者堡垒之夜这种沙盒游戏会这么做
7.2.3 UE5 MASS
7.2.4 Data-oriented and -driven
https://www.dataorienteddesign.com
Data Oriented Programming unlearning objects (book)
7.2.5 Rust ECS
https://specs.amethyst.rs/docs/tutorials/
7.3 编译器与DSL
RW底层需要极高的性能来支撑上层复杂的图形和逻辑计算,同时这种性能优化又要同时对跨平台移植性和开发效率带来好处,所以它不是单纯的性能优化,是一套高度优良的底层框架,具体之前一下几个重要方面:
- 图形管线的深度定制
- 针对数据驱动的优化,数据驱动除了让普通用户能够使用逻辑,还要通过数据驱动来简化开发者逻辑的开发,例如只要按照某种数据结构,不仅能使流程更简单,还会是的底层编译时和运行时能够针对这些数据结构进行优化
- 脚本语言的深入定制,跟上面的数据驱动相结合,用户起来极其简单
7.3.1 Taichi
Born from the MIT CSAIL lab, Taichi was designed to facilitate computer graphics researchers' everyday life, by helping them quickly implement visual computing and physics simulation algorithms that are executable on GPU. The path Taichi took was an innovative one: Taichi is embedded in Python and uses modern just-in-time (JIT) frameworks (for example LLVM, SPIR-V) to offload the Python source code to native GPU or CPU instructions, offering the performance at both development time and runtime.
7.3.1.1 新思想
Taichi是一门面向物理模拟和计算机视觉计算的领域特定语言,相对于传统使用C++等语言自行实现的算法,taichi提供一下方面的改进:
提供了并行计算抽象,使得开发人员不需要特别进行并行计算管理,并且具有较好的一致性
简化了代码复杂度性,主要是两个方面,一个是因为不用关心并行计算,开发者专注于单个Kernel,省掉了一定的复杂度,同时逻辑更清晰;另一个是通过将数据和算法分离,使得像稀疏结构这样的算法被自动优化,使得开发者不需要为了性能编写很多复杂的代码,例如对数据结构进行复杂的管理和排布
高性能,通过编译器进行了大量针对特定算法的优化,因此性能提升比较大,但比较局限于一些特定的算法,因为这些优化正式针对这些特定算法的数据结构或者形式进行优化的
即时编译,Taichi提供即时编译和预编译两种方案,其中针对即时编译,由于能够知道一些运行时的信息,因此Taichi提供了更多的优化
跨平台部署,将上层算法全部转换为统一的中间表述,有利于跨平台部署,这也减轻了开发者针对多个平台进行适配的痛苦过程
其他方面:
- Academia,学术界的研究实现中,往往因为缺乏优化,临时的实现方案,往往导致很难复用,Taichi希望改变这个局面,一方面通过优化的底层技术支持,一方面提供统一的接口
- Apps & game engine integration,由于统一的中间表述,使得Taichi容易跨平台,Taichi可以编译一些跨平台的库供其他平台调用,例如Taichi的AOT(Ahead of time)模块可以构建并保存在computer shaders,这样可以被其他运行时调用,AOT和JIT是两种模式
- General-purpose computing,虽然早期面向特定的目标如物理模拟,但是也会有更多的通用计算支持,例如TaichiSLAM
- Maybe a new frontend,可以将Python改为其他前端
7.3.1.2 技术方案
以下为Taichi语言的核心技术架构:
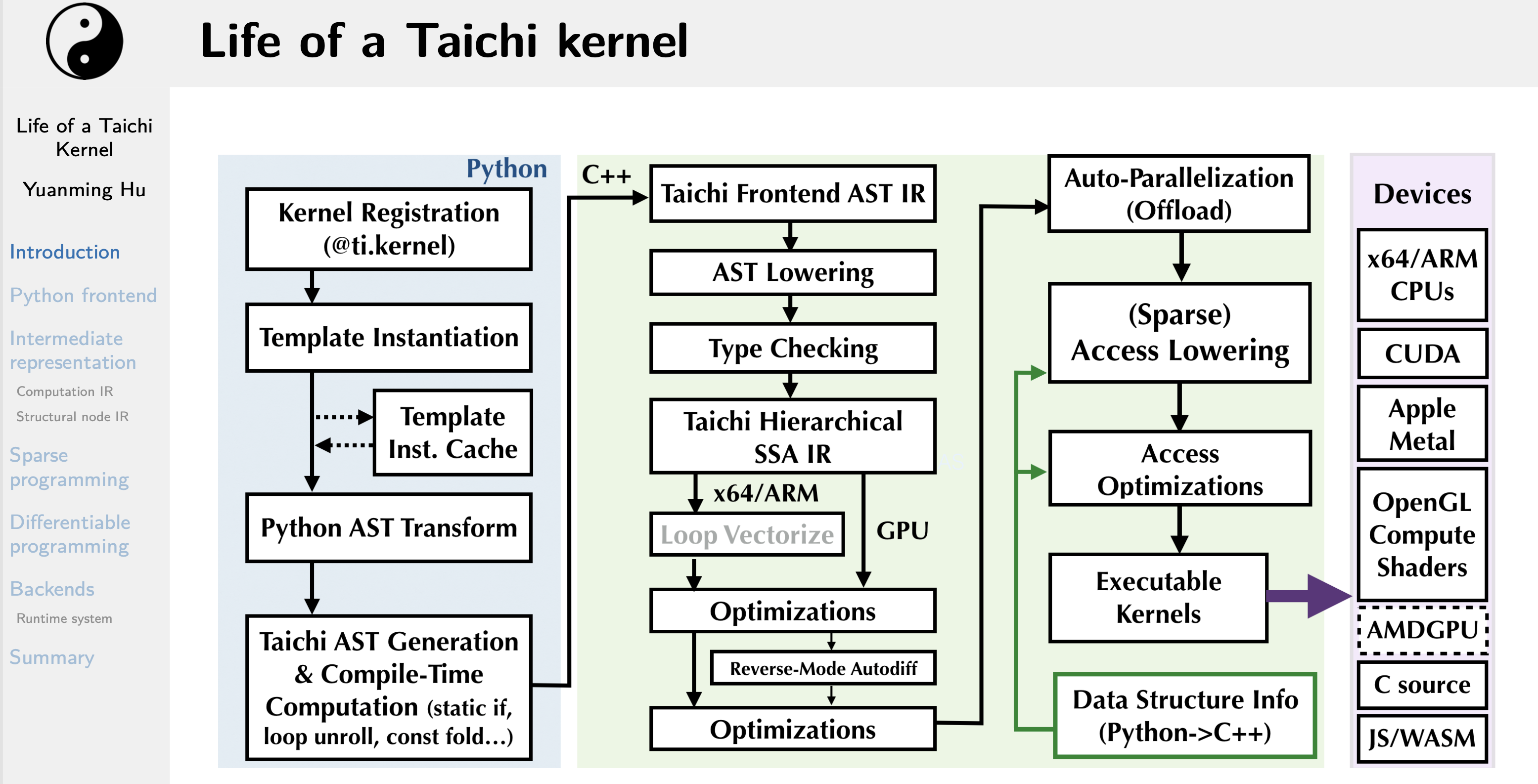
Taichi的核心是一个编译器(compiler),在这个编译器中,它针对特定的一些计算任务,如物理模拟,稀疏结构,以及向量化的类型等进行优化,通过修改和调整这些数据结构的内容布局,使得这些计算的缓存局部性更好,同时也通过向量化的数据类型系统,使得应用的内存占用更小,从而也减少内存对带宽的占用,不仅提高了计算效率,也减少了内存占用。
为了实现上述的目的,Taichi在前端语言中(目前是Python),通过元编程定义了特定的类型,例如:
import taichi as ti
ti.init(arch=ti.gpu)
n = 320
pixels = ti.field(dtype=float, shape=(n * 2, n))
@ti.func
def complex_sqr(z):
return ti.Vector([z[0]**2 - z[1]**2, z[1] * z[0] * 2])
@ti.kernel
def paint(t: float):
for i, j in pixels: # Parallelized over all pixels
c = ti.Vector([-0.8, ti.cos(t) * 0.2])
z = ti.Vector([i / n - 1, j / n - 0.5]) * 2
iterations = 0
while z.norm() < 20 and iterations < 50:
z = complex_sqr(z) + c
iterations += 1
pixels[i, j] = 1 - iterations * 0.02
gui = ti.GUI("Julia Set", res=(n * 2, n))
i = 0
while gui.running:
paint(i * 0.03)
gui.set_image(pixels)
gui.show()
i = i + 1
这些自定义类型构成Taichi语言,它们借助Python的AST控制能力,生成带来Taichi类型信息的中间语言,然后底层的编译器就可以根据这些类型信息进行特定的代码优化和调整。
其中,相对于传统的编译优化过程,Taichi更是针对例如稀疏结构等特定的计算进行了大量的代码调整,生成相对于前端数倍的代码,这个过程不但减少了上层语言的代码量,还对其数据结构及内存排布做了大量的调整,以提升计算性能。
实现上述能力的其中最重要的思路是数据驱动,它将一些特定算法的数据表述从算法指令当中分离出来,从而使得编译器能够对这些数据进行修改,已生成更加优化的数据结构及内存排布。当然,这样的上下文知识必须针对特定的算法,并不是对所有算法都能实现优化。
7.3.1.3 不足及原因
相对于Reality World的产品方向,Taichi存在两个方面的不足:
面向算法而不是逻辑,尽管Taichi可以减少代码量,但是它的核心是面向特定算法结构的优化,它不涉及逻辑层面的考虑,例如怎么帮助开发者实现交互逻辑;
不支持动态创建
Taichi最大的问题在于,它的底层优化特别重,这也是实现性能提升的关键,而这一层优化实现于C++中,因此Taichi的运行时程序只能是两种情况之一:
- 是运行时带上Taichi的编译器,这种情况可以支持任意的算法修改,这也是PC上的一般模式
- 如果运行时没有Taichi的编译环境,需要提前将Taichi程序编译,那么这个程序一旦部署就不能修改
第一种模式是比较慢的,因为运行时需要即时编译,并且Taichi的编译过程相对于一般的程序编译要更加复杂,因此这种模式不适合实时的游戏引擎系统;而对于第二种模式,由于算法被编译为固定的底层机器语言,因此程序不能再被动态修改,除非Taichi将所有的解释过程上移至脚本语言(Python)这一层,但尽管如此,虽然能够支持动态程序,但是上层的解释过程仍然非常复杂。
Reality World解决上述问题的方法是只提供脚本语言层面的优化或者解释,而为了保持性能,RW不会进行任何底层的特定优化,同时因为RW要保持计算的通用性,以及它的目标是面向逻辑结构,所以没有必要去做这一层,只需要通过脚本语言层的DSL使得开发过程足够简单就行,RW的架构更像Unity DOTS。
一些Reality Create的内置固定算法适合用Taichi编译吗?
Taichi的另外一个问题在于,它的编译是跟算法数据结构相关的,例如分配的列表是5个还是10个元素,这些都会跟编译器耦合,它是一个与数据有关的优化,而不是一个只与抽象结构有关的优化,或者这些数值即使不是来源于运行时,也是与类型的定义有关,所以本质上它只适合与固定的算法实现。
7.3.1.4 对比
| Taichi | Creation Script | |
|---|---|---|
| 目标 | 面向底层算法 | 面向上层语义、功能、逻辑 |
| 编译类型 | C++侧 | 脚本侧 |
| 优化算法 | 针对特定算法深度优化,例如针对稀疏结构,以及向量化进行深度的优化 | 仅针对开发复杂的进行一定的优化,例如简化并行计算,引入一些快捷变量,一些边界限制等 |
7.3.2 Modular AI
7.3.2.1 新思想
我们需要下一代编译器和编程语言来帮助解决这种碎片化
- 首先,计算机行业需要更好的硬件抽象,硬件抽象是允许软件创新的方式,不需要让每种不同设备变得过于专用化。
- 其次,我们需要支持异构计算,因为要在一个混合计算矩阵里做矩阵乘法、解码JPEG、非结构化计算等等。然后,还需要适用专门领域的语言,以及普通人也可以用的编程模型。
- 最后,我们也需要具备高质量、高可靠性和高延展性的架构。
在GCC之前,每家公司都要开发自己的:前端->优化器->后端,每家公司通常只开发一种前端和一种后端,导致碎片化;GCC将三者分离,减少了碎片化;
LVVM是一系列库的组合,它的模块性凸显了接口和组件的重要性,Key insight:Compilers as libraries,not an app
- Enable embedding in other applications
- Mix and match components
- No hard coded lowering pipeline
此外,LLVM还让JIT编译(即时编译)能有更多作为。虽然JIT编译器已经是一种著名的技术,但它一开始是用在其他地方。有了LLVM以后,芯片设计、HLS工具、图形处理、都更加便捷,还促进了CUDA和GPGPU的诞生,这些都是很了不起的成就。但更重要的的是,LLVM整合了的碎片化。LLVM出现之前有很多种JIT编译器框架,但LLVM的存在,提升了JIT编译器的基线,让它迸发出更多可能,也让行业可以实现更高层次的创新。
LLVM的主要缺点是不太适合做并行处理优化。
加速器是什么?可以把它高度简化成两个部分:
- 第一个是并行计算单元。因为硅本身的结构也是并行的,加速器要用到许多晶体管,也就需要很多硅来达成这种并行处理能力。
- 第二个部分起控制作用。它的名字不太统一,有人叫它“控制处理器(Control Processor)”,有人叫它“序列器(Sequencer)”。有人希望它小一点,所以会做状态机然后嵌入寄存器。这个部分基本上起到编排并行计算单元的作用。如果并行计算单元是一个大型矩阵乘法单元,控制处理器就会命令它执行一些宏操作,例如从这个内存区加载、执行某一操作、执行另一操作、更新SRAM等。
还有一些加速器很不一样,所以控制逻辑和计算之间的比率也各有不同。正如Patterson和Hennessy所说那样,你可以选择不同的点,但每个点都需要一定程度的编排。但人们常常忘记其他一些相关的工作,比如,你不止需要编排,还要解决启动问题,比如电源管理,还要不断调试排错。如果你想做得尽善尽美,可以对这些部件进行编程;如果你希望简单一点,可以把这些部件做得很小。
当控制处理器和并行计算单元都齐备之后,怎么给它们输入和输出信息?这时就需要一个内存接口。根据抽象等级的不同,这个内存接口可以是小型的block,也可以是支持物联网的芯片,这样加速器就可以和该芯片连接整个网络通信了。这里需要用到像AMBA或类似的技术。
你可以在更大的粒度(granularity)上构建整个 ASIC,所有的 ASIC 都在加速,在这种情况下,你可能正在与 PCI 通信,并且正在芯片外直接访问内存,但这种“我有一个控制处理器,有一个计算单元和有一个内存接口”的模型,是构建这些东西的一种非常标准的方法。
因此,我的主张是创新编程模型,发展新的应用程序,通过不断创新推动行业向前发展。我们应该对此过程所需的一切实行标准化,通过标准化能够快速完成工作,然后就可以把时间花在真正重要的事情上。
现在有一种相对较新的编译器技术MLIR可以帮上忙。你可以把MLIR看作是一个元编译器,它允许你非常快速地构建加速器/编译器。MLIR的全称是“多级中间表示”,它支持构建分层编译器,并以适用专门领域的方式构建,同时保留领域的复杂性。然后,使用MLIR提供的大量库和例程来做一些事情,比如,用多面体编译器来做循环展开和循环融合等等。
现在,我们开始看到的是,MLIR开始统一异构计算的世界,这也是我希望看到的。所有的大公司现在都在不同程度地使用MLIR,我认为,建立在RISC-V之上的MLIR很有必要,因为一旦开始从下往上整合行业,就可以开始把越来越多的层(layer)拉到一起,重复使用更多的技术。这使得我们可以专注在堆栈中更有趣的部分,而不是一遍又一遍地重新发明轮子。
也许你不会感到惊讶,但我认为答案是编译器,这是真正要走的一条路。
作为编译器编程语言从业者,我认为硬件设计这个领域已经到了重新评估的地步。整个领域是建立在两种技术之上,但实际上主要是一种叫做Verilog的技术,你大概率可能不喜欢Verilog。它有一个非常复杂的标准,当我看它时,不知道它是被设计成一个IR,也即一个不同工具之间的中间表示,还是被设计成让人们直接书写的东西。我认为,它在这两方面都很失败,它真的很难使用,对工具来说也很难生成。
此外,EDA工具、硬件设计工具已经非常成熟,它们非常标准化,有很多大公司正在推动和开发这些工具。但他们的创新速度并不快,设计时并不注重可用性。它们比加速器编译器要差得多,绝对不是以软件架构的最佳实践来构建的,而且成本也非常高。因此,这个领域有巨大的创新机会。
我不是第一个认识到这一点的人。在开源社区,已经构建了一堆工具推动行业向前发展。这些工具非常棒,比如Verilator被广泛使用,Yosys是另一个非常棒的工具,它有很好的定理证明器(Theorem Prover)。
我的担忧在于,这些工具的理想目标是试图像专有工具一样好,而我并不真的认为专有工具有那么好。另外,这些工具的设计者并没有合作。每个工具都在遵循单一僵化的方法,没有实现大程度的模块化或重复使用,可以从其中一些工具中得到网络列表,用它来解析一些Verilog之类的东西。但是,它不是由基于库的设计构建,与LLVM之类的东西不一样。
要创建在语法上正确,并且能表达你想要的东西的Verilog非常困难。此外,因为许多与Verilog有关的工具都有点奇怪,而且很难高质量地预测。生成与工具兼容的Verilog是每个前端工具都必须重新发明的一门黑科技。因此,在堆栈中真的缺失了一种组件,这个组件允许人们在编程模型水平上进行创新,并允许人们找到方法让所有工具都接受它。
有一个叫CIRCT的新开源项目正试图解决这个问题。CIRCT的全称是"Circuit IR for Compilers and Tools(编译器和工具的Circuit IR)",它构建在MLIR和LLVM之上。CIRCT社区的目的是提升整个硬件设计世界,促进编程模型的创新,并启用一套新的模块化硬件设计工具。它确实运用了很多我们到目前为止一直在讨论的基于库的技术。
此外,它提供了一个可组合的基于库的工具链,可以建立有趣的新的弹性接口连接,你可以建立Chisel社区正在探索的新编程模型,用它来加速Chisel流程。它带来了很多好处,可以让很多人一起工作,推动不同方式的创新。我们正在建立一个真正伟大的小世界,让关心硬件编译器的人在一起工作,这很有趣。这项工作仍处于早期,目标是更快地构建加速器,让加速器变得更快。
- Modular,
- composable &
- layered architecture is what the world of AI needs, and we are building it for everyone.
7.3.2.2 Challenges
Compiling an AI graph is actually quite different from traditional compilation problems.
An AI graph contains two things:
- the graph topology (how the layers are interconnected) and
- the model weights (parameters associated with specific layers).
In terms of size, the graph topology is on the order of kilobytes, whereas weights are on the order of megabytes and gigabytes. For example, look at some of the bigger models released by Meta. The Open Pre-trained Transformers have 30B, 66B, or even 175B+ parameters, which equates to 100+ gigabytes of weights. There are even larger models like Gopher or Megatron too.
MLIR in the Modular compilation stack
The Modular stack leverages the MLIR compiler infrastructure to represent and transform AI models, including AI operator graphs (for multiple frameworks), mid-level runtime primitives, and low-level machine code generation. Our team has many of the foundational architects of MLIR, who were deeply involved in releasing MLIR to the world, and we continue to actively maintain large portions of core MLIR today.
MLIR is a good thing, but its approach for managing weights was not!
One of the fundamental building blocks of MLIR is an Attribute, which you can think of as a form constant data that is “unique’d” (aka, memoized, or intern’ed). Attributes are user extensible, meaning they may take various forms depending on the use case. Attributes are used for things like constant expression values (e.g. “5”, “10.0”, etc.), string literals, for enumerators (e.g. “less than”, “greater than”, “equal to”, etc.), for arrays of data … and far more. Most MLIR-based AI tooling uses attributes to hold weights for AI models.
However, this is a problem: model weights can be enormous, and MLIR stores a two-gigabyte weight tensor the same way as a four-byte tensor — in an attribute containing a unique’d array of elements. This creates an obvious problem given we just used the words unique’d and gigabytes so close together!
Here is the challenge: when something is unique’d in MLIR, it is allocated, hashed, and stored within an "MLIRContext". These objects have lifetimes attached to the MLIRContext, and they are not destroyed until the context is destroyed. This is great for small values because we can pass them around and compare unique'd objects by pointer, share allocations for attributes (very common), and more.
These benefits turn into a liability with huge weight tensors: we don’t want to reallocate, copy, or unique them. We also don’t want them to live forever: it is important to deallocate big weights when the computation no longer references them. For example, when we run a tool that quantizes our model, it needs to transform the operator graph and generate new weights — and can end up with multiple copies of that data which all live for the duration of the compilation process.
Another problem for ML tooling is how MLIR was serialized to the file system. When we started, MLIR had no binary serialization format - just a textual format. This is a problem for large weights because each byte of binary data ended up being emitted in a hexadecimal form - taking 2x the space as the data it is encoding. That means that we end up not only taking a long time to create the hex (about 20 seconds for a decently sized multi-gigabyte model), but our intermediate files are twice as big as they should be - 2x an already big number!
A bigger impact than just developer productivity
This well-intended design mechanism can cripple even the best compilers. The most obvious challenge is that it compounds the time necessary to compile, inspect, and transform a model. If you have ever used the excuse, "My code's compiling," you'll be aware of the pain this creates. Here, we are forcing the processor to continuously allocate, copy, and hash multiple gigabytes of data.
A bigger problem than compile-time is that memory use impacts larger scale architectural features in the Modular stack. For example, because our compiler and technology stack itself is highly parallel and utilizes advanced features like online search, memory use directly affects the amount of work we can do in parallel. This is important to get the highest quality of results.
At Modular, it is core to our ethos that we build tools that users will fall in love with. We realize that advanced features simply won’t get used if they are difficult to use, impact productivity, or have significant caveats (e.g. they don’t work in all cases). We love that fixing these foundational problems with large weights, allows us to subtract complexity from our users lives and workflows.
7.3.2.3 Core additions to MLIR
We took a step back to understand what we needed to solve this problem with large model tooling and listed out:
- Only allocate memory when necessary: We know it is more efficient to memory map large data (like weights) from disk, instead of copying data into malloc’d blocks.
- No hashing or uniquing: Let’s not check equality of 2 gigabytes blobs of data; weights should be identified by name instead of being implicitly unique’d by content.
- Enabling Inline Mutation: If there is only one user of the data, we should be able to quantize, transform and manipulate data in place instead of making a copy of it first.
- Enable deallocation: The data we are working with is huge, and we need to deallocate it when the last reference to the data is destroyed.
- Fast serialization: Whether JITing, searching optimization parameters, or just iterating locally, we cache IR for many reasons, and it should be fast.
Fixing the weight attributes
模型中的weight是常量,在模型的训练过程中不会变。这是一个重要的基础,跟其他一般编程中的情况不一样,一般编程中的不变量是少数,而大部分变量都会随着计算过程而发生变化。
The first four requirements address one fundamental problem with how we've been using MLIR: weights are constant data, but shouldn't be managed like other MLIR attributes. Until now, we've been trying to place a square peg into a round hole, creating a lot of wasted space that's costing us development velocity (and, therefore, money for users of the tools).
We decided we needed to manage this weight data differently than other types of attributes. This prompted our first fundamental extension to MLIR, "Resources," a mechanism to separate data from its references within the computation.
第一个基本扩展:resources,一种将数据及其引用进行分离的机制
Each blob of serialized MLIR may now contain additional sections, known as “resource” sections. These sections either include
- “dialect” resources (a dialect is essentially a namespace-like abstraction used when extending MLIR) or
- “external” resources (for toolchain-specific data).
The data within these sections is represented using a simple key-value pairing, creating a json-like structure, like so:
Encoding resources this way also brings some secondary benefits:
- Printing IR for debugging is less error-prone, leading to a better development experience: Resources are specialized sections; we don’t have to worry about accidentally dumping 4 gigabytes to the screen while debugging something.
- We can soundly process the IR without the data present: With the IR only holding references to the data and not the data itself, we can omit the underlying resource data if desired. For example, this greatly simplifies reproducers that don’t need the big weight data (consider sending a colleague a 20-megabyte file instead of a 1.2-gigabyte file).
By introducing resources as a new concept, we’ve finally been able to build a clean separation between program and data. Now we never pass our weight data directly to an attribute. Instead, we pass a weak reference to the attribute and pass the data to a specialized manager. With this, we now have much more control over when and how weights are allocated, mutated, and destroyed.
A new binary encoding for MLIR
With a better representation of our weights, the only thing we needed now was a more efficient method of storing these weights when serializing our MLIR representation.
What is the user impact?
In the end, adding resources and a binary encoding to MLIR has made our toolchain and development workflow significantly faster and reduced our memory usage substantially - making our performance and velocity incredible. It’s also made everything about MLIR better — more on that later.

Said by every MLIR developer, everywhere
To validate this, we tested our changes across models of various sizes, measuring the speed of a real-life lowering and optimization pipeline in our MLIR-based graph compiler (from a TensorFlow serialized model to the input format of our runtime) and the memory used during that process.
*Speed: Compilation Workflow*
MLIR is now significantly faster. Going from a serialized TensorFlow model (from a checkout of TensorFlow 2.10) to our runtime input format, a process that involves many transformations of the underlying program representation, was ~1.8-2x faster in terms of wall clock time than before, with speed scaling consistently across the various model sizes.
Diving a bit deeper, the TF serialized model processing is now basically instant — all our time is spent writing the big-weight data to disk when generating the MLIR. In fact, the actual time spent in our code is about 10x faster than before. Most of the time is now bounded by the speed at which the SSD writes >1 gigabyte of data to disk.
For ML developers using our tools this means faster model compilation, thereby improving productivity and iteration time. This has benefits for production environments as well when loading (and compiling) models. For example, when dynamically loading and unloading models based on incoming traffic — e.g., use cases with many of personalized/fine-tuned user models.
*Speed: Serialization*
Also faster is serialization due to the introduction of a binary encoding. Interacting with MLIR via external tools depends on the reading and writing of serialized MLIR — whether for introspection, caching, reproducer generation, etc. Again, we tested serialization performance across various model sizes and saw a significant speed-up, peak performance being SSD bound. More specifically, reading textual data for larger models took ~5 seconds compared to <10ms for reading binary. And writing was > ~5x faster for binary than textual formats.
For Modular, this enables us to develop infrastructure and tooling around MLIR that would otherwise be prohibitively slow or expensive. For example, this would allow us to provide an efficient debugger that relies on caching model representations throughout the compilation workflow, improving the underlying compiler performance, and much much more.
*Memory Usage*
Finally, the mmap capabilities of our binary serialization and the separation of IR and data via resources have also significantly reduced memory consumption. Across all model sizes, we are using less memory during the compilation process. Where before we had to allocate the relative size of the weights in a model, we no longer have to allocate at all for the weights, meaning we save significant memory every time we compile.
7.3.2.4 笔记
传统的深度学习平台,比如TensorFlow、PyTorch和CUDA,他们并不是模块化的,所以它们随着技术的不断发展积累了越来越多的相互依赖和耦合,然后在企业实际部署应用的时候,面对异构的硬件平台和加速器,比如服务器、移动端、microcontroller,或者浏览器登,企业就需要跟这种耦合花费很大的精力。
所以Modular目标是面向异构环境的实际部署问题,在软件的构建层面,通过提供模块化的设计,来适应这种环境变化,使得部署成本更低,部署其实也就是产品化的核心过程。
这些平台构建出的是单一的大型系统(monolithic system),一旦脱离它们初始的目标,就不容易扩展和泛化。这种局面导致了硬件产生针对这些平台开发各种工具,导致AI工业的碎片化,这些工具具有各自的限制和一些权衡。这样的设计模式导致这些创新工作不易于使用,不易于移植,也不易于伸缩。这样的技术使得只有大公司的全栈专家才能够很好地掌握和使用这些技术。
AI技术必须能够很容易地被任何人使用,这样才能使得创新产品可以复杂的软件和硬件链中解放出来,从而巨大地提升我们的日常生活。Imagine a world where ML research truly flows rapidly and effectively into production from a large global community. One where these breakthroughs are more accessible to everyone, allowing product innovators to drastically improve our daily lives and be freed from the chains of software and hardware complexity.
7.3.3 Jittor
The development of deep learning frameworks revolves around improving human productivity and com- putational performance. To achieve good performance from modern processors, developers often need to write assembly language, use special instruction sets, or use specialised languages or libraries, such as shaders for GPU programming, CUDA [9], and OpenCL [10]. Although these provide excellent perfor- mance, they are difficult to use and debug, and furthermore, programmers need a good understanding of the underlying hardware. Scripting languages such as Python and JavaScript are interpreted, giving immediate feedback, further reducing the difficulty of programming, but this sacrifices performance.
To simultaneously improve productivity and performance, various scientific computing libraries and deep learning frameworks have been developed. A widely used optimization method is static compilation with dynamic binding. This optimization method uses C, C ++, CUDA [9], or other languages to statically compile the operators needed in deep learning, while the user dynamically applies them via scripting languages such as Python and Javascript. Many frameworks adopt this approach, including Numpy [11], Matlab, Theano [2], TensorFlow [4], MXNet [12], and PyTorch [5].
Dynamic binding allows users to take full advantage of the underlying hardware performance when using a scripting language, but it has a problem: all operations are statically compiled, making optimiza- tions such as operator fusion difficult; this important optimization technique combines multiple operators into one operator, so that intermediate results do not need to be stored. Dynamic binding with a scripting language cannot use this optimization. For example, the user may need to calculate d = ab + c, where a, b, c are tensors. First, the scripting interpreter executes tmp = TensorMul(a,b) and then executes d = TensorAdd(tmp,c). If we could compile the whole expression, rather than applying operators one by one, we could execute d = TensorMulAndAdd(a,b,c) directly without the need for temporary storage. This is significant, as on modern processors, memory access is often much slower than calculation. However, we cannot guess what combinations of operators the user may require, and static compilation of all possible combinations is obviously infeasible. To solve this problem, we may use JIT compilation technology to dynamically compile and optimize the operators that the user needs.
Jittor is a completely new design of deep learning framework based on JIT compilation technology. Following the above discussion, Jittor is designed based on the following principles.
• It should be highly customizable yet easy to use. Users should be able to define new operators and models with just a few lines of code.
• It should separate coding from optimization. Users should be able to focus on coding using the front-end interface, while the code is automatically optimized by the back-end. This improves readability of the front-end code, while well-tested, standard optimization code in the back-end ensures robustness.
• Everything should be compiled JIT. This includes the back-end and operations. Users should be able to change the source code at any time.
7.3.3.1 The front-end
Meta-operators
元操作是在一般的操作上添加了一个特定的类别,深度学习框架通常提供许多内置的操作使开发深度学习模型变得更加简单,而这些操作通常做一些相似的事情,所以可以对这些操作建立更高的抽象。通常这些操作可以分为三类:
- Reindex,在输入和输出之间建立one-to-many的映射,例如broadcast、pad、slice,In short, the reindex operator rearranges the input and stores it in appropriate positions of the output. Index bounds checking is also performed based on the indexing function.
- Reindex-reduce,提供many-to-one的映射,例如sum、product
- Element-wise,逐元素计算,例如矩阵计算,输入和输出都具有相同的shape
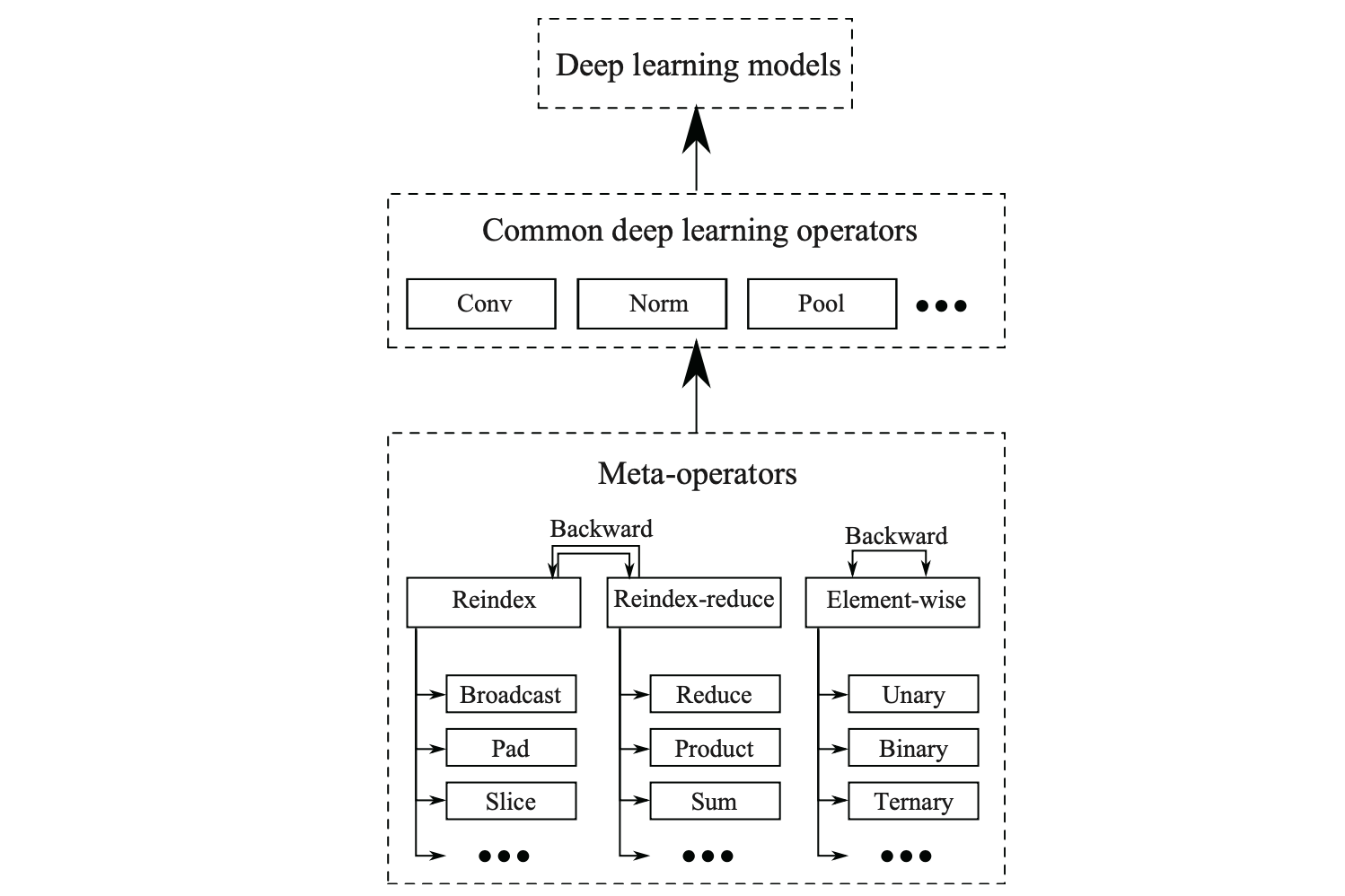
Fusion of operators
利用上述的类型信息,Jittor可以将多个操作进行合并,计算出一个新的计算公式,使得很多中间变量的存储被省掉。
但其核心是通过元操作的类型和分类,知道和每个操作函数的形式,尽管是一种抽象的形式,这样就可以对函数进行合并。
就像我们在进行数学函数的合并时,我们并不需要关心每个值是多少,只需要关心函数的形式,然后根据函数的形式对函数进行合并之后,再将值带入最后的函数进行计算。
Variables
Variables are tensors with the following properties:
• A shape attribute. • A data type attribute, dtype, e.g., float or int. • A stop grad attribute to prevent gradient back propagation for this variable. • A stop fuse attribute to prevent fusion of operators associated with this variable. The stop grad attribute is usually used in testing or inferencing, while the stop fuse attribute provides control over operator fusion: the user may get better performance by careful use of these attributes. For example, operator fusion will consume register resources in a GPU. With sufficient resources, fusion will always improve performance, but fusing hundreds of operators will exhaust resources and cause performance degradation.
7.3.3.2 The back-end
The back-end is responsible for resource management, process scheduling and compilation optimization. It includes the operator fuser, which decides the fusing strategy used for the meta-operators, external operators, which are customized operators provided by users or third-party libraries, the JIT compiler, the integrated compiler used to optimize meta-operators, and the unified graph execution, which unifies static and dynamic graphs execution.
Operator fuser
实际的计算图是非常复杂的,为了更简单地处理这个问题,将计算图看做一个有向无环图,其中的节点表示一个操作,而边表示变量,通过将图划分成多个子图的方法来进行fuse操作。其判断的依据使得总的代价最小,其中代价函数 表示为每个子图对变量的读和写的指令的总数,因为大部分深度学习框架的性能瓶颈主要在于内存操作。fusion通过减少内存操作来提升性能。
除此之外,也有几个特定的规则需要满足。
JIT compiler
在fuser之后,将代码编译为高性能C++代码。并会进一步被LVVM优化至不同的硬件平台。
Unified graph execution
According to the execution method of computational graphs, deep-learning frameworks can be based either on a static graph execution (also called a define-and-run approach) or a dynamic graph execution (define-by-run, eager execution). Static graph based frameworks are efficient and easy to optimize, and dynamic graph based frameworks are easy-to-use and flexible. Most current frameworks, including TensorFlow 2.0’s eager mode, PyTorch, and Chainer, support dynamic graphs.
As an alternative, we propose our unified graph execution approach. Unified graph execution provides an imperative style interface which has the same flexibility as a dynamic graph. And it is also as efficient as a static graph.
静态图在运行之前定义model,然后运行时对数据执行操作。其中在编译的时候使用一个placeholder来表示数据,编译器对计算图进行优化。由于只有运行时才会知道数据,所以像print这样的方法无法支持,不利于调试等。特点是性能高、实现简单。TensorFlow采用这种模式。
Eager execution executes each operator immediately when it is added to the graph. Because addition of operators is performed on the CPU while they are executed on the GPU, eager execution will lower the latency between CPU and GPU, thus reducing overheads, allowing this approach to achieve competitive performance with the static graph approach. this furthermore allows the user to manipulate intermediate results during model building. This provides users with a great deal of flexibility: for example data can be printed, and the model can be changed according to the intermediate results obtained, which is hard to do with static graphs, and is essential in applications such as generative adversarial networks (GANs) [18] and reinforcement learning [19]. For example, when training a GAN, the computation graph keeps changing between the discriminator and generator. This flexibility has made dynamic graphs popular, and most frameworks (such as TensorFlow 2.0’s eager mode, PyTorch, and Chainer) currently support them.
To obtain the benefits of both approaches, without their drawbacks, we use a unified graph execution approach. It provides the full flexibility of a dynamic graph, and the graph can be rebuilt frequently without performance degradation, yet operator fusion is still possible. This is achieved by lazy execution. See Figure 7(c). Operators interpreted by Python are not executed immediately, but delayed until their results are needed. op1 in line 3 is not executed until x2 is printed: x2 is needed at that point, and it depends on x1 which in turn requires op1 to be executed. During printing in line 5, three things happen. First, unified execution will select all those operators in graph G that are required by printing, and split them off into a new sub-graph G′; in Figure 7 this is op1 and op2. The sub-graph G′ is then optimized using the operator fusion process in Subsection 4.1: the operator fuser takes G′ as input, and partitions G′ into multiple sub-graphs G′′, where each sub-graph represents one fused operator. Finally, sub-graph i G′ is executed. In this very simple example, as op1 and op2 are executed together, there is an opportunity to fuse them before doing so. While addition and execution of operators is coupled in the dynamic graph, it is decoupled in the unified graph.
7.3.4 PyTorch
深度学习框架通常是一个library,而不是一门通用编程语言,library意味着它有自己的特定逻辑,它只能处理它的逻辑所定义的事情,就像其他任何library一样。
传统的深度学习框架都是使用静态数据流图,它们都是现编译好模型,然后批量执行数据处理,这虽然有比较好的性能,但是丧失了易用性、灵活性,也不易于调试。
define-by-run approach
Separately, libraries such as NumPy[12], Torch[6], Eigen[13] and Lush[14] made array-based programming productive in general purpose languages such as Python, Lisp, C++ and Lua.
Easy and efficient interoperability is one of the top priorities for PyTorch because it opens the possibility to leverage the rich ecosystem of Python libraries as part of user programs. Hence, PyTorch allows for bidirectional exchange of data with external libraries.
Moreover, many of the critical systems are designed specifically to be extensible. For instance, the automatic differentiation system allows users to add support for custom differentiable functions.
Most importantly, users are free to replace any component of PyTorch that does not meet the needs or performance requirements of their project. They are all designed to be completely interchangeable, and PyTorch takes great care not to impose any particular solution.
7.3.4.1 Perform focused implementation
Python Global Interpreter Lock (GIL) is a type of process lock which is used by python whenever it deals with processes. Generally, Python only uses only one thread to execute the set of written statements. This means that in python only one thread will be executed at a time. The performance of the single-threaded process and the multi-threaded process will be the same in python and this is because of GIL in python. We can not achieve multithreading in python because we have global interpreter lock which restricts the threads and works as a single thread.
Running deep learning algorithms efficiently from a Python interpreter is notoriously challenging: for instance, the global interpreter lock [33] effectively ensures that only one of any number of concurrent threads is running at any given time. Deep learning frameworks based on the construction of a static data-flow graph sidestep this problem by deferring the evaluation of the computation to a custom interpreter.
An efficient C++ core
核心代码 都由C++编写,然后binding到Python,包括数据结构、CPU/GPU算子、并行计算等,这样可以绕开GIL,同时还可以将PyTorch的代码binding到其他语言。
Separate control and data flow
PyTorch严格地将控制和数据流分开,这里的控制主要是指CPU上的程序分支、循环等控制算子的逻辑,这部分在Python和部分C++中执行;而数据流指的是用于在GPU中执行的算子调用及其相关的数据,可以理解在在GPU中执行一次计算需要的算子即数据,这些计算按照线性的方式进行排序,然后被转换为CUDA kernel的队列,按照FIFO的顺序被执行。
这使得程序是异步的,能够充分使GPU的计算达到饱和,即便是在Python这样的解释性语言中也可以得到非常高的性能,因为真正需要话时间的计算都是CUDA编译的,而Python只负责控制逻辑。
Custom caching tensor allocator
你知不知道主流深度学习框架pytorch是按照着Haskell typeclass SML module的模样架构的,Pytorch主maintainer就是一个Haskell高手,Pytorch薄纱Tensorflow就是PL薄纱System的一个绝佳例子?
作者:圆角骑士魔理沙 链接:https://www.zhihu.com/question/21410150/answer/2740843224 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
7.3.5 OneFlow
Deep learning frameworks such as TensorFlow and PyTorch provide a productive interface for expressing and training a deep neural network (DNN) model on a single device or using data parallelism. Still, they may not be flexible or efficient enough in training emerging large models on distributed devices, which require more sophisticated parallelism beyond data parallelism. Plugins or wrappers have been developed to strengthen these frameworks for model or pipeline parallelism, but they complicate the usage and implementation of distributed deep learning. Aiming at a simple, neat redesign of distributed deep learning frameworks for various paral- lelism paradigms, we present OneFlow, a novel distributed training framework based on an SBP (split, broadcast and partial-value) abstraction and the actor model. SBP enables much easier programming of data parallelism and model parallelism than existing frameworks, and the actor model provides a succinct runtime mechanism to manage the complex dependencies imposed by resource constraints, data movement and computation in dis- tributed deep learning.
OneFlow的核心思路,是根据模型的计算图,静态地推导出节点之间的依赖关系,然后利用Actor模型,把每个节点当做一个Actor,通过 依赖关系来决定计算顺序,通过计算图节点内部的状态来管理Actor的计算。Actor之间消息传递的是对应节点的状态,如果一个计算节点的上游已经计算完毕,则当前Actor进行执行状态,可以被空闲的计算机进行计算。此外在计算一个节点之前,如果涉及数据需要处理如拷贝的,则有专门处理数据拷贝的Actor会进行处理。
OneFlow的核心还是因为静态的计算图可以完整推算出所有节点的计算顺序,然后可以依据这个顺序进行分布式调度。
RealityIS相对于OneFlow有以下一些区别:
- 计算图的节点类型是固定的,因此可以有很多信息帮助推断节点之间的依赖关系和状态,而RealityIS的组件之间的依赖关系是不能事先推断出来的,每个组件的方法参数都不一样,没法进行这样的全局推断,所以它只能动态计算,不能有一个已知的依赖关系来全局指导
- 计算图节点之间的依赖关系是事先静态推导出来的,而由于缺乏上述那样的类型信息,RealityIS的依赖顺序只能运行时动态计算
- 计算图的计算不是实时的,它是一次性的计算,因此Actor之间通过消息协调顺序所带来的开销并无太大影响,但是如果一个模型特别大,这种调度对于实时系统的开销是很大的
- OneFlow以节点在计算单元,而RealityIS中对象或者一个对象内部的组件之间的依赖关系会更加复杂,而且还要考虑UserID带来的信息维度对应的复杂度,如果单纯以逻辑计算单元如组件为一个Actor,会带来非常大的状态同步和消息通信的问题。
显然,对于两者而言,核心的问题均是计算顺序或者说计算单元之间的依赖关系的问题。
- 在传统的面向对象模型中,整个程序的计算顺序完全内置于代码内部
- 在深度学习模型的计算图中,计算顺序其实也是已知的,类似于上述面向对象计算模型,OneFlow只是把这种依赖顺序转换为数据,来指导分布式计算而已。而为什么它能够提取这种顺序,是因为计算图将数据和计算分离,数据充当了计算之间的连接,并且天然划分成不同的细分几点,因此自然容易将这种顺序数据抽取出来。
- 在游戏架构中,这个事情会比较复杂点
一方面,游戏组件之间的依赖关系肯定是可以推导出来的,但这有个重要的前提:那就是每个组件的输入输出关系需要非常明确,传统的计算图其实就充当了这样一个明确的关系,这种输入输入关系决定了节点之间的计算顺序。然而传统游戏中,假设两个组件A和B,A对某个数据属性进行写入,然后B对A写书的数据进行读取,这样我们就可以推断出A应该先于B执行。然后我们在传统面向对象编程中仅仅把变量当中一个可读可写的普通变量,因此运行时或者编译器并不能推断出哪个组件对该属性进行只读操作,而哪个组件对该属性进行写操作。因此系统没法推断组件之间的依赖关系,一般指采取一种比较野蛮的方式:即全局地给组件加一个计算顺序,或者说指定某个组件对其他组件的依赖关系。这种方法显然不够鲁棒,因为同样一个组件在不同的对象中可能需要存在不同的计算顺序,特别是当使用一些模式 匹配的方式的时候,组件的顺序更是不确定的。
为了解决这个问题,RealityIS对属性的访问需要明确定义读与写的关系,这其实就是间接地定义清楚了计算图,这样运行时就可以进行依赖顺序的推断。
7.3.6 PREDA
可以编译到Web assembly,认为太包罗万象,区块链是非常简单的,不需要那么多特性、资源管理比较简单,不需要GC,执行完所有东西全部删掉,希望有更轻量级的东西。
7.3.7 Web Assembly
rust在web assembly方面走在前面
是一套新的指令集。
Rust开发者受到的约束比较大,比如类型系统。积极拥抱一些学术的成果,Rust的成果代表编程语言理论的成功。
语言的动机:
- 解决特定的问题,java,erlang,rust
- 平台型,C#,Swift,Go,生态,未来技术演进
- 兴趣、学术研究型,Scala,Haskell等
7.4 Others
7.4.1 神经网络
7.4.2 开源代码管理
7.4.2.1 pip
7.4.2.2 Rust
7.4.3 区块链/NFT/虚拟货币
NFTCN/Bigverse/Opensea
当前的NFT数字资产市场主要还是偏2D
- NFT资产生成本身很简单,因此也容易复制、山寨
- 创作方式简单,大多数甚至都是一些简单的图像处理及风格化工具或者简单的编辑,而开发3D的内容生成要难得多
- 仅仅是一个市场,无对内容进行价值发现和价值增值的方式和空间,当前主要的机制是低买高买,空等着增值,比较依赖于所谓的一些估值的机制和服务来判定价值,但实际上现实生活中一个艺术品的价值有时是通过人们的了解、学习、结构、研究、背后的文化价值和社会价值的发掘和演进后,才会慢慢催生一个作品的价值,而一个单单的市场并不足以形成这样的机制,这样作品需要一种能够更生活化的呈现机制,而不仅仅是一个列表,它应该能够让更多的人对它有更多维度、更多机会的再认知,结构、解读、欣赏、观察、体验,这样才有机会去挖掘它的价值,它绝不是你买来放在那里他就自己会增值
- 仅仅一个市场,作为一个独立的3D或者3D的形式展现,缺乏与之相关的环境,特别是3D作品往往不是单个物体那么简单,它的表达往往和环境等因素有关,作为一个单独的作品,既容易被复制和下载,又缺乏表达能力
拟娲的3D创作更难,并且它的内容不是单个主体,而是融入在环境中,甚至和其他内容一起呈现,环境甚至程序都是一部分,在脱离这个环境,他甚至都无法运行,被复制的风险降低,同时它并不是一个单纯的市场,它更多是处于一种被欣赏的社会状态,它的价值更容易被解读和结构,融入真正的价值评判体系和方式
3D内容不适合交易
不像传统的图像艺术,更多被收藏,互动内容是动态更新的,它也与特定的运行时环境和操作系统高度耦合,他还会进行不断更新,修复bug,因此他更适合按玩家收费,按服务收费,而不是一个一次性的产品买卖,当然仅作为纯资产的数字内容不一样
虚拟地块:
虚拟地块也是没有好的价值支撑,并不是任何一个虚拟空间弄一个唯一地块划分的机制就可以,那样的话就太简单了太容易了,现实很多元宇宙的概念和产品给人的感觉就是太简单太容易了,这是不符合逻辑的,其根本原因是没有价值支撑,没有共同的价值认同基础,比如如果在赛尔达里面建立虚拟地块,那肯定有价值,因为他有价值认同基础,但你随便搭建一个地块,他并不具备共同认同价值,仅仅是像赌博一样少部份人的炒作,大部分人并不认可这些价值
所以,怎样创建价值认同基础是最重要的,因为价值创造和认同是很难的,不然就编程虚拟货币一样一种纯机制,没有价值担保
价值认同需要所有人能够参与,以某种方式,才能形成价值认同,这种参与或者价值认同应该是现实世界一样,需要一种实际的参与方式,而不是仅仅像炒房一样,就是说它需要具备真正的价值,不管是游戏带来精神上的,或者它传达了某种知识或者文化。
传统数字内容得货币化还存在一个重要问题,它需要一种担保机制,不像实物一样物权是唯一的明确的,当然这也是有国家机构担保负责物权管理,虚拟货币或者区块链虽然在机制上能操作一个数字内容的物权唯一,但是这个数字内容本身是可以复制的,例如一个作者可以在不同的数字平台发布,理论上,只有平台自身可以保证物权唯一,平台必须与作者达成实物或者原始作品的物权协议,比如作者不能在其他平台再使用次作品,或者作者销毁原始电子版,这样保证该平台的物权唯一,但这些机制都依赖于真实世界的法律保障,实际上虚拟货币只要是跟现实世界关联的,它的物权都需要现实世界的法律物权保障
除非是完全虚拟货币,他不需要映射实物,货币的发行本身就是基于区块链大型的,所以它本身就有物权保证了,但是这种也是没有法律保障
拟娲的数字内容是由用户创建的,或者大部分,虽然用户可以导入一部分已有资源,这部分无法控制物权的唯一性,需要借助现实世界的版权机制,但是它的大部分内容是用户基于拟娲平台创建的:
- 首先是它的那个内容在创建时已经基于区块链技术得到物权保障
- 其次是,它的数字内容不像传统的图片或者视频,其很容易被复制保存,也不像传统的3D内容一样容易被下载,它本身是一种私有格式,他必须借助平台才能解析,它的内容也全部存储在云端,这使得它的物权能够进一步被保障:你只能在这个平台才能体验这个作品,但在这个平台它是唯一的,你不能将它复制到其他地方
- 当然拟娲本身还有一套价值认同的机制,就像游戏一样,你必须要发挥你的经验和创造力,付出时间和思考才能创作出好的东西,而其他用户在体验过程中体验到了你的文化艺术表达,你的价值并被认同,用户有一个体验的过程,而不仅仅是一个商品买卖,这类似于商品需要使用才有价值,这个使用就是对数字内容文化艺术表达的体验,使用+交易 才能形成循环:使用发现价值,促进交易,进而促进使用价值的创造
- 静态2D艺术品其实还是纸质更珍贵,无论是创作的难度、仪式感,还是体验欣赏时的专注和仪式感,在数字屏幕上看2D艺术受很多因素影响,比如受屏幕分辨率、色彩、屏幕尺寸等因素影响,但3D数字内容则天生是虚拟的
区块链技术导致的思维有时候很受限,大家会倾向于放大这项技术的功用,认为一切皆可以使用区块链,因为所有事务本质上都涉及物权和交易,但他有缺点:
- 有时候会让一些事情更复杂
- 而更大的问题他可能会限制我们的想象力,例如游戏的分发跟传统的交易是不一样的,传统的交易物品是独立的,或者不可分割的,一次交易对应一件具体的物品,但是游戏程序通常是有持续更新的,当游戏这种数字资产发生变更,他的Token会变更吗,变更了原来的购买就失效了,但不不变更怎样让订阅的用户享受到新增服务,所以当前的NFT市场主要聚焦于图片这种通常不会修改的静态内容,它本身不是程序,而3D数字内容会面临更复杂的变更
- 再比如,传统的书画是收藏的概念为主,它本身是由实体唯一性演变出来的方式,通常一个画家不会批量画同一副画,但交互程序天生就是数字出生,以复制的方式为主,他要面对的是玩家数量的概念和模式,单幅画的收藏价格很高,普通人根本承受不起;而游戏面向群体,所以单个复制的成本很低,这才导致普通人可以参与,这是两种完全不同的模式,前者容易导致反复拍卖,多次交易,而后者几乎只有一次性交易,防篡改的需求很低,我们唯一需要保证的是版权而非物权,而区块链恰好不擅长版权
- 3D防篡改的需求远低于图像,因为它的数字内容篡改不仅仅意味着数字存储的内容变更,而很有可能篡改的程序无法运行,因为它的运行时环境,及其他一些依赖如联网等高度相关,对于游戏程序人们一般篡改的是外挂而非程序本身,我们主要保护的是原始的版权,而非交易过程中的物权
7.4.4 Rust
游戏和图形系统相对传统应用架构并行计算的行为更多,要重点关注语言对并行计算的支持
embark.dev
Rust-gpu
Kajiya
rafx
gamedev.rs
7.4.5 Unity EditorXR and SceneFusion
7.4.6 BEVYengine
基于数据驱动的rust游戏引擎
7.4.8 magicavoxel
感觉以Voxel 为基础的创建,一是比精细的三角形便于生成,而且符合物理创建的方式
7.4.9 所有平台的插件架构
Unity unreal engine blender
7.4.10 传统DCC流程
7.4.11 Meta Builder bot
语言或文本至少生成要素,如果有误差,至少大部分要素,然后用户交互专注于精调,或者把要素和交互分开,在用户确定要素之后,相当于有了类型先验,再确定交互有更多背景
在C端,从数据库选择会比较复杂,所以对数据进行类型划分,并具有一定的无法对内容进行组织变得非常重要,大大减少交互成本,而将交互集中于当前场景可以看到的东西,所以的按钮都转成语音或者一些快捷文字,短语,关键字
https://mp.weixin.qq.com/s/JKe-KrInwAzIjb9ndXpJoQ
7.4.12 Houdini: Node-based Workflow
3、Houdini
要像Houdini 一样把复杂的结构定义,方法构造,流程定义,参数赋值,等全部去掉,用户只专心写逻辑,最后整个编程是像Houdini 那样干净整洁的,没有代码痕迹的
Houdini的node没有参数,只有节点,他把operation分成一些类型,那个类型之间的参数传递是固定的
Houdini的Node network 是一种运行过程,他既可以充当:
- 静态配置,如果所有节点没有延迟,瞬时执行,他就类似于一个静态设置,如果这些节点的指令能在一帧内执行完,这有点类似于一个usd或者其他合适文件的加载过程,相当于在加载过程的顺序执行中,后续的加载可能会修改前面的属性,但不足的方面是加载的过程无法并行化,因为Node network 是一个顺序指令
- 动态动画,如果某些节点的执行需要时间,他就形成动画
Houdini的流程和数据驱动的流程是不一样的,一个是执行计算的过程,一个是单纯的组合配置,这是因为Houdini 实际上是一个内容生成的过程,或者说它是编辑态,而ECS是运行态
内容生成过程中怎么对一个基础模型进行变形,其输入输出参数是确定或者可以推导的,但是逻辑之间的关联则比较复杂,没有规则,需要定义协议
Directable results
由于所有设计都是过程式的,整个创作过程都是过程式的,所以可以在最后一刻进行修改,而传统的硬编码,它具有许多中间形态,没有形成一个整体流程和结构,所以很容易中间某些流程或者逻辑变了,其后面的流程都受到较大的影响,甚至需要重新修改后面的代码和逻辑,迭代成本高
数据驱动有点某种程度上可以实现这个目标
其实就有点像编译流程或者渲染管线一样,他定义好了整个管线之间的参数和接口,那么中间的调整就不会影响那么大,你只需要遵循接口规范就行
Tool building
基于node-based的工作流程可以使得自定义node变得可能,只要遵照node之间的协议,然后node就可以共享,即:
Houdini Digital Assets
上下游的参数形式基本是还是Houdini 本身的node定义的,开发者只是把中间某些处理过程保存为一个.hda 资产,因此不需要定义参数,创作做的只是把一个复杂的生成过程复用,这些复杂的生成过程还是用Houdini 基本的操作,Houdini有海量的基础操作,创作者几乎很少会编写自定义函数代码,或者只需要简单很小片段的代码
所以Reality World要想做到这一层,要对游戏逻辑脚本进行深入分类,并把这些模式术语化,这些分类要能够对比,所有游戏的逻辑组合,以及保证相应的灵活性,使得自定义的成本最低,自定义的模式更简单
A new way of thinking
由于全新的方法,可以定义的能力而不是针对具体问题重复解决,就会产生一种新的创建数字内容的思维
编程都是在node之间编程,固定的输入输出
跟Houdini 的主要区别是他是离线的,编辑态的,不需要内容审查,兼容性检查,安全性等,而拟娲是运行时的,包括包的大小,仿真模拟,安全,兼容性等问题很多
一方面可以通过编译器要做一些分析,另一方面用户需要在自己的环境跑起来
7.4.13 realityOS
7.4.14 OpenXR
苹果退出了OpenXR意味着:
- 苹果会对XR的理解有较大的差异,苹果也是希望加强这种差异来增强自己的竞争力和差异化
- XR的标准还存在很多变数,标准本身可能面临较大变化
- XR的开发接口会进一步分化,开发者面对更加复杂的概念和开发方式,这种情况下自研的接口封装会更快速相应这种变化,并且简化用户开发
7.4.15 ECS + AI
EntitiesBT
Behavior Tree
在原生的ECS框架下实现具有坚强依赖关系的功能是否很难,例如行为树,这种情况下,如果是像行为树一样相对固定的规则,我们可以像UE blueprint 一样定义套框架,然后对于这个框架按太极一样的思路在编译层对代码做重新调整,当然要考虑重新编辑的便捷性,所以可能是拟娲运行时上的一个脚本轻量级JIT
7.4.16 Unreal blueprint
蓝图以及相应的很多编辑器及UI界面,本质上他们并没有简化逻辑的开发,他从两个方面简化:
- 固定类型的定义:对于一些特定固定的类型,例如blueprint 包含的那些类型,他们往往在OOP中有一定的关系,例如一般需要定义那几个类或者实例,那个类需要引用那些类的实例,以及怎样对这些实例进行初始化,对于实现这些blueprint对应的功能,他们的这种通用结构被设计出来,否则那个开发者还需要定义自己的对象模型,每个人定义的可能很不一样,相应的内存管理,等等都很复杂
- 对应功能的初始化,成员变量复制管理等是很繁琐的事情,按照蓝图的编辑器,他实际上把流程固化了,因此这些基本的流程就简化了
- 剩下用户需要做的就是针对固定结构和架构下的具体某个函数进行代码编写
坏处是整个逻辑都是基于代码的,并且无法自定义,存在一定的冗余,如果不采用它的模式,也可以自己从零实现,那就需要实现整个模块的架构,对象之间的管理等,代价更大,但自由度更大,例如可以使用数据驱动,UE的流程并不一定是最好的,或者对某些特定类型或者环境下不一定最优
蓝图并没有简化逻辑的架构,他相当于UE帮助打了一个架子,开发者对其中的方法进行填充,整个还是面向对象的思路,对于Epic 来讲,它需要去实现大量这样的架构,所以它的功能比Unity要复杂得多,但这些实现对于特定的一个游戏并不一定是最优化的,他会牺牲性能来换取这种简单,因为通用的架子往往不是最优的,而它面向对象的深度实现导致代码也很难优化,例如架子里面存在大量交叉引用
像Unity因为没有提供众多这种深度定制的架子,反而能够容易去实现ECS这种优化
相对于Unity,有更多逻辑层面的封装,类似定义了一些特定类型的范式,但这些范式本身是按照OOP的方式定义的,因此他的范式是实现了一些特定的功能,而不是定义了一个框架,所以UE要学习更多的知识,很多知识就是关于这些特定范式的
除了范式本身,Blueprint 的另一个强大的功能在于它把整个一个代码块或者一个复杂的子模块系统,打散成多个以方法为单位的可视编辑模块,这样是的修改单独的模块更加简单,不需要关注函数的输入输出,不需要在代码中寻找修改函数的入口,也不需要引入一些变量的信用、读取或者修改繁琐的代码
7.4.17 Pixar
皮克斯科技与艺术结合
科技与艺术结合的结果是什么
7.4.18 Gaia procedural-worlds.com
程序化静态内容生成应该还是比较成熟的架构了,后期应该能够容易开发,到交互更难
交互的设计也要是程序化的,当然由于ECS本身是组件化的,没有操作顺序依赖,所以这个问题不大存在,但是当需要对静态内容设计多个修改时,操作步骤的影响就出来了,程序化的好处是directable,它简化了对操作的任意修改,传统的软件就是遵循规则和步骤的,这样如果有些历史操作修改了或者需要修改,往往会影响其他大量修改
但脚本只是针对单个物体的行为,整个场景的结架构设计还是应该尽可能的程序化,而Roblox 没有这样的机制,程序化的场景设计使得通常可以更高效地设计大环境,然后精调小物体,而不是对场景每个物体都要独立摆放和设计,因为大环境通常都有一定的随机性
7.4.19 Google Maps API
7.4.20 Procedural content generation
传统的DCC使用deforming, cutting, merging 等代替对三角形的直接操作,从而简化内容创作
PCG使用户专注于用于生成内容的程序化算法,而不是底层繁琐的内容操作,这种算法更符合人的逻辑
PCG的计算过程比较复杂,更适合PC端,移动端要专注玩法部份
答主对生成算法的理解就好像某些时期对火药的理解:用来放烟花的东西,需要研究更好的火药么?不是算法够了,而是设计者不知道设计目的为何,对算法没有要求。游戏核心设计绝不是剧情、场景,而是玩法。玩法是什么,就是给玩家有意思的问题,让玩家解决问题。用算法提出的问题的难度,和解决问题难度是不一样的,玩家即使知道了你如何生成问题,但是他现在也不知道如何有效的解决问题。这就是著名的NP/P问题,我当然知道俄罗斯方块随机生成的方块随机算法,但就没有一个高效的算法去解决俄罗斯方块拼接问题,数独的生成算法很高效,解决数独的算法很慢,生成地图的算法高效,访问地图上的每一个点的哈密顿回路问题就难爆了。为啥觉得生成算法没用,因为不知道要构造什么问题给玩家,设计目的到底是什么,而是漫无目的地去生成那些花花草草,和用火药放烟火一个道理,本来就不是设计的核心,再怎么提升技术也只是装饰。
俄罗斯方块就是例子,真正把算法生成要用于玩法上,就需要了解P/NP问题:用简单的信息是可以构造复杂问题。其实MOBA游戏里,一个时间段的走位规划也是NP问题:哈密顿回路问题,如果要访问和侦察地图上多个战略要点,如何才能走最少的路,消耗最少的时间,达到战略目标。有时候这些战略要点还是其他玩家影响下生成的。
7.4.21 casualcreator
7.4.22 微服务化
When it comes to cloud technology in gaming, most people associate it with game streaming. However, Scalar is based on cloud computing, which Romell as explained, is quite different from the term we've heard about so often. "Cloud streaming is a distribution model; it improves people’s access to games, but it doesn’t change, in essence, what games are, or the quality of them. The game is still being run on a single-processing machine placed remotely and then streamed via the cloud to your screen," he said.
"Cloud computing – what Ubisoft Scalar enables – means the processing power for a game isn’t tied to a single machine, but a decentralized computation system. The processing is taking place in the cloud. This eliminates the limits of local hardware for players, improves the quality of games, and opens up new possibilities for game developers."
更新不会停服
把游戏引擎的多个组件,如physics, AI等都转成微服务,然后单独在云端计算,所以理论上不受限制,传统的引擎把整个引擎在一台机器无形,由于共享整个场景大量数据,因此不好并行计算
3月17日消息,据外媒报道,在当地时间星期四的GDC演讲中,育碧斯德哥尔摩的总经理Patrick Bach、技术总监Christian Holmqvist和首席技术官/技术总监Per-Olof Romell公布了一项全新云计算技术,该技术被称为Ubisoft Scalar。他们声称该技术将创造全新的游戏类型。他们表示,这项技术将使育碧能够制作比以往更大,更复杂的游戏世界,这些游戏世界可以实时更新,并由大量玩家填充,从而创造新的社交体验。关于使用该技术开发的新作。Bach表示:“育碧斯德哥尔摩正在研究与Scalar一起开发的IP,目标当然是充分利用这项新技术的所有可能性,但现在谈论这个还为时过早”。
7.4.23 Google Tilt Brush
太偏底层,属于基础创作,生成最原始的Mesh,问题:
- 由于控制精细度不够,所以网格和材质都不够精细
- 属于基础创作,那个物体都要从无到有创作,或者基于一些基本的几何体进行创作
- 无法生成复杂几何,更多是概念上的感觉
- 并且这些作品实际上很少有被真正使用或者被当作艺术,因为创作很受限
如果要提供更精细的控制,则面临:
- UI太复杂不好操作
- 手势控制的精度误差比较大
这类创作的作品通常只是半成品,可能作为一个初始场景和概念,然后在PC上在进一步精细微调,但如果是这样,在PC上有更多的方式生成这样的概念
如果直接使用,这类场景通常没有太大用处,只有静态的东西,没法编辑动画,当然如果要在XR设备加入动画编辑,那又是另外一个很复杂,几乎不太可能的事情
所以,在XR设备上,不能直接创作原始几何,因为这样:
- 这样几何是静态的,没有动画
- 太简单
它只能是基于某些标准组件的创作,这些组件通常由PC制作,带有动画和一定的逻辑属性(因为XR上也无法编辑逻辑),并且在XR设备上交互的是PCG的方式,这样使得交互需要的并不是精细位置,而且PCG的参数,这样参数的空间和范围小的多,同时能够生成更多内容,而不是仅仅一个基础几何
7.4.24 GitHub
多人协作的典范,在协作中体现贡献度hello
比如你发现某个Creation 存在不合理,提出修改
7.4.25 Stechfab
7.4.26 Game pigeon: games for iMessage

7.5 应用
7.5.1 堡垒之夜

Game theme, starter island
组件会随着theme变化
相比堡垒之夜只从模板创建,RW具有能够让用户创造模板的能力,灵活度和可表达能力更强
Accolade 自动控制XP的获取,自动计算平衡,根据时间
资源是引用内部,需要游戏包内登录时下载,是否无法用户自己动态添加
堡垒之夜是实现了固定一套资源和逻辑的数据化,现实世界比游戏规则更复杂,不管是逻辑还是场景,交互,所以必须要支持编程扩展能力
例如堡垒之夜里大部分资源外观是不能修改的,但是生活中的设计往往都设立照片编辑,自定义一些内容,因为他是固定的类,无法组合:
- 无法通过减少或增加功能来修改已有物体
- 无法通过组合创建一个新的类型,新的功能
- 也没有办法创建一个新的资源,所有都依赖于官方构建一个新的类
- 每增加一个新的资源,都要创建一个新的类型,尽管他们有复用,代码会重复,用户需要理解和记住的类型非常多
所有东西或者大部分东西都被视觉化,然后数据驱动,修改设定好的属性
堡垒之夜简化了树形层级结构,所有内容都是扁平
7.5.1.1 定义交互类型很重要
堡垒之夜有122种devices
7.5.1.2 多人在线服务
音频的重要性
7.5.1.3 私密社交
I, I, couldn't be more pleased with the situation in Fortnite. Fortnite is the most positive social experience I've ever interacted with.
Um, and it's true that there are negative people out there sometimes, but the far majority of encounters are positive. Um, and also the far majority of social engagement on fortnight isn't with random strangers. It's not what many to many with millions of people are participating. It's players together with their friends, talking with their friends, kind of as an isolated group, uh, wandering through a much larger outside world. And a lot of the decisions we've made in the game have really contributed to the positivity here. One is that we have voice chat, so you can chat with your friends, but voice chat only works with people in your squad that either you're explicitly friends with and you explicitly joined up with, or you're friends explicitly joined up with.
And, you know, we really are innately trained to, uh, you know, in ordinary circumstances, respect people when we're interacting with them personally far, far more than when we're interacting with them with text. And so I think this is an area where the matter verse will have a major advantage overall. So O other social media, it's that inherently by being focused on small groups and actual friends, engaging in a much larger outside world and in carrying all of the emotional content of voice and perhaps even facial capture in the future, uh, it'll be a much higher empathy platform, only much less subject to abuse where, you know, one nasty action affects millions of people, uh, because of curation.
So, so I think we have a lot of positive things to be excited about there. Um, but the key point, the key challenge for this new medium is that to succeed anything that causes itself, the metaverse must actually be better than all other experiences competing for people's digital time. And that's a massive challenge. This means the metaverse needs to be better than an hour on the metaverse needs to be better than an hour on Facebook or Instagram or an hour on YouTube, uh, or an hour on Netflix.
Um, it'll be actual interactive objects, actual experiences, and actual engaging things and not just ads forced upon you. And, you know, I think we can completely escape an advertising based business model if we take this approach that the only way you ever get to see a commercial thing is if you decide to see it yourself, because it's really cool. And I think we'll see a whole new level of competition among brands to surface really awesome 3d content. Um, and you know, I think you can look to Fortnite and some of these other games is pioneering. A lot of these really exciting engaging non-advertising based, uh, mechanisms for exposing stuff.
7.5.1.4 Verse Language
Now, the next question is about programming model, because if we want to have this huge shared experience with many different types of games, other entertainment experiences, or, you know, any sort of experience at all, what you're talking about is a huge amount of user generated content in the form of 3d assets and also a huge amount of user written code, um, uh, per perhaps an unprecedented amount of user written code. And, you know, there's already some evidence of models like this working.
Um, I think the web with Java script is sort of a microcosm of this. Now the web is a much simpler programming model than the metaverse will have to be because on a website, all of the code that's running in Java script on that site is nominally under the control of the website operator. You can decide exactly what code runs and you don't ever have to deal with random user code being injected that might interact with you.
Um, uh, so the web BES, a closed world programming model, whereas the metaverse will need to be an open world programming model because the goal, it can't just be another app store, right?
You can't have a thousand different experiences and you can be in one at a time. And when you're in that one experience, it dictates everything, right? The, the metaverse has gotta be about interoperability of user creative objects of all different types, right? Because, uh, besides having some core game experiences in the sort of place you're also going to have, you know, the equivalent of Facebook pages, uh, for every object that, that exists in the physical world, you know, uh, like Ford creates a new car, they're going to want to unveil the car, um, as a user drivable object, right?
Uh, in this virtual world. Um, and that's going to be a really interesting and more powerful way to unveil a car than to just announce it on your Facebook page.
Uh, in this virtual world. Um, and that's going to be a really interesting and more powerful way to unveil a car than to just announce it on your Facebook page.
The Facebook page, you can have text and video, but in the virtual world, you can actually get in the car, you can go around it, you can look at it from all different angles. You can open the doors, you can drive it, you can see how it handles. Um, and you know, you can have a, a huge set of interactions that are much more interesting and organic as it's not just a, an advertisement, uh, for a product, but also something that you can experience and have fun with. And I think we need to look at, uh, all of the crossovers that have occurred, um, in recent years between games and, um, and other brands as kind of an indicator of where the metaverse will go.
7.5.2 ROBLOX
Roblox社区太封闭:
- 不具备开放能力,没有平台开放的模式,别的应用无法调用
- 开发者之间很难共享,没有组件生态,整个开发模式还是传统封闭的app模式,每个开发者单独针对自己的app独立开发,共享复用能力不够,只是构建了一套自分发机制
相同点:
- 所有资源都是云端的,这使得多人协作更简单,不管是对于开发者还是对于用户,都没有本地资源数据,全是云端的,资源上传后Roblox 有个内容审核流程,大概几分钟
- Roblox packages, 可复用的游戏资源,游戏可以实时同步到最新版本,Roblox 的资源分享只在指定好友和组之间,切版本号相对简单,每次提交自动生成一个V1, V2, V3…之类的版本,仅能根据时间判别,功能很有限,不具备大规模协同的基础
- 多人协作编辑:用户有group的概念:My packages和Group packages ,有Collaborators的概念,他们可以编辑游戏,其他用户编辑时,选中一个物体会带不同的颜色,对于脚本,当其他人在编辑时,会有颜色提示,但是仍然可以编辑,编辑完以后会有草稿存储,提交之后可以进行合并,可以与服务器版本进行比较,解决冲突之后再提交,也可以回滚,类似版本的概念了
- Data Store用于存储需要持久化存储的数据,只能在Script而非Local Script中调用,按字典的方式存储,有版本号,可以用于一些问题定位和支持,旧版本的内容会在30天后被删除
- 引擎plug-in,用于增强引擎,marketplace ,跟其他引擎差不多
- Client-service 模式,所有之间传递的参数都是可以Replicated类型的对象,否则传递结果为空,例如Part就是不可以在Server和Client 之间进行传递的
- 所有非直接操作的物体都是物理模拟的,物理模拟可以是client或者server 计算,一般靠近用户的地方会首先在该用户的client device计算,否则在server端计算
- Roblox 在简化3D内容的层面做的很好,这样避免用户向着最高质量的内容创作,比如用方块就能描述树,使得渲染在移动端压力也少了很多
- 数据隐私保护,内容版权
缺点:
- 脚本编程模式,基本上还是Unity传统的模式,主要不同在于天生联网
- 例如脚本的挂载跟场景层级或者具体物体有关,还是像Unity原来的方式一样针对game object 编写脚本,脚本中通过script.parent引用所属对象,这天生就使得脚本与特定场景结构或物体耦合,不利于复用,可复用的脚本应该仅关注数据,而不是实际的3D物体,这种数据是逻辑数据,他就使得逻辑和表现分离出来
- 比如对于一个UI按钮的点击事件,还需要写script.Parent.MouseButton1Click:Connect(function() end())
- 脚本就等装的主要是结构,有点类似UE blueprint ,或者说定义了一些规范,一些结构,这些规范大多数针对client-server架构的一些调整,没有像Houdini 一样有些更多逻辑层面的封装
- PNC/Weapons Kit,有一套固定模版,有点类似于UE中内置的很多系统,平台提供了这些相对比较固定系统的架子,开发者往往修改的是:增加或移除某些组件;修改其中一些参数;或者基于架子代码进行定制修改。其中如果是修改的是一部分函数功能,UE提供了更好的定位方式,Roblox则更容易破坏整个体结构,但Roblox提供了基于模版代码进行定制的能力,灵活性更大,但是难度也更大,例如需要引用、读取和管理变量,寻找入口函数,处理输入输出等
- Configuration,对于NPC kit这样比较复杂的对象,由于有许多公共属性被很多脚本访问,Roblox 建议将这些公共属性存储在一个value object中,用一个Configuration container封装,这是典型传统的OOP思想,其中带来的问题有很多,比如多个对象的指针引用,比如如果某些变量被删除其中一些脚本可能不工作,也可能移除了一些脚本而某些变量压根就不被使用,核心问题就是数据和逻辑之间脱离了关系,使得需要额外小心这种关系的维护
- Roblox 中的复用问题一方面通过ModuleScript,知识代码级的复用
- Roblox 的多人在线用户数还是有限的15个人,所以还是采用比较传统的多人同步架构,没有充分发挥现代云计算的能力,比如微服务架构,允许不限制的人数
Roblox 的核心优势在于云原生,他可能会自动处理很多同步问题,例如在Script中调用Instance.new就会在workspace中创建一个Part并自动同步到在线场景,大部分的脚本都是通过Script编写的,里面特别是对Workspace中part的修改会自动同步到端侧
跟Roblox的最大区别在于,我们需要面向C端的用户,用户可能是不依赖于PC的,而Roblox的整个生态还是比较依赖于传统的游戏开发模式,其创新在于云原生和分发模式,为了实现在C端创作,需要:
- 运行时即是创作态,它比较少有编辑态的概念,像Minecraft 那样
- 需要在逻辑层面做更多的架构来支撑C端创作,有点类似于:Roblox + Houdini ,而由此衍生出来的技术和架构要比Roblox 复杂得多,但其结果是会比Roblox 在创作层面更大量的普及
7.5.3 NIANTIC
7.5.4 SNAPCHAT
7.5.5 Meta
7.5.6 Omniverse
7.5.7 Minecraft
强项在于基于像素块,可以自由组合,自由度大,可以构建任意结构的场景或物体,不依赖于DCC输出,因此真正的低门槛
缺点:
- 无法使用强大的DCC输出
- 由于像素块松散组合,通常无法对物体级设置玩法
- 每一块单独构建,手工量极大,当然有些尝试用一些DCC输出的场景体素化后作为输入
Minecraft pc 编辑器
Minecraft MOD
Minecraft 的所有内容都在本地,进度需要自己备份,分享的内容需要自己安装在本地特定的文件夹,网易的版本会做一些联网购买
使用固定的文件夹结构,很多内容混到一起,管理复杂度高,容易造成冗余资源,不方便多人协作编辑,例如每个独立的json都引入ID,这就意味着删除对应的资源还需要解析json文件,显然不可能,这使得备份也会拷贝冗余文件,如果购买了一个Pack,则在新的创作者必须全部导入该Pack,这是传统UE和Unity那种传统的本地文件资源管理方式:
- 按文件夹进行资源管理,需要开发者自己区分文件夹内资源之间的依赖关系,容易冗余
- USD是按照资源进行管理
而RealityWorld使用更加先进的USD结构
Molang: 为什么不直接让开发者写脚本?
很大的原因可能是不方便管理,因为Minecraft完全限定于数据驱动,开发者能修改的是两种:
- 组件的属性
- 组件的组合形成新的Entity
其中后者通过json的定义实现,而前者是直接在json中的对象进行赋值操作,那么如果要使用单独的脚本文件,则会涉及的数量非常大,这些脚本文件怎么关联,如果需要手动关联就引入了复杂性,例如在Roblox中需要将脚本手动关联到对应的实体,而实体之间往往还涉及层次路径结构,就会进一步复杂化,Minecraft则直接将脚本写在属性赋值的地方,简化了很多东西
但这同时也意味着开发者无法自定义行为方法,他只能是对固定的结构的值进行修改,而无法定义新的逻辑
为了访问系统内存中的游戏状态与数值,Molang提供了大量的Query function进行查询
因此Molang是一种基于表达式的语言:expression-based language
7.5.8 Wilder World
Wilder World
Liquidity
- One of the biggest problems in the NFT space is that the best content is reserved for the uber-wealthy. We are flipping this paradigm on its head by enabling fully fractionalized NFT ownership, which will not only drive more capital into the space but will make it available to a much wider audience.
No Artist Fees
- Other platforms charge artists between 15% and 30%. We consider this is an antiquated way of thinking, older world not Wilder World. Instead, we have designed our native token to create value for all participants while redistributing wealth directly back into our Wilder community. There’s no middleman or platform taking a cut of the artist’s hard earned reward.
传统没有现实价值支撑的NFT,大部分的价值来源于,有点像传销一样,转卖,早期的玩家转卖给后续的玩家,赚取差价,而后续的玩家要想赚钱,必须不断有人接龙,然后一旦到了某些不可思议的价值就不会有人接龙
7.6 区块链
7.6.1 问题
7.6.1.1 成本问题?
区块链的虚拟货币有一部分是由矿机产生的,收益归矿主,这样他们才有巨大动力和经济利益去做这件事情,也才能保证整个分布式节点可以安全运行。
显然,这:
- 不光是能源浪费
- 还是成本浪费
相当大一部分虚拟货币都分配给了矿主,来保证分布式节点的运行,必须给他们足够的利益。所以过去由中介收取的那些费用其实现在转移到矿主手上,只不过这种费用看起来不是由用户 付费的,而是给矿主的一种“代币”,他可能现阶段并不值钱,而是将来随着平台的增加而导致这种代币会升值。这是一种对将来投机的行为,如果平台没有建立起来,矿主没有任何收入。
那即使将来平台起来了,这些矿主手上的代币的实际兑现会有未来参入进来的人买单,也就是未来那些虚拟货币的购买者所支付的费用中,实际有部分是 支付给了早期的矿主或者早期流通的人。
如此下去,虚拟货币的价值将会越来越高,而后加入的人需要支付更多的支出给前面的所有人。
而如果这个平台本身并没有创造价值的话,那么这个气泡早晚会破灭。除非这个平台在这个过程中创造了新的价值,来匹配这种增长。
而且在后续的平台运行过程中,整个计算持续在运行,平台持续在给这些矿主提供更高的奖励,这种奖励是持续不断的,而且后续的奖励价值会越来越大,那么怎样才能支撑这种增长。
最终,这种为了维持(重复的)分布式节点所需要付出的高昂经济利益刺激将会使得整个经济系统难以承受,当然平台不会出什么钱,它们只需要发行一些代币,然后把生态做大,它们的收入也增大,也许它们中途在高点套现,但是当价值开始下跌的时候它们也没有什么损失,因为整个运行过程中它们并没有付出什么成本,矿主都是在为了未来资源出钱来支持这个行为和运作。
比特币的奖励机制类似于彩票的机制,只有胜出的机器才会获得比特币。当然跟彩票不同的是,这种彩票还会升值。
7.6.1.2 社区治理
7.6.1.4 系统升级
7.6.2 概念
7.6.2.1 智能合约
7.6.2.2 功能性代币
7.6.2.3 ICO
这种代币经济和开发平台的现象,正开始为我们展示一个全新的、去中心化的未来经济。初创企业正主张计算机存储平台、拼车应用、太阳能发电、以及在线广告合约等在内的产业都会被去中心化并以代币的方式进行管理。
实际上,这些数字资产甚至可能会成为人类创造及交易价值的主要方式。
7.6.2.4 DAO(去中心化自治组织)
7.7 Machinations
7.8 Render Graph
7.8.1 WorldRenderer challenges
- explicit immediate mode,显式的立即执行模式不利于统筹协调
- explicit resource management,资源管理很复杂
- tight coupling between rendering systems
- limited extensibility
- games teams must fork/diverge to customize,可复用性差
7.8.2 Modular WorldRenderer goals
- High-level knowledge of the full frame
- improved extensibility, 1) Decoupled and composable code modules; 2) automatic resource management
- Better visualizations and diagnostics
7.9 MLIR
MLIR的目标是构建可复用、可扩展的编译器基础设施,从而解决软件碎片化、异构硬件的编译、减少DSL编译器的构建时间,并将已有的编译器连接在一起。
MLIR使各个抽象层次上的代码生成、转换器、以及优化器变得简单,并且贯穿应用程序域、硬件目标、以及运行时环境。
7.9.1 介绍
编译器领域比较成熟的平台技术,一个共同的特点就是 :“one size fits all”,a single abstraction level to interface with the system:
- LLVM,is roughly "C with vectors"
- JVM,provides an "object-oriented type system with garbage collector"
与此同时,许多问题可能需要更高或者更低的层次抽象,比如说C++源代码级别的分析使用LLVM IR就会比较困难,许多语言包括Swift、Rust、Julia、Fortran等都开发了自己的IR以解决一些领域特定问题,比如一些语言/库特定的优化、一些基于流的类型检测,还有深度学习中的ML graphs等。
开发这种领域特定的IR缺乏比较程序的一些工具,自行开发的工程实现往往质量比较低、编译慢、缺乏好的调试方法、任意出bug等不稳定因素
The MLIR project1 aims to directly tackle these program- ming language design and implementation challenges—by making it cheap to define and introduce new abstraction levels, and provide “in the box” infrastructure to solve common compiler engineering problems. MLIR does this by
- (1) 把基于SSA的IR数据结构进行标准化
- (2) 提供一个定义系统用于定义IR dialect
- (3) 提供一些广泛的基础设施,包括documentation, parsing and printing logic, location tracking, multithreaded compilation support, pass management, etc.
为了解决这些问题,MLIR引入的一些系统都是基于传统的一些概念和算法之外的,这给学术研究带来了很多机会,一些 原则包括:
- Parsimony: Apply Occam’s razor to builtin semantics, concepts, and programming interface. Harness both intrin- sic and incidental complexity by abstracting properties of operations and types. Specify invariants once, but verify correctness throughout. Query properties in the context of a given compilation pass. With very little builtin, this opens the door to extensibility and customization.
- Traceability: Retain rather than recover information. Declare rules and properties to enable transformation, rather than step wise imperative specification. Extensibility comes with generic means to trace information, enforced by extensive verification. Composable abstractions stem from “glassboxing” their properties and separating their roles—type, control, data flow, etc.
- Progressivity:* Premature lowering is the root of all evil. Beyond representation layers, allow multiple transformation paths that lower individual regions on demand. Together with abstraction-independent principles and interfaces, this enables reuse across multiple domains.
贡献:
- 通过一些已经被证明的设计和工程原则,定位出用于解决可扩展和模块化的编译系统的问题
- 一个满足这些原则的全新的编译器基础设施描述
- 探索已有的引用,展示这种基础设施的通用性
Where did MLIR come from?
观察到当今的大多数深度学习框架,基本上都由一些不同的编译器、图技术、运行时 组成,并且它们之间并没有共享一些通用的基础设施或者设计原则,导致碎片化,开发成本,可维护性等等问题。
很快我们意识到编译器工业中存在相似的问题:
- 已有的系统如LLVM在不同的语言之间进行统一和集成方面非常成功,但是一些高层次的语言通常会构建自己的高层抽IR,以及为这些高层次抽象构建相似的技术
- 以此同时,LLVM社区却在挣扎于并行构造的表述,以及怎样共享前端的lowering infrastructure
7.9.2 设计原则
Little Builtin, Everything Customizable [Parsimony]
整个系统基于几个最少的基础概念,让大部分中间表述可以完全自定义。IR中最常用的一些抽象,如types、operations、以及attributes应该用来表述这些IR,这样一致性就比较好。可定制性能够适应需求的变化,因此我们应该使用一些可复用的组件来构建IR,而让语言抽象支持这些中间语言的语法和语义。
一个成功的可定制性的标准是,它有能力去表达不同的抽象,比如深度学习中的图、各种AST、数学抽象中的多态编译、控制流图(Control Flow Graph)、指令级的IR如LLVM IR等等。
当然,由于比较糟糕的兼容性抽象,可定制能力带来内部碎片化的风险,这看起来没有什么好的技术方案,但是系统应该鼓励我们设计可复用的抽象,并且假设我们设计的抽象可能会被用于超出我们初始想法的范围,以便于更好地兼容外部抽象。
SSA and Regions [Parsimony]
尽管SSA被广泛采用,它们大多是一些比较平的、线性的CFG,但是 一些 高层次的抽象却引入将嵌套的区块(nested regions)作为第一等公民。为了支持异构编译,系统 必须支持能够表达结构化的控制流、并行结构、源语言中的 闭包,以及许多其他目的。其中一个特别的挑战是使基于CFG的分析和转换组合能够基于nested region进行操作。
为此,必须要牺牲一些LVVM的一般甚至比较权威的属性。
Maintain Higher-Level Semantics [Progressivity]:
系统应该保留一些结构信息帮助下一层次进行分析和优化,这种信息应该渐进式地向下传递,结构信息的丢弃应该使得下一层抽象刚好不需要这样的结构信息。例如在transformation阶段,所有的结构化控制流信息,例如循环结构都需要保留,移除这样的信息则意味着后续不会再发生transformation操作。
这样的结构是,不同抽象层次的概念会处于同一个IR中,使得低层次的抽象可以使用高层次的一些信息来辅助进行优化。
另一个结构是系统应该支持渐进式地lowering,在多个抽象层次之间以small steps进行推进。
当前的编译器其实也已经包含了很多抽象层次。
Declaration and Validation [Parsimony and Traceability
Source Location Tracking [Traceability]
7.9.3 MLIR structure
MLIR语言用于描述high-level structure,这个结构其实是一棵树,其中的节点包含operation和operand。所有对这棵树的操作,比如 转换、优化等,都可以表示为对整个树的遍历,MLIR通过Pass来实现遍历,每个pass从某个operation开始,大多数时候最顶层的operation是ModuleOp,PassManager就被设计为限制其operation 为ModuleOp。
void runOnOperation() override {
Operation *op = getOperation();
resetIndent();
printOperation(op);
}
整个 IR是嵌套的,除了operation,还有 其他一些层次:
- operation,可以拥有一个或多个嵌套的Regions
- Region,有一个Block集合列表组成
- Block,包含一组operation的集合
一个实例数据:
visiting op: 'builtin.module' with 0 operands and 0 results
1 nested regions:
Region with 1 blocks:
Block with 0 arguments, 0 successors, and 3 operations
visiting op: 'dialect.op1' with 0 operands and 4 results
1 attributes:
- 'attribute name' : '42 : i32'
0 nested regions:
visiting op: 'dialect.op2' with 0 operands and 0 results
2 nested regions:
Region with 1 blocks:
Block with 0 arguments, 0 successors, and 1 operations
visiting op: 'dialect.innerop1' with 2 operands and 0 results
0 nested regions:
Region with 3 blocks:
Block with 0 arguments, 2 successors, and 2 operations
visiting op: 'dialect.innerop2' with 0 operands and 0 results
0 nested regions:
visiting op: 'dialect.innerop3' with 3 operands and 0 results
0 nested regions:
Block with 1 arguments, 0 successors, and 2 operations
visiting op: 'dialect.innerop4' with 0 operands and 0 results
0 nested regions:
visiting op: 'dialect.innerop5' with 0 operands and 0 results
0 nested regions:
Block with 1 arguments, 0 successors, and 2 operations
visiting op: 'dialect.innerop6' with 0 operands and 0 results
0 nested regions:
visiting op: 'dialect.innerop7' with 0 operands and 0 results
0 nested regions:
0 nested regions:
7.9.4 LLVM IR、SPIR-V、MLIR
7.9.4.1 LLVM IR
IR只是程序的一种中间表示,其设计注重支持变换操作。
IR的三种形态:
- 内存表示,用于高效的分析与变换
- 字节码:用于存储和交换
- 文本表示:用于 阅读和纠错
LLVM的不足:
- 中心化和各种衍生:LLVM IR是前后端解耦的基础,处于核心/中心地位,完整的编译路径必须经过LLVM IR,导致其进化缓慢
- 演进与兼容性:驱动的升级通常无法得到保证,因此驱动依赖的LLVM IR库也可能永远得不到升级
7.9.4.2 SPIR-V
SPIR-V是Khronos API共用的中间语言,包括Vulkan,OpenGL,OpenCLass等,Khronos group的标语是:链接软件与硬件。
LLVM IR相对于SPIR-V有两个方面的不同:
- SPIR-V有比较好的版本管理和扩展管理,也有稳定的字节码表示
- SPIR-V主要用于驱动内部的二次编译(在线编译)
稳定的字节码,完整的 GPU 编译器被分为两部分——首先通过离线工具链从高层次源代码生成 SPIR-V,然后通过驱动内部编译器将 SPIR-V 在线编译成机器码。虽然像 LLVM IR 一样在整个编译流程中处于“中间”位置,SPIR-V 更侧重于驱动内部二次编译的高效,因为这一步在运行时进行。所以 SPIR-V 的核心是其字节码。其编码有很多简化驱动二次编译的考量,像是用各种提前的显示声明来避免运行时复杂的分析。SPIR-V 并没有在规范中指定内存表示或者文本表示,这些都是实现 SPIR-V 标准规范的工具链自行定义的。比如 SPIRV-Tools 有其自己的内存表示和文本表示, 同样 MLIR 中的 SPIR-V dialect 也是。
GPU领域专用:其实 SPIR-V 的 IR 部分和 LLVM IR 相差并不太大。SPIR-V 借鉴了很多 LLVM IR 的设计——它同样是由控制流、基本块、以及静态单赋值来表示程序。指令的粒度和 LLVM IR 也相差不大。SPIR-V 中独特的部分在于对很多 GPU 概念的原生支持。这种支持通过很多 SPIR-V 独有的机制来实现,比如 decorations, builtins, 以及特殊的指令(像是导数计算、图像取样)。另外为了支持图形图像和高性能计算的两种使用场景, SPIR-V 中有许多执行模型和模式。当然,对图形图像也有 structured control flow 的特殊需求。
7.9.4.3 MLIR
一个 GPU 为主的标准规范需要原生支持各种 GPU 概念,能够提供不同等级的扩展需求, 以及提供稳定和兼容的字节码。这些需求并不符合 LLVM IR 的设计理念,所以 Khronos Group 推出了 SPIR-V。但是设计一套中间表示只是个开始,围绕其开发和维护整套工具链需要持续不断的工程投入。SPIR-V 与 LLVM IR 完全无关,SPIR-V 的编译器栈无法利用现有的 LLVM 库。所以 SPIR-V 的整个栈是从头开始独立开发的,从汇编、反汇编,一步步到各种语言的编译器和优化。而MLIR恰好可以帮助解决这个问题。
基础设施化 (infrastructurization),MLIR 是用来开发编译器基础设施。它提供一系列可复用的易扩展的基础组件,用来搭建领域专用编译器。在 LLVM IR 和 SPIR-V 中,我们有唯一的中间表示,其中含有完备的指令集来编译所有的 CPU 和 GPU 程序。MLIR 中则没有完全处于中心地位的中间表示。MLIR 提供基础设施来帮助定义 operation 以及将逻辑相关的 operation 组合成 dialect。另外,MLIR 也提供一些普适的 pattern 或者 pass,这些 pattern 或者 pass 并不与具体的 operation 绑定,能够自适应。
无论是对 operation 还是 pattern/pass 的支持都要求 MLIR 以更加细的粒度看待编译器。在 MLIR 中,operation 不再是最基础的部件,粒度进一步细化到类型, 值, attribute, region, 以及 interface (例如 attribute/type/operation interface).[8]
Operation 可以有任意数量的输入、输出、attribute,并包含任意数量的 region。其中 region 能够表示 operation 之间的嵌套关系,从而简化编译器的分析和转换。Operation 可以实现 operation interface,pattern 和 pass 绑定的是 operation interface,由此而实现与具体 operation 的解绑并做到自适应。
MLIR 里面的概念都设计的比较抽象,目的是能比较好地映射到不同的领域和场景。
Dialects, dialects, dialects,当然,这套基础设施存在的目的是帮助搭建最终编译器。我们在写 C++ 程序的的时候会调用 STL 或者更加高层次的库,很少会从头开始实现所有的细节。另外,基础设施也需要与其支持的领域协同发展,因为使用场景中会提供很多需求。因此,MLIR 代码库中自带很多用来给各种层级概念建模的 dialect。[9]
MLIR 的 dialect 生态目前还在扩张演进阶段,但 dialect 之间的组织结构以及有些 dialect 已经相对稳定了。比如我们有 LLVM 和 SPIR-V dialect 作为与其他系统转换的边界 dialect。(其实 MLIR 可以同时表示 LLVM IR 和 SPIR-V 这一点也表明了 MLIR 的基础设施角色。) 抽象层次居中的有 Linalg, Tensor, Vector, SCF dialect,它们协同合作用来生成代码。另外,MLIR 中还有 Affine, Math, Arithmetic dialect 用来描述底层计算。在 AI 框架层面,有 TensorFlow, TFLite, MHLO, Torch, TOSA 进行对接和导入模型。除此之外,还有很多其他用途的 dialect,像是 PDL 用来定义编译器转换等等。
Alex 之前在 MLIR 论坛上分享的各 dialect 之间的关系[10]非常值得一读,之后我也会写下我的理解。这些各式各样的 dialect 和以后包装它们而产生的局部或者完整的转换流程将极大简化领域相关编译器的开发。
进一步解耦编译器和中间表示:其实基础设施化以及由此产生的大量 dialect 都是进一步解耦和模块化编译器以及中间表示的一种自然结果。唯一的中间表示被许多以 dialect 形态存在的部分的中间表示取代。没有某个部分中间表示再处于中心地位,都是按需组合。
另外,进一步解耦中间表示也让我们可以灵活地根据领域进行设计和折中。我们只需选取所需的部分中间表示来组合成完整编译器,不再需要全盘接收像 LLVM IR 一样的一套完整中间表示。因为 interface 的存在,扩展模块的更能也变得更加简单——我们既可以定义新的 operation 来实现已有的 interface,也可以定义新的 interface 然后支持现有 operation。
换言之,LLVM IR 天然中心化并且偏好统一的编译流程,MLIR 的基础设施和 dialect 生态则天然是去中心化并且偏好离散的编译流程。
技术的一般发展趋势是从单一的强耦合整体到适用不同场景的多种多样的选择。对于技术栈的上层而言,这尤其明显,因为越往上越接近用户和商业需求,而用户和商业需求本身就各式各样,由层出不穷的前端框架可见一斑。
技术栈的底层一般相对稳定。少数几种硬件架构、编译器和操作系统统治很多年。但半导体进展的变慢和计算需求的爆炸式增长也在驱动着底层技术的变革。现在依然依靠通用架构和普适优化很难再满足各种需求,开发领域专用的整体的解决方案是一条出路。RISC-V 在芯片指令集层次探索模块化和定制化,MLIR 则是在编译器以及中间表示层面做类似探索。两者联手会给底层技术栈带来何种革新是一个值得拭目以待的事情。
跨系统边界的渐进式代码表示递降
在结束本章之前,再啰嗦最后一点。其实我们可以从两个维度看待 MLIR 带来的解耦:
水平方向上,dialect 把完整中间表示打散成许多局部中间表示;垂直方向上,MLIR 让我们可以对处于不同层级的概念进行建模。这对领域专用编译器是非常有用的,因为领域专用语言一般是高度抽象的声明式语言,只描述任务,需要编译器将其转换成具体的命令式机器指令。一步跨越这个巨大的抽象差距是非常难的,利用多级抽象和建模来进行渐进式 lowering 是更加适合的方式。我们可以分离各个层次关注的问题,整个系统也更加的易开发和维护。
当然这并不是什么全新的概念,在不同的项目中我们已然看到各种类中间表示的设置,像是 Clang AST 或者各种机器学习框架中的计算图。MLIR 的优势是使用同样的基础设施将这些不同层次的表示连接起来,让它们之间的信息流通变得更加顺畅。其实现代复杂系统的开发多是选取各种子系统然后将其组合。将来自前一个子系统的数据进行验证、转化然后传递给下一个子系统消耗掉很多工程资源。如果所有子系统使用相同的内部基础设施,这些资源投入就都可以节省下来,另外,使用相同工具也会使得跨组跨项目的沟通协调变得更加简单。
7.9.5 MLIR Dialect
7.9.5.1 基础组件
一个 dialect 基本可以理解为一个命名空间。 在这个命名空间中,我们可以定义一系列互补协作的操作,和这些操作所需的类型 (type) 以及属性 (attribute) 等等。 特定的机器学习编译器只需要组合现有的 dialect,并加以自己的扩展或者定制。
内嵌结构的操作(Operations carrying structures)
MLIR 中操作的一个突出特性是可以通过region[2]来内嵌 (nest) 结构 (structure)。MLIR 中很多可以添加负载操作 (payload op) 的结构化操作 (structured op) 都依赖于这种特性。这些结构化操作本身只定义某种结构性语义,比如控制流 (control flow)。具体的计算性语义则来自于添加的负载操作。结构化操作与负载操作相互组合、相互扩展。一个突出的例子是 linalg.generic op;当然函数 (function) 以及模块 (module) 其实都是这种结构化操作。Region 给负载操作设置了明确的边界,这有助于简化中间表示转换时所需的模式匹配。
代表抽象层次的类型(Types signaling abstraction levels)
操作归根到底只是针对某种类型的值 (value) 所进行的某种计算 (computation)。类型才是抽象层次 (abstraction level) 的代表。举个栗子,张量 (tensor)、buffer、以及标量 (scalar) 都可以支持加减乘除等各种操作。这些操作在本质上并没有多少区别,但它们明显属于不同的抽象层次。张量存在于机器学习框架或者编程模型 (programming model) 这一高层抽象。Buffer 存在于执行系统 (system) 和内存体系 (memory hierarchy) 这一中层抽象。标量存在于执行芯片 (chip) 和寄存器 (register) 这一底层抽象。
一个 dialect 可以自由地定义各种类型。 MLIR 的核心基础设施会无差别地对待以及用统一的机制支持来自不同 dialect 的类型。 比如,type conversion [3]就是通用的转换类型的机制。 Dialect A 可以重用来自 dialect B 的类型,也可以对其进一步扩展和组合,例如将基础类型 (primitive type) 放入容器类型中 (container type)。 一个 dialect 也可以定义规则来实现自身类型和其他 dialect 类型的相互转换。 把这些规则加入到 type converter 中后,所有的规则会相互组合,由此 type conversion 机制会自行找出转换通路来实现转换。 不过总而言之,相较于操作的组合与转换,类型的组合以及转换通常有更多限制也更加复杂,毕竟类型的匹配奠定了操作可以衔接的基础。
不同建模粒度的Dialect(Dialects as modeling granularity)
通过定义和组织操作和类型,dialect 给编译器提供了粗粒度高层次的建模方式。如果两个 dialect 所涉及的类型相同,那么它们基本属于统一抽象层次。另一方面,对涉及不同类型的 dialect 进行转换本质上则是转换不同的抽象层次。
为简化实现,我们一般将高层次 (high-level) 抽象递降 (lower) 到低层次 (low-level) 抽象。递降的过程通常会进行某种形式的问题分解 (decomposition) 或者资源分配 (resource assignment) 来逐渐贴近底层硬件。前者的例子有 tiling, vectorization 等等;后者的例子有 bufferization, 寄存器分配 (register allocation) 等等。即便如此,递降依然不是一个简单的问题,因为不同的抽象层次有不同的目的以及对正确性和性能的理解。比如编程模型层考虑的是代码的表示能力以及简洁性,很少涉及具体硬件特性;而硬件层考虑的是资源的最佳使用,很少考虑易于编程。因此,在诸多 MLIR 机制中,dialect conversion [4]可能是最复杂的就并不奇怪了。
7.9.5.2 Dialect体系
以操作和类型的可组合性以及可扩展性为基础,dialect可以作为组合机器学习编译器的高层次基础组件。
7.9.5.3 Operations
一个operation类继承于mlir::Op类,其中mlir::Op类携带一些可选的traits来自定义一些行为,Traits提供一种机制,使得我们可以对一个Operation注入一些行为,例如额外的accessors、verification等等:
class ConstantOp : public mlir::Op<
/// `mlir::Op` is a CRTP class, meaning that we provide the
/// derived class as a template parameter.
ConstantOp,
/// The ConstantOp takes zero input operands.
mlir::OpTrait::ZeroOperands,
/// The ConstantOp returns a single result.
mlir::OpTrait::OneResult,
/// We also provide a utility `getType` accessor that
/// returns the TensorType of the single result.
mlir::OpTraits::OneTypedResult<TensorType>::Impl> {
public:
/// Inherit the constructors from the base Op class.
using Op::Op;
/// Provide the unique name for this operation. MLIR will use this to register
/// the operation and uniquely identify it throughout the system. The name
/// provided here must be prefixed by the parent dialect namespace followed
/// by a `.`.
static llvm::StringRef getOperationName() { return "toy.constant"; }
/// Return the value of the constant by fetching it from the attribute.
mlir::DenseElementsAttr getValue();
/// Operations may provide additional verification beyond what the attached
/// traits provide. Here we will ensure that the specific invariants of the
/// constant operation are upheld, for example the result type must be
/// of TensorType and matches the type of the constant `value`.
LogicalResult verifyInvariants();
/// Provide an interface to build this operation from a set of input values.
/// This interface is used by the `builder` classes to allow for easily
/// generating instances of this operation:
/// mlir::OpBuilder::create<ConstantOp>(...)
/// This method populates the given `state` that MLIR uses to create
/// operations. This state is a collection of all of the discrete elements
/// that an operation may contain.
/// Build a constant with the given return type and `value` attribute.
static void build(mlir::OpBuilder &builder, mlir::OperationState &state,
mlir::Type result, mlir::DenseElementsAttr value);
/// Build a constant and reuse the type from the given 'value'.
static void build(mlir::OpBuilder &builder, mlir::OperationState &state,
mlir::DenseElementsAttr value);
/// Build a constant by broadcasting the given 'value'.
static void build(mlir::OpBuilder &builder, mlir::OperationState &state,
double value);
};
然后这个operation可以注册给ToyDialect:
void ToyDialect::initialize() {
addOperations<ConstantOp>();
}
现在我们已经定义了一个operation,那么怎样获取它以及对其进行转换呢?
在MLIR中有两根跟operation相关的类:
- Operation:它用于通用地model all operations,它是不透明的,意味着它不会描述任何operation的属性或者类型;反之,它提供对一个operation实例的通用API。
- OP:每个特定类型的operation继承自Op,这些继承自Op的类像一个指向一个Operation*的智能指针,提供一些特定于某个操作的accessor方法、类型检查等等。这意味着,当我们给Toy定义一个 operation时,我们实际上是在定义一组干净、包含一些有用语义的接口,通过这些接口可以构建Operation并与之进行交互(interfaing)。这就是为什么继承自Op的类不包含任何类字段(class field),所有围绕整个operation的数据都存储在引用 的Operation中。这带来的其中一个要求是,所有的Op类的传值都应该是值类型,而不能 是指针或者引用类型。
给定一个通用的Operation*实例,我们总是可以获取到一个特定的Op实例,可以使用LLVM提供的转换方法:
void processConstantOp(mlir::Operation *operation) {
ConstantOp op = llvm::dyn_cast<ConstantOp>(operation);
// This operation is not an instance of `ConstantOp`.
if (!op)
return;
// Get the internal operation instance wrapped by the smart pointer.
mlir::Operation *internalOperation = op.getOperation();
assert(internalOperation == operation &&
"these operation instances are the same");
}
Operation Definition Specification(ODS)
使用TableGen的方式定义
// Base class for toy dialect operations. This operation inherits from the base
// `Op` class in OpBase.td, and provides:
// * The parent dialect of the operation.
// * The mnemonic for the operation, or the name without the dialect prefix.
// * A list of traits for the operation.
class Toy_Op<string mnemonic, list<Trait> traits = []> :
Op<Toy_Dialect, mnemonic, traits>;
然后定义operation:
def ConstantOp : Toy_Op<"constant"> {
// Provide a summary and description for this operation. This can be used to
// auto-generate documentation of the operations within our dialect.
let summary = "constant operation";
let description = [{
Constant operation turns a literal into an SSA value. The data is attached
to the operation as an attribute. For example:
%0 = "toy.constant"()
{ value = dense<[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]> : tensor<2x3xf64> }
: () -> tensor<2x3xf64>
}];
// The constant operation takes an attribute as the only input.
// `F64ElementsAttr` corresponds to a 64-bit floating-point ElementsAttr.
let arguments = (ins F64ElementsAttr:$value);
// The generic call operation returns a single value of TensorType.
// F64Tensor corresponds to a 64-bit floating-point TensorType.
let results = (outs F64Tensor);
// Add additional verification logic to the constant operation. Setting this bit
// to `1` will generate a `::mlir::LogicalResult verify()` declaration on the
// operation class that is called after ODS constructs have been verified, for
// example the types of arguments and results. We implement additional verification
// in the definition of this `verify` method in the C++ source file.
let hasVerifier = 1;
// Add custom build methods for the constant operation. These methods populate
// the `state` that MLIR uses to create operations, i.e. these are used when
// using `builder.create<ConstantOp>(...)`.
let builders = [
// Build a constant with a given constant tensor value.
OpBuilder<(ins "DenseElementsAttr":$value), [{
// Call into an autogenerated `build` method.
build(builder, result, value.getType(), value);
}]>,
// Build a constant with a given constant floating-point value. This builder
// creates a declaration for `ConstantOp::build` with the given parameters.
OpBuilder<(ins "double":$value)>
];
}
7.9.6 Analysis and Transformation
本节介绍怎样利用Toy Dialect及其高层次语义来执行local pattern-match transformations,这个过程在LLVM中会很困难。
有两种方法可以用于实现pattern-match transformation:
- imperative C++ pattern-match and rewrite
- declarative,rule-based pattern-match and rewrite using table-driven Declarative Rewrite Rules(DDR),此时operation必须是使用ODS定义的
7.9.6.1 C++ style pattern-match and rewrite
例如我们可以优化转置的转置,这个操作可以直接返回x,而不需要执行任何转置操作:
def transpose_transpose(x) {
return transpose(transpose(x));
}
正常的IR是这样:
toy.func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%0 : tensor<*xf64>) to tensor<*xf64>
toy.return %1 : tensor<*xf64>
}
这样的情况对于LLVM来说是很难的,例如Clang不能优化掉临时数组,以及相应的转置计算:
#define N 100
#define M 100
void sink(void *);
void double_transpose(int A[N][M]) {
int B[M][N];
for(int i = 0; i < N; ++i) {
for(int j = 0; j < M; ++j) {
B[j][i] = A[i][j];
}
}
for(int i = 0; i < N; ++i) {
for(int j = 0; j < M; ++j) {
A[i][j] = B[j][i];
}
}
sink(A);
}
为了实现上述的操作,这涉及到在IR中匹配一个tree-like的模式,并且将其替换为一组新的operation。we can plug into the MLIR Canonicalizer pass by implementing a RewritePattern:
/// Fold transpose(transpose(x)) -> x
struct SimplifyRedundantTranspose : public mlir::OpRewritePattern<TransposeOp> {
/// We register this pattern to match every toy.transpose in the IR.
/// The "benefit" is used by the framework to order the patterns and process
/// them in order of profitability.
SimplifyRedundantTranspose(mlir::MLIRContext *context)
: OpRewritePattern<TransposeOp>(context, /*benefit=*/1) {}
/// This method is attempting to match a pattern and rewrite it. The rewriter
/// argument is the orchestrator of the sequence of rewrites. It is expected
/// to interact with it to perform any changes to the IR from here.
mlir::LogicalResult
matchAndRewrite(TransposeOp op,
mlir::PatternRewriter &rewriter) const override {
// Look through the input of the current transpose.
mlir::Value transposeInput = op.getOperand();
TransposeOp transposeInputOp = transposeInput.getDefiningOp<TransposeOp>();
// Input defined by another transpose? If not, no match.
if (!transposeInputOp)
return failure();
// Otherwise, we have a redundant transpose. Use the rewriter.
rewriter.replaceOp(op, {transposeInputOp.getOperand()});
return success();
}
};
transformation主要在operation canonicalization pass被执行,canonicalization是MLIR的一个重要阶段,能够对代码的好坏进行一些推理,执行reliable compiler transformation。为了保证canonicalization能够应用我们的new transform,需要设置hasCanonicalizer=1,并且将我们的pattern注册到canonicalization框架中:
// Register our patterns for rewrite by the Canonicalization framework.
void TransposeOp::getCanonicalizationPatterns(
RewritePatternSet &results, MLIRContext *context) {
results.add<SimplifyRedundantTranspose>(context);
}
同时我们需要给编译器增加一个optimization pipeline,MLIR通过 一个PassManager管理 :
mlir::PassManager pm(module.getContext());
pm.addNestedPass<mlir::toy::FuncOp>(mlir::createCanonicalizerPass());
最终优化的IR代码如下:
toy.func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
toy.return %arg0 : tensor<*xf64>
}
7.9.6.2 总结
在这里,整个过程以Operation为中心,Operation是IR的基本元素,其包含的是代码的基本组织元素,这里通过对代码的结构进行分离来进行优化,而优化或者transformation的逻辑,其实也就是对Operation进行改写,它通过对Operation进行(暴力)模式匹配,这跟传统编译器对AST的分析过程是类似的,只不过MLIR使用一种特定的结构来表示任意的IR,这个IR可有用户自定义,而不是一个固定的IR结构,然后由于各个Dialect了解其中的构成,例如Operation,因此就可以对其进行特定的操作,最终修改的其实是MLIR的结构,这种修改是由特定的Dialect实例进行执行的。MLIR系统设置一个注册管理的机制,让各个Dialect进行自定义处理。
MLIR为编译器的编译器,它的Operation实际上是结构,而不是实际运行时执行的代码方法,因此它没有变量,只有结构,这个结构被表述为一种格式,它可以是in memory的,也可以是文本的,所有那些关于分析、优化、变换的操作其实也是在修改这个IR结构,当然 主要通过Operation为单位进行,而不是LLVM IR中的单条指令为单位。由于Dialect或者Operation包含更高层的抽象信息,因此优化的空间更大。
7.9.7 Generic Transformation with Interfaces
7.9.8 Lowering
Tensors represent an abstract value-typed sequence of data, meaning that they don’t live in any memory. MemRefs, on the other hand, represent lower level buffer access, as they are concrete references to a region of memory.
7.9.8.1 Dialect Conversions
需要至少两个元素:
- A Conversion Target
- This is the formal specification of what operations or dialects are legal for the conversion. Operations that aren’t legal will require rewrite patterns to perform legalization.
- A set of Rewrite Patterns
- This is the set of patterns used to convert illegal operations into a set of zero or more legal ones.
- Optionally, a Type Converter.
- If provided, this is used to convert the types of block arguments.
Conversion Target
这里我们将计算比较重的Toy操作转化为来自多个dialect中操作的集合:Affine、Arith、Func以及MemRef,以便进行进一步优化,首先定义conversion target:
void ToyToAffineLoweringPass::runOnOperation() {
// The first thing to define is the conversion target. This will define the
// final target for this lowering.
mlir::ConversionTarget target(getContext());
// We define the specific operations, or dialects, that are legal targets for
// this lowering. In our case, we are lowering to a combination of the
// `Affine`, `Arith`, `Func`, and `MemRef` dialects.
target.addLegalDialect<AffineDialect, arith::ArithDialect,
func::FuncDialect, memref::MemRefDialect>();
// We also define the Toy dialect as Illegal so that the conversion will fail
// if any of these operations are *not* converted. Given that we actually want
// a partial lowering, we explicitly mark the Toy operations that don't want
// to lower, `toy.print`, as *legal*. `toy.print` will still need its operands
// to be updated though (as we convert from TensorType to MemRefType), so we
// only treat it as `legal` if its operands are legal.
target.addIllegalDialect<ToyDialect>();
target.addDynamicallyLegalOp<toy::PrintOp>([](toy::PrintOp op) {
return llvm::none_of(op->getOperandTypes(),
[](Type type) { return type.isa<TensorType>(); });
});
...
}
Conversion Patterns
跟Canonicalization框架有点类似,DialectConversion也使用RewritePatterns来执行转化逻辑。可以使用两种pattern:
- RewritePattern
- ConversionPatterns,主要的区别是接受一个额外的参数:operands,这些operands可能是之前被移除或者被重新映射的操作数,因为一些操作需要对旧的信息进行匹配
/// Lower the `toy.transpose` operation to an affine loop nest.
struct TransposeOpLowering : public mlir::ConversionPattern {
TransposeOpLowering(mlir::MLIRContext *ctx)
: mlir::ConversionPattern(TransposeOp::getOperationName(), 1, ctx) {}
/// Match and rewrite the given `toy.transpose` operation, with the given
/// operands that have been remapped from `tensor<...>` to `memref<...>`.
mlir::LogicalResult
matchAndRewrite(mlir::Operation *op, ArrayRef<mlir::Value> operands,
mlir::ConversionPatternRewriter &rewriter) const final {
auto loc = op->getLoc();
// Call to a helper function that will lower the current operation to a set
// of affine loops. We provide a functor that operates on the remapped
// operands, as well as the loop induction variables for the inner most
// loop body.
lowerOpToLoops(
op, operands, rewriter,
[loc](mlir::PatternRewriter &rewriter,
ArrayRef<mlir::Value> memRefOperands,
ArrayRef<mlir::Value> loopIvs) {
// Generate an adaptor for the remapped operands of the TransposeOp.
// This allows for using the nice named accessors that are generated
// by the ODS. This adaptor is automatically provided by the ODS
// framework.
TransposeOpAdaptor transposeAdaptor(memRefOperands);
mlir::Value input = transposeAdaptor.input();
// Transpose the elements by generating a load from the reverse
// indices.
SmallVector<mlir::Value, 2> reverseIvs(llvm::reverse(loopIvs));
return rewriter.create<mlir::AffineLoadOp>(loc, input, reverseIvs);
});
return success();
}
};
然后将pattern添加到lowering process中:
void ToyToAffineLoweringPass::runOnOperation() {
...
// Now that the conversion target has been defined, we just need to provide
// the set of patterns that will lower the Toy operations.
mlir::RewritePatternSet patterns(&getContext());
patterns.add<..., TransposeOpLowering>(&getContext());
// With the target and rewrite patterns defined, we can now attempt the
// conversion. The conversion will signal failure if any of our *illegal*
// operations were not converted successfully.
if (mlir::failed(mlir::applyPartialConversion(getOperation(), target, patterns)))
signalPassFailure();
}
实例
以下的IR:
toy.func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%2 = toy.transpose(%0 : tensor<2x3xf64>) to tensor<3x2xf64>
%3 = toy.mul %2, %2 : tensor<3x2xf64>
toy.print %3 : tensor<3x2xf64>
toy.return
}
被转换为(其中包含一些Affine优化):
func.func @main() {
%cst = arith.constant 1.000000e+00 : f64
%cst_0 = arith.constant 2.000000e+00 : f64
%cst_1 = arith.constant 3.000000e+00 : f64
%cst_2 = arith.constant 4.000000e+00 : f64
%cst_3 = arith.constant 5.000000e+00 : f64
%cst_4 = arith.constant 6.000000e+00 : f64
// Allocating buffers for the inputs and outputs.
%0 = memref.alloc() : memref<3x2xf64>
%1 = memref.alloc() : memref<2x3xf64>
// Initialize the input buffer with the constant values.
affine.store %cst, %1[0, 0] : memref<2x3xf64>
affine.store %cst_0, %1[0, 1] : memref<2x3xf64>
affine.store %cst_1, %1[0, 2] : memref<2x3xf64>
affine.store %cst_2, %1[1, 0] : memref<2x3xf64>
affine.store %cst_3, %1[1, 1] : memref<2x3xf64>
affine.store %cst_4, %1[1, 2] : memref<2x3xf64>
affine.for %arg0 = 0 to 3 {
affine.for %arg1 = 0 to 2 {
// Load the transpose value from the input buffer.
%2 = affine.load %1[%arg1, %arg0] : memref<2x3xf64>
// Multiply and store into the output buffer.
%3 = arith.mulf %2, %2 : f64
affine.store %3, %0[%arg0, %arg1] : memref<3x2xf64>
}
}
// Print the value held by the buffer.
toy.print %0 : memref<3x2xf64>
memref.dealloc %1 : memref<2x3xf64>
memref.dealloc %0 : memref<3x2xf64>
return
}
7.9.9 Lowering to LLVM
7.9.10 MLIR Language
MLIR是基于graph-like的数据结构,其中:
- nodes,称为Operations
- edges,称为Values
每个Value是一个Operation或者BLock的返回值参数,其中Value Type使用类型系统进行定义。Operation包含 Region,Region包含Block,Block又包含Operation,形成嵌套结构,其中的集合的顺序由其结构决定,尽管这种顺序不一定有语义上的意义。
Operation可以表述许多不同的概念,从高抽象层级的概念如函数定义、函数调用、buffer分配等等,到低层次的跟数学、指令、寄存器相关的概念等等。这种不同的概念都可以使用MLIR中的operation表示,使得MLIR可以被任意扩展。
MLIR同时还提供一个可扩展的框架用于实现operation的变换,这使用编译器中常用的Pass的概念实现,在任意的operation集合上实现任意的pass导致伸缩性的问题,因为每个Transformation必须考虑每个operation的语义。MLIR通过使用Traits和Interfaces来抽象地描述operation semantics来克服这个问题,使得Transformation在operation上的操作是更加通用的。其内部使用模式匹配来进行筛选。
7.9.10.1 Dialects
Dialects are the mechanism by which to engage with and extend the MLIR ecosystem. They allow for defining new operations, as well as attributes and types. Each dialect is given a unique namespace that is prefixed to each defined attribute/operation/type. For example, the Affine dialect defines the namespace: affine.
MLIR allows for multiple dialects, even those outside of the main tree, to co-exist together within one module. Dialects are produced and consumed by certain passes. MLIR provides a framework to convert between, and within, different dialects.
7.9.11 Pattern Rewriting
This document details the design and API of the pattern rewriting infrastructure present in MLIR, a general DAG-to-DAG transformation framework. This framework is widely used throughout MLIR for:
- canonicalization,
- conversion, and
- general transformation.
7.10 AI
7.10.1 Apple Shortcuts
什么是快捷指令?
快捷指令可让你使用 App 快速完成任务,只需轻点一下或询问 Siri 即可。快捷指令可以自动化各种任务,例如,获取前往“日历”上下一个日程的路线、将文本从一个 App 移到另一个 App、生成支出报告等。
基于你使用 Apple 设备的方式(App 使用以及浏览器、电子邮件和信息历史记录),Siri 会建议简单实用的快捷指令,快速轻点即可运行。创建快捷指令后,你可以激活 Siri,然后说出快捷指令的名称以运行它。除了运行 Siri 建议的简单快捷指令外,你还可以使用“快捷指令” App 将现有快捷指令或自定快捷指令添加到设备。该 App 可让你合并多个 App 间的多个步骤,以创建功能强大的任务自动化。
什么是操作?
操作是快捷指令的组成部分。每一个快捷指令皆由一系列操作组成,每一个操作即为执行特定功能的一个步骤。例如,共享动画 GIF 的快捷指令可能包含三个连续的操作:“获取最新的照片”会抓取使用设备拍摄的最新照片,“制作 GIF”使用这些照片构建动画 GIF,“发送信息”会自动将 GIF 发送给收件人。
通过分解成较小的部分,操作可实现 Apple 设备上 App 的最佳功能。通过数百个操作,你可以将各种单独的步骤链接在一起以构建快捷指令。
什么是自动化?
自动化是一种由事件激活的快捷指令,而非手动启动。你可以使用“快捷指令” App 设置个人或家庭自动化,然后通过到达、离开、更改 iPhone 上的设置和一天中的某个时间等事件触发自动化快捷指令。
7.11 Slack
8. Programming Language
8.1 Script languages
8.1.1 SkookumScript
SkookumScript uses a multi-pass compiler to determine what files and components are needed, and automatically manages them in the memory of the parser and runtime, so aspects such as dependencies are always up-to-date.
8.1.1.1 Time-flow logic
Coroutines and methods
Commands that may take time (multiple frames) to complete are called coroutines and have identfier names that must start with an underscore _. Commands that start without an underscore such as println() complete immediately (within the same frame) and are called methods.
7.1.1.2 Conditional flow control
8.1.2 Lua
It provides "meta language" features. You can implement object-oriented structures, or pure procedural functions, etc. It has a very simple C interface, and gives the engine developer a lot of flexibility in the language itself.
Artists tend to love Lua too because it's very approachable, with plain and forgiving syntax. If your codebase is C or C++, I would highly recommend it.
It has good runtime performance when compared to other scripting languages like Python. (...and it has full support for closures.)
It has a small memory footprint (approx 150k), it has excellent C/C++ bindings making it easy to add new game specific APIs, it is easy to pick up, it is flexible - i.e Has elements of OO, imperative and functional - none of which are mandatory, it has good buy-in from from mod community from games such as WoW etc.
简单的说,register-based的指令格式设计把stack-based的指令中分几条指令要完成的事情用一条指令搞定了,快当然是快了,难度也加大了。
另外还有一点上面的回答中似乎没有提到,Lua使用的是一遍遍历就生产指令的方式,学过编译原理的,大概都能知道一般分两遍遍历,第一遍生成AST,再一遍遍历AST生成指令,而在Lua中是直接跳过了AST指令这一步的。
还是那句话,快是快了,代码的实现难度也大了些。最早的Lua解释器,也是使用lex、yacc这样的工具来自动生成代码的,后来为了提升性能,作者改成了自己手写的递归下降的分析器。这部分代码是我认为Lua代码中最难理解的一个部分了--因为它要一遍分析干太多的事情了。
我在阅读Lua代码的过程中,能充分感受到作者为了Lua在性能上的提升花费的心血,致敬。
抛开理论不谈,如果要在 Lua 中实践,我们到底可以做点什么呢?
我认为需要有这几个方面:
首先应该对 Lua 加强类型系统。Lua 的动态性天然支持把不同的组件聚合在一起,我们把不同的 Component 放在一张表里组合成 Entity 就足够了。但如果 Component 分的很细的话,用很多的表组合成一个 Entity 对象的额外开销不小。不像 C++ ,结构体聚合的额外开销几乎为零。我们完全可以把不同 Component 的数据直接平坦放在一个 table 中,只要键值不冲突即可。但是我们需要额外的类型信息方便运行时从 Entity 中萃取出 Component 来。另外,如果是 C / Lua 混合设计的话,某些 Component 还应该可以是 userdata 。
从节省空间及方便遍历的角度讲,我们甚至可以把同类的 C Component 聚合在一大块内存中,然后在 Entity 的 table 中只保留一个 lightuserdata 即可。ECS 的 System 最重要的操作就是遍历处理同类 Component ,这样天然就可以分为 C System 和 Lua System 。数据的内聚性很高,可以直接区分开 C data 和 Lua Data 。
然后、就是方便的遍历。ECS 的 System 需要做的就是筛选出它关心的 Entity ,针对其中的 Component 做操作。如果需要筛选结果大大少于全体 Entity 数量,遍历逐个判断就会效率很低。好在在 Lua 中,我们可以非常容易地做出 cache ,只需要遍历筛选一次,在监控新的 Component 的诞生就可以方便的维护遍历用的集合了。
Squirrel
受lua影响最大,但风格是C/C++风格的,在lua基础上添加了class,array等
http://squirrel-lang.org/#overview
V8 JavaScript from Google
8.1.3 GameMonkey
This one is used by several teams. It's faster than Lua and better at threading.
没有维护了
8.1.4 Python
This one has been used in several games (e.g. Civilization IV).
It is very easy to teach to non-programmers/designers. It is even easier to pick up for developers since it essentially reads like pseudocode. Being dynamically typed is just one of the aspects that help to get people with little to no prior coding experience up and running fast with the language.
Possible cons:
- The C bindings for python are much more geared towards extending python with C, than embedding python in C.
8.1.5 JavaScript
8.1.6 TypeScript
8.1.7 SCUMM
8.1.8 Mono-script
The Mono framework is faster than most (perhaps all?) of scripting languages out there because it's not interpreted, and because there's a layer between the compiler and the instruction set, it allows you to program in a variety of languages including C# and dialects of Python, Lua and Javascript.
Possible cons:
- If you're doing console development (including iOS), JITing code is apparently out of the question because you can't mark data pages as executable. The IL it has to be pre-compiled to the target platform.
- Mono has license restrictions. You need a commercial license if you want to use it in an environment where the end user is not allowed/able to upgrade the Mono runtime.
8.1.9 AngelScript
8.1.10 Scheme/Guile
With guile you can have your own DSL (Domain Specific Language) just for your game. Once you get used to the parentheses and prefix notation, scheme is heaven to work with.
http://www.gnu.org/software/guile/
libguile
Guile also provides an object library, libguile, that allows other applications to easily incorporate a complete Scheme interpreter.
设计原则:
- 始终定位为一个扩展语言
- Guile使用保守垃圾回收,conservative garbage collection
- it implements the Scheme concept of continuations by copying and reinstating the C stack—but whose practical consequence is that most existing C code can be glued into Guile as is, without needing modifications to cope with strange Scheme execution flows.
- Module system,它使得extensions可以与之前的模块共存
最开始是基于Emacs Lisp作为Emacs扩展语言的巨大成功,GNU Project提出一种希望可以对所有GNU 应用程序都可以实现类似功能的语言
1.5 Supporting Multiple Languages
Since the 2.0 release, Guile’s architecture supports compiling any language to its core virtual machine bytecode, and Scheme is just one of the supported languages. Other supported languages are Emacs Lisp, ECMAScript (commonly known as Javascript) and Brainfuck, and work is under discussion for Lua, Ruby and Python.
This means that users can program applications which use Guile in the language of their choice, rather than having the tastes of the application’s author imposed on them.
2.4 Writing Guile Extensions
You can link Guile into your program and make Scheme available to the users of your program. You can also link your library into Guile and make its functionality available to all users of Guile.
2.5 Using the Guile Module System
Guile has support for dividing a program into modules. By using modules, you can group related code together and manage the composition of complete programs from largely in- dependent parts.
Module之间是怎么通信的?完全独立吗?
3.1.1 Latent Typing
没有办法为一个变量定义类型,以及为一个表达式定义返回类型,所有的变量和表达式都必须在runtime的时候确定,一个变量的名字x只不过表示内存中的一个位置,同时由于变量没有类型,所以可以赋予新的类型的值
3.2.1 Procedures as Values 跟其他变量一样处于同一个空间,所以你甚至可以对一个procedure使用一个不同的名字
5.7 An Overview of Guile Programming
5.7.1.2 Four Steps Required to Add Guile
- First, 在Guile中represent应用程序对象,除非是一些简单的内置数据类型如数字,否则我们需要使用foreign object interface创造对应的Scheme数据类型,这些对象受垃圾回收的管理
- Second编写可以被Guile访问的operations
- Third,在宿主应用程序中需要有一种机制能够调用添加进来的Guile方法
- Finally,在应用程序的top-level,需要做一些结构调整,使得可以初始化Guile的解释器,以及为Scheme定义foreign objects和primitives
5.7.1.3 How to Represent Dia Data in Scheme
- 该表述必须能够被原始语言decodable,因为原生语言需要获取数据
- The representation must also cope with Scheme code holding on to the value for later use.
- 内存数据同时被C和Scheme访问,不能只是简单地使用垃圾回收机制
One resolution of these issues is for the Scheme-level representation of a shape to be a new, Scheme-specific C structure wrapped up as a foreign object. The foreign object is what is passed into and out of Scheme code, and the Scheme-specific C structure inside the foreign object points to Dia’s underlying C structure so that the code for primitives like square? can get at it.
9 Guile Implementation
8.1.11 ActionScript
This is a hybrid dynamic/static typed language used to create Flash games, which can be widely distributed on the web. It is fairly well supported with libraries like Flixel, FlashPunk and Box2d.
8.1.12 mruby
8.2 Erlang
Erlang 算不上冷门,至少你还知道名字,很多你连名字都没听过的才算冷门。(但是很多冷门的设计理念却非常先进)
Erlang 在高并发方面有优势这个说法,其实非常片面。Erlang 最牛逼的地方是它是目前唯一一个具备软实时(Software Realtime)级别的系统。Java 模仿不了,Go 模仿不了。当然如果你要用 C/Rust 之类来做是可以的,但是其实就是把 Erlang 再做一遍而已。
这个软实时指的是垃圾回收性能平稳。如果做语音类应用,需要网络传输过程不会因为 GC 回收导致延迟抖动,Erlang 是你的开箱即用的最佳选择,没有之一。
“听起来也没多牛逼。不就是 GC 技术的优化嘛。我搞个并发式 GC 算法不就行了?“——说这话的,只能说第一并不了解 GC,第二也根本不知道 Erlang 的恐怖之处。只能说朋友,你对力量一无所知。这里不想展开八百字复读机式介绍。自己可以看看 Erlang VM 的设计介绍。你会明白为什么 Erlang 里的 GC 才是真正完全并行,绝无 Stop the World 可能,而且回收延迟柔性可预测的。这一切不是没有代价的,代价就是变量必须绝不能被共享,而且不能被修改。这一来 Java 之类的 C 家族语言还玩个啥,凉了。
另外一些回答里,看了一圈,其实很多也只是随便用了一下试试。说几个点:
1、Erlang 是官方自带一套静态类型分析系统的——dialyzer,你不需要完全标注所有类型,未标注的可以自动推导;官方建议你在所有项目里都默认使用它来检查项目,如果你遵循这个建议,那么你还能享受自动生成文档的好处;而且官方标准库里也都写了类型。
为什么 Erlang 没有把静态类型分析作为吹的点?
因为静态类型系统(编译期检查)其实有其局限性,特别是分布式系统下,两个系统 A 和 B,假设某数据类型做了升级,那么实际系统升级里,会出现 A 升级了,B 还处于旧版本的情况。这个时候还有个屁的类型一致。所以依赖于静态类型分析保重系统一致,只能对于单个非分布式系统比较好。对于真实的分布式系统,设计出发点根本不是类型一致。而是即使不一致,也要能容忍。这就是另外一个话题了。
额外提一句,Erlang 的类型系统是在不允许你自己定义新类型的基础上,却能够完美的满足你的类型要求的设计。说真的,没有人和我提过这一点,但是当有一天我突然意识到的时候,那一瞬间是极其震惊的……(想想 Haskell)
2、Erlang 自带源代码变换系统,这玩意儿用人话说就是,你可以对你自己的源代码进行变换。比如 Erlang 官方自己的 EUnit 库,它是一个单元测试库。它的原理是什么?实际上就是当你引用 EUnit 的时候,就会导致你的当前模块增加一个 parse_transform 标记。然后编译期就知道这个模块需要被外部重写。最终实际上是交给 eunit_autoexport 模块来处理。
这个机制不是特权。你自己也可以用。但是这个 feature 确实比较高级,比较少有人讨论。
前端工程师熟悉的 Babel 其实做的就是这件事。只不过差别在于,Erlang 直接把这个做到了内部而已。而且非常简洁。大部分时候都用不到这个。当时当你有那么一两个 feature 真的需要用牛刀的时候,你一定会发出卧槽太爽了的评价。
3、Erlang 的模块系统是我见过最人性化的,简单到小学生都能明白。你不需要 import 任何模块。你想使用,就直接使用。Erlang 会为你自动寻找并加载。朋友们,其他语言头部那一堆 import 怎么说呢,真的是脱裤子放屁的存在。因为 Erlang 的语法保证了,能够简单的扫描当前文件就能推导出到底使用了哪些模块。
模块可以在不停止系统的情况下安全的热升级。是的,热升级其实 Python、JavaScript 之类的用点 Hack 小技巧,也能模仿个七八分。问题是没有一个敢说“安全”。因为 Erlang 的模块热升级是多版本并存的。假设一个进程真正跑,它使用的是老版本模块。那么升级的时候,新进程会使用新版本。互不干扰。
即使新版本带来了新问题,你还可以无缝的降回去。当然,你愿意,也可以把老的进程干掉一些,直接强制到新版本。其他系统这么做实在太可怕。可是 Erlang 的进程是容错的,状态可恢复而且可升级的,所以这么做还是可行。
模块热更,只是应对一些局部小修改。如果模块间有复杂依赖,需要一次进行多个模块热更怎么办?放心吧。Erlang 有完整的方案。
4、其他语言里,程序基本上就是,一个主入口,然后调用其他第三方模块这样的设计。但是这个设计太简陋。Erlang 的设计是,整个系统是由一系列独立运行的 Application 组成的。没错,其实你只是在为 Erlang 这个系统里开发 Application。包括俗话说的“系统标准库”这种玩意儿,Erlang 里也是独立的 Application。
有何区别?每个 Application 都有自己的一个启动过程,自己的一组进程(构成监督树,具备独立的容错性)。相互之间运行时耦合是松散的。所以,A 和 B 两个 Application 你想运行在同一台计算机,或者多台不同的计算机上,代码有差别吗?没有。
你感觉到一丝奇怪的气味没。是的,Erlang 甚至有自己的 Shell 用来管理和控制这整个系统。而这个 Shell 里就是 Erlang 语言本身。完美的一致,简直是操作系统一样。
顺带一提,Erlang 是可以写脚本的,叫做 escript。原汁原味,保证鲜美。
5、一般语言的字符串处理,感觉很方便。但是很多语言内部是只能处理 Unicode 的某一种编码的(UTF-8、UTF-16BE 是流行选择)。如果想要随心所欲的去支持,就必须把字符串当作原始二进制数据处理。但是 Erlang 里根本没有这个问题。
这个展开说比较复杂。很多人抱怨 Erlang 里字符串处理好像不方便。一个重要的原因是,这部分的理解需要稍微深一点的基础知识(不复杂)。以后再展开说
6、Erlang 里面直接包含了几种设计模式。而且只需要这几种设计模式。是的,比如 Erlang 里是自带状态机模式的。说到这里……
8.2.1 Beam VM
大家都知道erlang要解决的问题是“高并发”和”分布式“问题,这样说有点太抽象。
具体来说,erlang在应用层和操作系统层之间又加入了一个细粒度的计算资源分配层(beam vm),这个分配层自动把计算任务分派到os(thread)层。这其实是高并发处理中一个很理想的环境,计算资源可以更合理的配置。理论上可以做到动态扩大或者缩小所需的硬件计算资源。
有了细粒度的自动计算资源分配,很多时候就不需要在应用层去考虑这个问题了,减少了很多无谓的工作。
这不正是未来所需要的计算模式吗?
8.4.2 Concurrency Oriented Languages
8.4.2.1 Programming by observing the real world
We oden want to write programs that model the world or interact with the world. Writing such a program in a COPL is easy. Firstly, we perform an analysis which is a three-step process:
- We identify all the truly concurrent activities in our real world activ- ity.
- We identify all message channels between the concurrent activities.
- We write down all the messages which can flow on the dicerent message channels.
Now we write the program. The structure of the program should exactly follow the structure of the problem. Each real world concurrent activity should be mapped onto exactly one concurrent process in our programming language. If there is a 1:1 mapping of the problem onto the program we say that the program is isomorphic to the problem.
It is extremely important that the mapping is exactly 1:1. The reason for this is that it minimizes the conceptual gap between the problem and the solution. If this mapping is not 1:1 the program will quickly degenerate, and become diecult to understand. This degeneration is oden observed when non-CO languages are used to solve concurrent problems. Oden the only way to get the program to work is to force several independent activities to be controlled by the same language thread or process. This leads to a inevitable loss of clarity, and makes the programs subject to complex and irreproducible interference errors.
In performing our analysis of the problem we must choose an appro- priate granularity for our model. For example, if we were writing an instant messaging system, we might choose to use one process per user and not one process for every atom in the user’s body.
8.4.2.2 Characteristics of a COPL
COPLs are characterised by the following six properties:
- COPLs must support processes. A process can be thought of as a self-contained virtual machine.
- Several processes operating on the same machine must be strongly isolated. A fault in one processe should not adversely ecect another process, unless such interaction is explicitly programmed.
- Each process must be identified by a unique unforgeable identifier. We will call this the Pid of the process.
- There should be no shared state between processes. Processes inter- act by sending messages. If you know the Pid of a process then you can send a message to the process.
- Message passing is assumed to be unreliable with no guarantee of delivery.
- It should be possible for one process to detect failure in another process. We should also know the reason for failure.
8.4.2.3 Process isolation*
The notion of isolation is central to understanding COP, and to the con- struction of fault-tolerant sodware. Two processes operating on the same machine must be as independent as if they ran on physically separated machines.
Isolation has several consequences:
- Processes have “share nothing” semantics. This is obvious since they are imagined to run on physically separated machines.
- Message passing is the only way to pass data between processes. Again since nothing is shared this is the only means possible to exchange data.
- Isolation implies that message passing is asynchronous. If process communication is synchronous then a sodware error in the receiver of a message could indefinitely block the sender of the message destroying the property of isolation.
- Since nothing is shared, everything necessary to perform a dis- tributed computation must be copied. Since nothing is shared, and the only way to communicate between processes is by message pass- ing, then we will never know if our messages arrive (remember we said that message passing is inherently unreliable.) The only way to know if a message has been correctly sent is to send a confirmation message back.
8.4.2.4 Names of processes
We require that the names of processes are unforgeable. This means that it should be impossible to guess the name of a process, and thereby interact with that process. We will assume that processes know their own names, and that processes which create other processes know the names of the processes which they have created. In other words, a parent process knows the names of its children.
In order to write COPLs we will need mechanisms for finding out the names of the processes involved. Remember, if we know the name of a process, we can send a message to that process.
System security is intimately connected with the idea of knowing the name of a process. If we do not know the name of a process we cannot interact with it in any way, thus the system is secure. Once the names of processes become widely know the system becomes less secure. We call the process of revealing names to other processes in a controlled manner the name distribution problem— the key to security lies in the name distribu- tion problem. When we reveal a Pid to another process we will say that we have published the name of the process. If a name is never published there are no security problems.
Thus knowing the name of a process is the key element of security. Since names are unforgeable the system is secure only if we can limit the knowledge of the names of the processes to trusted processes. In many primitive religions it was believed that humans had powers over spirits if they could command them by their real names. Knowing the real name of a spirit gave you power over the spirit, and using this name you could command the spirit to do various things for you. COPLs use the same idea.
8.4.2.5 Message passing
Message passing obeys the following rules:
- Message passing is assumed to be atomic which means that a mes- sage is either delivered in its entirety or not at all.
- Message passing between a pair of processes is assumed to be or- dered meaning that if a sequence of messages is sent and received between any pair of processes then the messages will be received in the same order they were sent.
- Messages should not contain pointers to data structures contained within processes—they should only contain constants and/or Pids.
8.4.2.6 Protocols*
Isolation of components, and message passing between components, is architecturally suecient for protecting a system from the consequences of a sodware error, but it is not suecient to specify the behaviour of a system, nor, in the event of some kind of failure to determine which component has failed.
Up to now we have assumed that failure is a property of a single component, a single component will either do what it is supposed to do or fail as soon as possible. It might happen, however, that no components are observed to fail, and yet the system still does not work as expected.
To complete our programming model, we add therefore one more thing. Not only do we need completely isolated components that com- municate only by message passing, but also we need to specify the com- munication protocols that are used between each pair of components that communicate with each other.
By specifying the communication protocol that should be obeyed be- tween two components we can easily find out if either of the components involved has violated the protocol. Guaranteeing that the protocol is en- forced should be done by static analysis, if possible, or failing this by compiling run-time checks into the code.
8.3 Move
Move,asafeandflexibleprogramminglanguagefortheLibraBlockchain[1][2]. Move is an executable bytecode language used to implement custom transactions and smart contracts. The key feature of Move is the ability to define custom resource types with semantics inspired by linear logic: a resource can never be copied or implicitly discarded, only moved between program storage locations. These safety guarantees are enforced statically by Move’s type system. Despite these special protections, resources are ordinary program values — they can be stored in data structures, passed as arguments to procedures, and so on. First-class resources are a very general concept that programmers can use not only to implement safe digital assets but also to write correct business logic for wrapping assets and enforcing access control policies. The safety and expressivity of Move have enabled us to implement significant parts of the Libra protocol in Move, including Libra coin, transaction processing, and validator management.
8.3.1 问题
目前的语言存在几个问题:
- Indirect representation of assets:资源仅仅被编码为一个整数,但是一个整数跟一个资源还是 有差异的,将资源表述为一个整数使很容易编写出容易出错的程序,资源需要被特殊对待
- Scarcity is not extensible: In addition, the scarcity protections are hardcoded directly in the language semantics. A programmer that wishes to create a custom asset must carefully reimplement scarcity with no support from the language.
- Access control is not flexible: The only access control policy the model enforces is the signature scheme based on the public key. Like the scarcity protections, the access control policy is deeply embedded in the language semantics. It is not obvious how to extend the language to allow programmers to define custom access control policies.
8.3.2 Move Design Goals
First-Class Resources :Blockchain systems let users write programs that directly interact with digital assets. As we discussed in Section 2.2, digital assets have special characteristics that distinguish them from the values tradi- tionally used in programming, such as booleans, integers, and strings. A robust and elegant approach to programming with assets requires a representation that preserves these characteristics.
The key feature of Move is the ability to define custom resource types with semantics inspired by linear logic [3]: a resource can never be copied or implicitly discarded, only moved between program storage locations. These safety guarantees are enforced statically by Move’s type system. Despite these special protections, resources are ordinary program values — they can be stored in data structures, passed as arguments to procedures, and so on. First-class resources are a very general concept that programmers can use not only to implement safe digital assets but also to write correct business logic for wrapping assets and enforcing access control policies.
Flexibility:modules/resources/procedures,每个交易包含一个Script,这个script可以调用任意module中的procedure,提供巨大的灵活性
Safety: resource safety, type safety, memory safety, Move在运行时(on-chain)动态分析
Verifiability:全部在运行时做验证会带来计算复杂度和协议的复杂度,所以结合off-chain + on-chain的验证,使on-chain尽可能轻量并且尽可能聚焦核心的安全属性上
We have made several design decisions that make Move more amenable to static verification than most general-purpose languages:
- No dynamic dispatch. The target of each call site can be statically determined. This makes it easy for verification tools to reason precisely about the effects of a procedure call without performing a complex call graph construction analysis.
- Limited mutability. Every mutation to a Move value occurs through a reference. References are temporary values that must be created and destroyed within the confines of a single transac- tion script. Move’s bytecode verifier uses a “borrow checking” scheme similar to Rust to ensure that at most one mutable reference to a value exists at any point in time. In addition, the language ensures that global storage is always a tree instead of an arbitrary graph. This allows verification tools to modularize reasoning about the effects of a write operation.
- Modularity. Move modules enforce data abstraction and localize critical operations on re- sources. The encapsulation enabled by a module combined with the protections enforced by the Move type system ensures that the properties established for a module’s types cannot be violated by code outside the module. We expect this design to enable exhaustive functional ver- ification of important module invariants by looking at a module in isolation without considering its clients.
8.3.3 Move Overview
8.3.3.1 Peer-to-Peer Payment Transaction Script
We use the term resource safety to describe the guarantees that Move resources can never be copied, reused, or lost. These guarantees are quite powerful because Move programmers can implement custom resources that also enjoy these protections.
8.3.3.2 Module
8.3.4 The Move Language
8.4 Smalltalk
8.4.1 Object Model
8.4.2.1 Message
To describe how the objects are represented, the programmer must list all the fields in the object, and give each field a name. To describe how the object will behave, the programmer will give a series of “methods”.
A method is like a function, except that it is applied to a specific object. We also say that the method is “invoked” on an object or “sent to” an object. The object in question is called the “receiver.” Every method is invoked on a receiving object. In C++ and Java, the receiver is called the “this object”, but Smalltalk does not use this this terminology. The “this” terminology makes for awkward wordings.
Methods in Smalltalk are similar to methods in Java and C++, where they are called “member functions”. Methods may take arguments and may return a result. The method body is a sequence of executable statements. Methods are invoked from expressions, just as in other languages.
There is an important distinction between “methods” and “messages”. A method is a body of code, while a message is something that is sent. A method is similar to a function; in this analogy, sending a message is similar to calling a function. An expression which invokes a method is called a “message sending expression.”
Smalltalk terminology makes a clear distinction between “message” and “method”, but Java and C++ terminology sometimes confuses these concepts. A message-sending expression will send a message to the object. How the object responds to the message depends on the class of the object. Objects of different classes will respond to the same message differently, since they will invoke different methods.
When a message is sent to an object, a method will be selected and executed. Since we cannot know, in general, the class of the object until run-time, the method cannot be selected until the message is actually sent. This is called “dynamic binding”, and Java, C++, and Smalltalk all have it. With straight functions, the compiler can look at a “call” statement and figure out at compile-time (i.e., “statically”) which body of code to branch to. C++ (which always prefers efficiency over clarity) encourages static binding and refers to dynamically bound methods as “virtual” methods, and refers to the virtual table.
In the Smalltalk programming model, all binding is dynamic. However, the compiler and virtual machine will often bind methods statically for greater execution efficiency when it is can be done safely and without changing the program’s behavior.
8.4.2.2 Message Sending Syntax
Unary Messages
x reset "a message-send in Smalltalk"
x.reset() // a message-send in Java
myDept manager name last
myDept.manager().name().last()
Binary Messages
x + y "in Smalltalk"
x + y // in Java
x.plus(y) //java
包括+ * <= == <===>
Keyword Messages
x addKey: a value: b useMap: myMap ifError: errCode
The message name is “addKey:value:useMap:ifError:” Four colons mean four arguments.
8.4.2.3 Discussion of Smalltalk Syntax
These rules are unfamiliar at first, and some readers are probably thinking “this is very different”. The key is that Smalltalk syntax is very simple. In practice, the syntax is learned quickly and becomes second nature in no time.
Compared to Java or C++ syntax, Smalltalk syntax is simpler and cleaner. Technically, Smalltalk is LL(1), which means it can be parsed with the simplest top-down parsing algorithms, while C++ is LR(1) and cannot be parsed with any simple algorithms. What is hard for computers to parse is also hard for programmers to parse.
Smalltalk的方式更利于动态binding,包括:
- 在x + y 中不需要向后看直接就可以推导需要使用的method
- 在方法调用中,如x.processString (y, m, s, d),每个参数都有名字,形成包含信息更多的函数名称processString:mapping:symbols:defaults:,这避免了运行时对函数的查找
相反,在传统的C++/Java中,为了方便编译器推导类型,需要构建语法树,以及各种表,这导致动态绑定或者推导的能力下降。因为Smalltalk是完全无类型的,不像Java/C++每个变量都必须声明一个类型。
One might reasonably ask, why bother to declare variables at all, if there is no typing information? The primary answer is that every variable must be declared so that the compiler can set aside space for each variable. Every variable will be allocated 32 bits and can hold either a pointer to an object or a SmallInteger.
A second reason for declaring variables is so that the compiler can guard against misspellings of variable names by the programmer. Every variable must be declared. If, in the body of executable statements, the programmer misspells a variable name, the compiler will complain that the variable has not been declared.
8.4.2.4 The Distinction Between Types and Classes
Languages like Java and C++ make a distinction between “types” and “classes”. In Java, there are 3 kinds of types: classes, interfaces, and primitive types (like “int”). Each variable is given a type at compile-time; this places restrictions on what values can be assigned to that variable at run-time.
In Smalltalk there are no constraints on what can be assigned to a variable. Any variable may point to any class of object. It is the programmer’s responsibility to make sure that a variable’s value is of the correct class at run-time.
Which is better: a typed language or an un-typed language? Both approaches have their strengths and weaknesses. In my opinion, neither approach is clearly superior.
If a type system is well-designed, then it is often the case that the compiler can catch bugs that would otherwise go unnoticed until run-time. In this way, typed languages make programs more reliable and readable. On the other hand, a strong type system occasionally makes it difficult to do certain things. The programmer ends up writing code to defeat or work around the language’s type system. It sometimes seems that type system is a burden to the programmer, providing only a false sense of protection.
With an un-typed language, the program is not cluttered up with type definitions and casting expressions. The algorithm tends to show through more clearly. However, when reading complex code, it can sometimes be virtually impossible to guess what kinds of data a given variable might point to at some point in the code.
Dynamic Typing
Sometimes, un-typed languages like Smalltalk are said to be “dynamically type,” since each value has a type, but the compiler does not check the types. Languages like Java and C++ are said to be “statically typed.” In a statically type language, the compiler checks to make sure every line of the program is type-correct. At runtime, there is no checking and, in theory, the program will run faster. In practice, Smalltalk pays only a very small penalty for dynamic type checking.
In a dynamically typed language, each value knows its type and these types are checked at run-time rather than at compile time. By “each value knows its type” we mean that each object has an implicit pointer to its class. This is part of the object and you can’t have an object without having immediate access to its class. Even with SmallIntegers, there is a tag bit that implicitly gives the class of the object as “SmallInteger”. Contrast this with C++, where you can have a 32-bit quantity without knowing whether it represents an “int”, or a pointer, or a “float”.
The term “dynamic typing” is somewhat confusing and should be avoided, since it confuses the ideas of “class” and “type”. Classes are not types. Sure, Smalltalk keeps class information around at run-time and relies on it, but so do “statically-typed” languages like Java and C++.
Smalltalk is an “untyped, object-oriented” language while Java is a “strongly typed, object-oriented language”. C++, as always, defies any simple description.
8.4.2 Smalltalk面向对象
作者:林建入 链接:https://www.zhihu.com/question/20275578/answer/26970925 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Smalltalk 的亮点就在于,它在语言层面引入了一种称为“对象”的高级动态模块系统。一个 Smalltalk 程序由一系列的高级动态模块构成,每个模块之间通过通信进行协同。
也就是说,Smalltalk 所秉承的面向对象思想使得整个软件系统的可分割性和可组合性迈上了一个新台阶。这是面向对象思想的光辉所在。
现在我们回过头来看看 C++ 和 Java 中的面向对象。
事实上,C++ 和 Java 在实现面向对象的路途上遇到的第一道坎是他们本身都是静态类型的语言。也就是说,这类语言的设计信条是一切结构皆须预先描述,因为编译器要检查。于是没什么悬念的的就走上了 Class-based OOP 这条路(另一条路是 Prototype-based OOP)。
Class-based OOP 的一个特征是对象的结构需要预先声明,并且在运行过程中不允许改变—— C++ 和 Java 的作者有一千个理由这么干,最基本的原因就是性能考虑——但这样做的代价首先就削弱了系统的动态性。
更糟糕的是,C++ 和 Java 中,连对象的可替换性也需要预先声明。我这么说一部分朋友可能没办法马上反应过来。其实就是说,在 Smalltalk 中,我们可以用任何一个对象随意替换掉另外一个,只要他们对外界而言行为一致,那么系统依然可以正常运行,这一点,在大家更熟悉的 Ruby、Javascript 等语言中,被称为 Duck-Type 概念。
在 C++ 和 Java 中,你不能随意找个对象 x 来替换掉另外一个对象 y。即使他们拥有完全相同的行为也不行。因为 C++ 和 Java 是 Class-based OOP 所以连可替换性也需要预先声明!这种声明方式就是让无数人潸然泪下的——继承!
即使一个对象 x 和 y 的行为是完全一样的,你也不能用 x 去替换 y。允许你替换的唯一前提是,x 被声明为继承自 y 的。
在有空的时候我们可以再详细讨论一下继承。但是在这里,简单的来说,“继承”是一人分饰两角的典型——它既作为代码复用的一种手段,同时又成为了可替换性的一种声明。这种设计非常失败,难以使用到直接导致了面向对象在 C++ 和 Java 中成为了一个阉割后的太监。
为了弥补继承的这种缺陷,于是引入了 Interface (只表明可替换性,不复用代码),但这也改变不了什么了。毕竟 Interface 竟然也开始互相玩起了继承的游戏……
于是最后,我们看到,尽管 C++ 和 Java 一直声称自己是面向对象的,但是和 Smalltakl 之类的语言一比,这种面向对象的实现几乎是个去势后的太监,他们敢自称为男人真是个笑话。
所以,如果可以说得直白一些的话,C++ 本质上只能算是一个带有少量面向对象支持的 C,而 Java 更像是一个去掉了指针,带上了垃圾回收的 C++。
但再怎么说,面向对象这回事,在 C++ 和 Java 之类的语言里简直都只能算个点缀(可怕的是这个点缀会花掉你 70% 的学习时间)。
对于面向对象。在结构层次,对象之所以高级,是因为它具有动态性。它是在程序运行中动态构造(可以构造一个,也可以构造一百个),动态销毁的;在抽象层次,对象之所以高级,是因为它具有隔离性。它并不直接依赖于另一个对象,而是通过通信来与之协作的。另外,对象的可替换性也是系统弹性的关键。
当然我们都知道,实现上述特性在目前的编译技术条件下,很难保证高性能。所以这就是为什么 C++/Java 之类的语言要自我阉割的原因。这里面不得不说确实是透着一丝无奈。
8.5 Verse
9. 拟娲哲学
9.1 元宇宙的社会价值是什么?
在虚拟世界,价值由两部分组成:
一种是通过视觉、音效等给你带来即时的快乐;另一种是通过作品承载的故事、对世界的理解、个人的生活经验、知识等信息带给个人的精神力量,这种力量不能单纯比做知识,它更多是丰富我们的精神世界,但是这种丰富可以通过给我某些意识从而使我们在工作中创造更大价值,例如它让我们更加积极、勇敢等
虚拟世界价值的产生:
创造的过程和结果都产生价值,创造过程产生的价值相对于创作者自身,参见威廉莫里斯论著,当然除了创作的过程本身,创作的价值还有一部份来源于别人的认可,比如你创造的是一个完全无意义的人,除非你自己觉得很有意义,否则只能体验到自身对这个创造的体验,但如果你是预期它可以让别人感到快乐,那么这种预期以及实际的反馈会让你感到更大的快乐
在虚拟世界,快乐就是价值
因此,创作的快乐,不仅来源于创作的过程,更来源于作品被其他用户消费和体验的过程,包括反馈,以及改进和再创作
对于创作结果的价值
对应上面的价值
通过数字作品,特别是叙事性视觉艺术作品产生的价值,不光是这种上述的价值本身,她另一个重要的意义在于:表达能力
我们所有的事情一般通过文字形式进行表达,理论上任何概念都可以通过精准的文字进行表述,就像计算机程序一样,任何计算机对一段程序的理解都是一致的,然而人类语言不一样,人类语言的字面描述通常都带有一定的背景信息,同样一段话,不同背景信息的人的理解程度是不一样的,并且这种背景信息有时候不一定是逻辑上的知识,还有文化、艺术、生活经历等复杂因素,因此导致的结果就是,比如:
我告诉你要变得勇敢,这句话字面意思很清晰,但是关于勇敢是什么,他可能有很多解释,到底要做到什么才算勇敢,没有定义
但是我给你看了一部《指环王》或者《霍比特人》,你马上就能获得很多精神上的理解,这里面不光是电影本身包含了更多信息,他还包含了很多视觉语言、以及融入你在看这些诗句内容和故事时产生的自我想象力,等等,这些都是非字面的信息所能表达的
一个作品融入的不光是创作者的经验知识,还有很多逻辑,表达手法等等很复杂的因素
所以这就是创作,它是一种表达形式,它的表达能力超越文字的字面意思,这也就是艺术创作这种事物的价值所在
交流和社交产生价值
9.2 RealityIS的本质是什么?
RealityIS的设计过程是从上至下的,即看到上面应用层的开放问题,然后找到问题的根源是编程语言的限制,然后再深入到编程语言以及计算机体系结构的机制,最后得出解决方案。
这跟一般的软件架构过程很类似,由业务层的领域需求,来引导软件架构的设计,只不过这里的“软件架构”深入到了编程语言这一层。然而传统的软件架构是解决特定问题,因此必然导致泛化性不足。
但是,当我们得到这套技术架构之后,再反向向上理解的时候,却发现它具有很大的通用和泛华能力,这一部分原因可能是因为我们的“软件架构”发生在语言这一较低的层次,并且没有改变语言本身的机理。
但是另一方面,也由于我们在设计过程中比较注重对数据的理解,当然这里也有如数据驱动、高性能计算、高度并发等技术需求所引向对数据的关注,也有刻意迭代地加深对数据本质的思考和理解。
所以当我们回过头来,对数据有了更深刻的理解和认知之后,会发现,从根源上,RealityIS的这些泛化性能力,来源于将整个程序开发和执行的机制,从传统以硬件处理器为核心的编译架构,转变为了更符合实际物理世界直觉的机制,这是一个根本性转变。
最终,整个RealityIS的能力和思维,都可以理解为是基于数据的编程模型。包括如解耦、并发、泛型、自我进化式的标准机制等等,这些本质上都是以数据为中心去思考才能形成的结果。
所以,它有一种偶然,也有必然;偶然的是我们关注到数据这个中心问题,必然的是数据为中心的概念是一套能够以真实世界类似的机制进行作业的规则。
将来,我们还会继续完善这一概念,最终,RealityIS将变为一个以真实世界的直觉和真实世界的运作方式类似的机制进行整个程序的构建和运行,这将是一种全新的计算架构。
这有点像深度学习,它的很多理念来自于对大脑机制的思考,虽然神经元的机制并不一定是大脑实际运行的机制(实际当然要复杂得多),但是它可能至少是其中核心的一部分,或者说这种思考抓住了一定的本质,所以最终基于神经元这种简单的结构构建的深度学习模型能够在较大程度上模拟大脑的机制。
9.3 标准及自我进化
一个不能自我进化的Metaverse就是一个游戏,这显然不是Metaverse的形态。此外,即便我们解决了多程序交互的问题,它只是增加了一个游戏内的系统会更加丰富。然而对于一个好的世界,这种丰富不仅仅是指数量上越来越多,而且需要在丰富上形成层次,甚至对于社会的运行机制,后者是更重要的,因为用户关注和需要的是有层次的信息,而不是更多海量可能存在大量无意义无价值的信息。然而,仅仅向其中增加程序的能力不能保证这种丰富形成层次。

当一个开发者向其中添加了一个新的程序,怎么能够判断这个程序的价值?并且是要通过用户的视角去评判这个程序的价值?
在真实世界中,社会进化的机制来源于两股力量:
- 少数优秀的人能够创造一些好的东西,这些东西不仅仅是指一个具体的实物,更可能包含一些结构、关系以及社会运作的一些逻辑,这些东西在Reality World就对应标准,标准的数据结构及其数据组合背后反映的是一定深层次的结构、关系和逻辑。
- 这些好的东西会被其他少部分人接触到,不管是地理位置上较近,还是熟人之间介绍等等,这部分机制在现实社会中往往通过广告 进行加强。当这一少部分人使用之后觉得真正有价值的东西,他们会形成推广的力量,通过人与人之间的关系把这个有价值的东西推向更大的人群,如此,那些最有价值的东西被逐步挖掘出来。
上述这两种机制导致的结果:
- 人们会觉得创造东西会有价值,你有机会被更多人使用,从而为更多人创造价值,你的创作也有机会被更多人认可
- 人们会觉得社会越来越进步,幸福感更强,因为你感觉这个社会在进步,你越来越能使用到更好的东西
这种进化最根本的力量来自于社会个人,而不是少数中央机构。所以要实现这样的自我进化,我们一定要有类似的机制来释放个人的这种力量,而不是依靠平台,平台没法做这件事情。
9.4 Reality World中的“市场经济”机制
即市场会决定哪些东西是更有价值的,这是与传统数字经济系统根本性的不同,传统的数字经济都需要由平台实现某种推荐或者排序算法,例如微博的信息,知乎的文章,淘宝的商品,抖音的视频,这就要求基于一定的标签,分类等机制,信息发布者需要去维护这种标签分类。
然而真实世界的经济却不是这样的,我们所有的一切不是由类似国家或中央的官方机构决定的,而是靠人们自己的选择,促进整个世界的运转。
类似真实世界公司之间的销售,产品越好卖的越多,售价也可以随市场调整。
而且这种机制促进作品的不断改进,就是iPhone手机一样,而传统的内容都是一次性发布,缺乏对原产品的改进机会。游戏也一般由于太复杂,发布后不会有大的改进。目前这些数字经济跟真实世界的经济都不一样。

可以认为它们都是“结构化”的经济,而不是市场经济。
真正的市场经济会促使和催生更多的好内容,更多的人参与。而传统的数字经济,都是少数人在参与或获利。
在真实生活中,每个人都在参与经济贡献;而在目前的自媒体时代,只有少数人在参与经济贡献,大部分都是消费者。
这有机会使得整个经济系统的活力更大:传统的数字化经济都是靠阅读量类似不准确的机制,在这种机制下创作者倾向于作弊买量,而不是创作更好的内容。此外,阅读量本身是个不准确的度量,例如用户可能只是打开了页面就关闭了,根本就没有深入了解对应的内容。而这种通过“实际使用”而不是“查看页面”转化而来对产品的经济定义,更容易促进用户进行更好的创作,就像真实世界一样。见4.3节更多描述。
9.5 怎样构建大规模、大并发系统
在未来的开放Metaverse中,整个系统会非常庞大,使得不可能使用单独应用程序的思维和架构来管理这样的系统。在这样的系统中,系统内部的一些子系统时时刻刻都在运行,也时时刻刻都在发生变化,无论是程序还是用户内容都是如此,它也具有高度的并发性、并行性,以及高度的架构复杂度特征。
显然现有的底层计算架构,以及上层的软件建构都无法支撑这样的系统。
要实现这样的大规模、大并发系统,至少需要具有如下特征:
- 多应用互操作
- 动态编译和解释
- 按需加载程序和数据
- 逻辑小组件化
- 抗破坏性
- 数据安全
对于多应用互操作,这不仅是技术的要求,也是这样的系统的价值所在。必须具有独立开发者能够扩展系统的能力,这样的大规模程序才有意义,否则只由某个大公司维护的程序不管在规模上、还是功能丰富性上都是不足以支撑这种需求。当然这么多程序之间的互操作,也还涉及到更加严格的安全控制机制。
由于程序体非常大,以及所有程序都有可能不断更新和变化,因此整个程序必须是动态编译的。系统必须能够随时编译单个组件,而不需要加载其他所有程序。此外,每个源代码或者组件之间,最好还是相互独立的,因为组件之间的引用或导致非常复杂的链接过程,即使维护这样的引用关系也是非常复杂的事情。这也几乎对编程模型进行了限制,例如如果让用户使用面向对象的机制进行开发,几乎必然的结果是导致整个系统很难进行编译和解释。我们必须以某种计算架构级别的机制,使可以既保证开发者开发功能不受限制,同时又能将程序的结构维持一定的独立结构。除此之外,由于动态语言可能的性能问题,它还必须有某些中间抽象来减轻动态语言的性能开销。
仅仅能够独立编译还不够,它们还需要能够按需加载,只加载当前任务需要的程序指令,只初始化当前任务需要使用到的数据。这也意味着所有的逻辑必须尽可能以比较小粒度的结构组织,因为太大的逻辑可能会存在一些浪费:内存中可能会存储大量不会执行到的指令和数据。
当然需要逻辑小组件化的另一个原因是为了并行化,当程序架构非常复杂时,是很难进行并行性和并发优化的,所以必须将逻辑尽可能单元化、独立化才有可能进行统一的调度和分发。并且这种分发不应该是由开发者自己来实现,因为平台没有办法控制开发者,如果开发者没有完成这件事情,将会使得整个程序的执行都受到影响。因此必须是一种平台级的机制来执行这个过程。
由于系统中可能存在着不受控的代码,因此稳定性会是一个重大的问题,一方面是平台要对代码有一定的审核和测试机制,另一方面,对于那些可能会导致系统崩溃的问题,例如由于组件过期导致符号变化而无法初始化变量时,系统要能够识别和舍弃这样的代码,从而保证系统的稳定性。稳定性的很大来源是数据类型问题以及数据指针的数据合法性问题,RealityIS保证所有的数据都是值类型,并且能够检查符号表的匹配度从而杜绝类型的问题,因此避免了破坏性代码的执行。
9.6 函数关系的潜力
传统的分布式系统大多是响应式、异步的,它们单纯是通过消息传递来解耦进程之间的关系,但是同一个消息可能对应着多个响应者,这些响应者之间本身也可能存在依赖关系,因此这些复杂的关系不太容易梳理清楚,因此传统的分布式系统都默认不处理这种顺序,开发者需要自己小心地处理顺序。
然而实际上函数本身就是包含时序性信息的,例如你需要使用某个变量的值,这个变量的值的赋值语句必须限于使用这个变量的方法调用,而这个赋值语句很有可能就是另一个函数调用,那么就可以得出之前的函数调用顺序应该先于后面的函数调用。
当然上述的理论,这里有个巨大的缺陷,函数本身是一个与变量无关的方法,例如我在方法A之前调用了方法B,然后再在方法A之后也调用了方法B,那么A和B之间的顺序实际上是无法通过函数本身推导而出的。
但是如果我们首先确定了变量,并且这些变量在整个程序运行过程中的名字是不变的,所有函数要么以这些变量作为输入,要么作为输出,那么我们是有可能推导出函数之间的关系的。这种关系是基于变量的,而不是函数的,函数确定相关性,但是计算的是针对一个变量,它所关联的函数的顺序。
但通常这样就足够了,毕竟我们要保证的也只是变量的共享和并发问题,而不是要严格保证所有代码(方法)的执行顺序。
9.6.1 谁来控制函数的执行顺序
在传统的程序中,函数执行顺序隐藏于代码中,由程序员开发的时候通过逻辑来设定好函数调用顺序,这样的方式由两个缺点:
- 顺序隐藏于代码中,不利于维护逻辑
- 数据也都是局部于函数而设定的,缺乏全局控制,数据管理也隐藏于局部,不利于全局维护
上述的问题也就导致开发者必须要去了解编程的知识,管理极度复杂,且不利于扩展和维护。
计算图,将数据和函数分离,推导出明确的计算顺序,这个顺序保存在一种图数据结构,运行时根据这个图的结构来控制计算。这带来两个缺点:
- 图通常表现为树形结构,对其节点的调用表现为大量的树的查询操作,尤其实际情况是函数数量非常多,这种运行时的查询成本会非常高。
- 图是一种顺序结构,不利于表达表达并行性,例如如果独立的子图之间采用了相同的组件,理论上它们可以并行执行,但是单纯的图是无法表达这种信息的,所以它无法在节点级别实现SIMD并行计算。
与之相应的是,RealityIS基于函数之间的输入输出关系构建类似的计算图,然后基于这个计算图来确定函数的计算顺序,但与计算图不同的是,它并不是直接保存计算图的结构,而是将这些顺序展平为一个线性的函数数组结构,这避免了运行时的树结构查询。
将图拉平同样意味着计算图必须是有向无环图,图不能是连通的,那样就无法推导一个确定的顺序。
同时RealityIS在单纯表示执行顺序的图结构信息之外,添加了一个额外的信息:
组件ID
传统的计算图只考虑组件类型,并且这种类型信息主要是用来帮助实现Fusion之类的优化操作,而不是用来辅助节点之间的计算顺序。
RealityIS会考虑组件的命名空间,或者ID,并赋予这个ID一个意义:即所有包含相同ID的对象,它们处理该组件的逻辑顺序是一样的。所以开发者在设计一个组件时,除了函数代码本身,它还有一定的逻辑意义,这个是有道理的,现实世界中我们总是对一些执行步骤包含一些逻辑意义,他并不是单纯的执行一些操作,这些操作之间通常有逻辑顺序,这种逻辑顺序恰恰是人类用户管理逻辑的核心,换句话说它就是我们所说的逻辑,而不是具体细节。RealityIS通过这种机制给用户提供一种管理逻辑的方法。更重要的是,这样的逻辑使得可以使用语义来表述一个组件。
基于这的机制和思想,RealityIS的函数执行顺序有一下特点:
- 所有函数的顺序被预计算或者实时计算为一个线性数组,这样运行时只需要遍历数组即可,没有复杂的数据结构查询
- 函数除了代码之外,还包含逻辑意义
- 逻辑意义使得多个对象之间可以并行计算
9.7 赋值改变世界
9.8 变量定义开放的世界
最简单的分布式系统是传递消息,通常是以字符串的形式,这样的机制使得每次函数调用都需要对字符串进行编码和解码。
Erlang使用的信息通信,传输的是原生的Erlang对象,这些对象被封装成闭包的形式,整个上下文都被保存在一个内存中,其中的变量、函数、及其各自对象的作用域信息等。这样的机制避免了编解码,但是为了避免并发需要对数据进行复制,整个数据基本上是可读的。同时,因为这些上下文保存了类型及函数定义信息等,所以调用者与被调用者仍然还是需要被放在一起编译。因此缺乏可交互能力。
RealityIS通过共享符号表,使得可以从公共的地方获得类型信息,因此不需要放在一起编译。
同时通过赋值解耦的机制,将参数传递分开,因此天生去掉了共享内存的读取(通常是由于无序导致的),因此它可以直接传递数据对象,而不需要执行复制操作。整个程序几乎跟非并发的程序执行逻辑一致。
9.9 面向数据编程
根据上面的分析,我们得出好的编程模型的三个特征:
- 数据需要与功能相关联
- 但功能不能与结构相耦合
- 模式匹配可以用来解决上述问题
我们再来进一步分析一下函数和数据在程序中的作用,特别地,从可复用的角度。
从可复用的角度,实际上一个函数仅关心输入数据的类型,不关心任何对于调用者这些数据到底从哪里来。例如对于具有两个输入参数a和b的函数fun(),其输出参数c,它实际运行过程中这些变量的来源可能有三种情况。
- a,b和c来自同一对象
- a,c来自同一对象,b来自另一对象
- a,b和c分别来自不同的对象
对于上述的不同的数据来源,或者说对于调用者的不同数据结构,好的设计是:我不管你们从哪里弄来这些数据,只要你把a,b和c三个变量的地址给我就行。
当然上述的要求通过模式匹配是可以实现的,但是为了满足数据与功能相关联的要求,RealityIS使用了一种非常不同的思路。
想一想:我们所理解的一个对象通常由功能定义的,没有功能就没有数据,没有功能就没有对象。当我们在定义一个对象时,对象中数据和功能的关系通常是很混乱的:有的数据可能压根没被任何方法用到,有些方法可能根本就不需要某些参数,这就出现冗余,不利于管理。
如果要进行管理,是应该根据数据来管理功能呢,还是应该由功能来管理数据,这两种看起来管理起来都很复杂。
另一方面,实际上对于用户,功能属性应该是主要,而对于程序,数据属性更重要。
RealityIS选择的方式是,让每一个组件的数据和功能完全相关联,组件不需要的数据就不需要定义,组件定义的数据必须在函数中被使用,这样就避免了冗余,并且让数据跟功能是完全对应的。
那怎样定义一个实体对象呢,就是根据组件功能进行组合,选择了哪些组件,实体对象就是相应组件对应属性的集合。这样在定义对象的时候,我其实是根据功能来定义对象的,我们根本没有关心其中的数据,而RealityIS的机制保证功能和数据的完全对应而没有冗余的。这避免了ECS的问题:
- 只需要维护功能,而不需要同时管理功能和数据
- 不需要维护和管理功能和数据之间的关系
但除了上面的好处,RealityIS也与之带来了另一个新的问题:多个组件之间复杂的关系导致了一个实体对象同一个参数的多重定义。例如对于Global.Position属性,组件A和B都同时感兴趣,如果将A和B组合为一个对象,就会出现2次Position的定义。
这部分就是CreationScript独特的地方,理解它的核心在于:
- 变量是有符号表定义的
- 而组件只是在引用变量
这就是说,跟传统的编程不一样,RealityIS中一个组件并不会定义任何变量,所有变量都必须在符号表中定义。当一个组件“定义”一个变量是,它实际上是引用了符号表中的某个定义,但这不是个普通的直接引用,因为这个变量并没有事先在其他地方初始化。
所以,CreationScript组件中的属性声明还隐含着一个重大的意义:
- 如果这个对象还没有定义过该变量,那么就按照符号表的定义为该对象定义一个变量
- 如果对象已经存在这个符号,则将变量指向这个变量的内存地址
这种独特的设计,完美地消除了由组件组合带来的冗余,并且保持了数据跟功能的紧密联系。
9.10 面向机器的语言机制
9.10.1 程序的结构由无序变成有序
这是可控软件构造方法最核心的基础和理念,一直以来,计算机编程语言的结构都是以让人们更容易理解软件的构造过程为主,它的核心还是围绕底层的硬件对机器代码的执行机制,或者可以理解为怎样让人更容易地理解机器的执行过程和逻辑。在这样的思路背后,语言单纯变成为一个机器语言的高级抽象,这种抽象保留了机器执行指令的流程和逻辑,而开发者还需要按照机器的这种逻辑去编写和维护代码。
机器和人的思维逻辑是完全不一样的,对于一件事情,人的思维逻辑会把它们拆分成很多易于理解的子流程,会进行一定的规划,识别其中的依赖关系,重要性程度等,并可能会在实施过程中动态调整,换句话说人处理事情时时都要关注全局性,而降低对局部细节的注意力,除非他开始专注去处理这一块事情;机器的逻辑则聚焦于保证把事情做正确,它必须要呈现很清晰的执行流程,为了更精确地描述流程,它一般一件事情做完就紧接着完成另一件事情,原材料一旦收到就要立即进行加工处理,处理完就要开始运输入库等待。这里面就不给程序员规划的空间,当然程序员可以去构建一些更易于全局统筹管理、规划和理解的架构,但是这往往需要付出很大的代价。
可控软件构造方法的思想,就是要在保证与现有编程语言执行机制等价的情况下,也就是要保证图灵完备性,让程序的执行流程可以被更好地规划和控制,使得人们可以使用大脑的机制来对程序的逻辑进行管理。可以认为这是一套构建于现有编程语言上的软件架构,但是那样的实现结果可能将会非常复杂,相反,我们通过深入分析底层函数执行的机制,从软件构造的过程中做出一些调整,从而更简单地实现软件构造的可控制性,使得编程语言原生就是可控的。
这样的软件构造思维在过去是从来没有的,也是跟现有的软件构造方法有着本质区别的,因此我们认为它是继函数式编程和面向对象编程模型之后的第三种软件构造方法。这样的思维转变是非常基础、重要和本质的,可控性将给软件工业带来巨大的影响和全新的未来,尤其是以下三个层面,这些影响也反应在后续的变革因素之中:
- 程序的有序和可控性使得编程语言及其逻辑组织和管理变得更简单,可以预期会有相较于现在指数级增长的开发者会参与到软件工业的生产中,生产力和创新都会有大幅提升。
- 程序新的组织和执行流程,将会对底层芯片设计带来启发,这可以促进硬件的巨大创新。
- 程序的可控性使得程序结构不光是易于人理解的,也是易于机器理解的,这将带来两个方面的突破:一是编译器本身能够更好地识别和组织程序的逻辑,可以帮助程序员管理更多与程序结构相关的繁琐逻辑,使程序员聚焦于业务部分;二是结合深度学习,我们有机会让AI生成一定逻辑的程序。
9.10.2 让系统管理程序结构和数据
前面第2.1节已经讨论最简单编程语言的概念和特性,这里说明怎么通过可控软件构造方法来实现最简单的编程语言,CreationScript。具体来讲,这是通过两个方面来实现的:
- 程序结构的自动管理
- 数据资源的自动管理
由前面的讨论可知,现代编程语言最复杂的部分在于把程序结构的构造和控制完全交给开发人员去处理,编程语言中更多需要关注的概念是关于软件结构的构造,而不仅仅是逻辑算法怎么编写的问题。在RealityIS中我们从两个方面来控制程序的结构:1)我们加强了函数依赖关系的构建,并把这些信息保存起来,这样就能够构造出任何函数组合的执行顺序;2)对于具体的程序逻辑组合,通实体对象来记录程序的功能结构。
通过上述函数依赖关系和实体功能结构的信息,运行时就可以完全动态构造出程序的结构,这样就不需要开发者去关心程序结构的组织,例如继承关系、重载实现、多态函数派发,甚至手动的函数调用和参数传递等等程序结构构造所需要做的一些操作,使得开发者可以将全部精力集中于业务逻辑的开发与实现。
另一个需要程序员进行繁重的处理,并且与逻辑没有太大关系的是数据的管理。从业务逻辑来说,开发者本来只需要关注业务涉及哪些数据,以及不同的数据跟函数之间是如何交互,但实际除了上述任务,开发者花费了更多的时间去管理数据的创建、修改、持久化、删除等,这些占据的精力非常多。RealityIS使得开发者不需要关注数据的管理。
这种特性也是前面我们讨论过的,通过将程序结构由无序转化为有序,程序的结构可以被机器理解,从而可以让机器帮我们完成一些程序构造的事情,使编程语言的机制不再是单纯的面向大脑的理解,而有更多面向机器的机制,实现人和机器的完美配合和互补。